【Linux学习笔记】栈与函数调用惯例
原文地址:http://blog.csdn.net/slvher/article/details/8831885
栈与函数调用惯例(又称调用约定)— 基础篇
记得一年半前参加百度的校招面试时,被问到函数调用惯例的问题。当时只是懂个大概,比如常见函数调用约定类型及对应的参数入栈顺序等。最近看书过程中,重新回顾了这些知识点,对整个调用栈又有了较深入的理解。作为笔记,记录于此。
NOTICE:本文笔记以32位Linux系统为背景,可能与Windows操作系统的底层机制有些小差异(比如进程虚拟空间的布局),但总的来说,原理是相通的。
1. 进程虚拟地址空间
犹记得当年一个困扰了自己很长时间的问题:“我的机器物理内存只有1G,为什么很多资料提到32位系统下,每个进程都拥有4G的地址空间”?更不理解的是“为啥各进程的4G地址空间还相互独立,不会冲突”?对于非计算机科班出身、当时没学过操作系统的学生来说,实在是难以理解这其中的奥妙。后来读到Andrew.S.Tanenbaum教授写的《Modern Operating Systems》一书,才有种被醍醐灌顶、豁然开朗的感觉,原来都是操作系统在背后“作怪”!在此建议对这部分概念有疑问的同学去读经典的操作系统教材,可以少走很多弯路。
进程虚拟空间看似与本文主题无关,其实不然,若不对进程空间建立整体概念,理解函数调用栈容易陷入“只见树木不见森林”的困境。这些都是我自学过程中的体会,因此废话有点多,下面开始切入正题。
Linux系统中,进程的虚拟地址空间典型布局如下图所示。

由上图可知,32位平台中,进程虚拟地址范围为0x00000000-0xFFFFFFFF(共4GB),其中0x00000000-0xBFFFFFFF(共3GB)为用户空间,位于高地址部分的1GB为内核空间,范围为0xC0000000-0xFFFFFFFF。整个进程虚拟地址可分为几个部分,下面从地址从低到高的方向进行说明:
1)保留区
它并不是一个单一的内存区域,而是对地址空间中受到操作系统保护而禁止用户进程访问的地址区域的总称。大多数操作系统中,极小的地址通常都是不允许访问的,如NULL。C语言将无效指针赋值为0也是出于这种考虑,因为0地址上正常情况下不会存放有效的可访问数据。
2)代码和只读数据区
对于所有进程来说,代码都是从同一固定地址开始,如Linux系统通常从0x08048000开始代码段(如前所述,从地址0到代码段起始地址的部分通常为操作系统保留区)。代码及只读数据区是直接按照可执行目标文件的内容初始化的,与目标文件中的代码段(.text)、初始化段(.init)及只读数据段(.rodata)相对应。
3)可读/写数据区
可执行文件中的数据被映射至该区,包括.data和.bss。想进一步理解.data/.bss区别的同学,可查阅其它资料(比如这里),此处略过。
4)堆
代码和数据区往上是运行时堆。与代码/数据段在程序加载时就确定了大小不同,堆可以在运行时动态扩展或收缩。调用如malloc/free、new/delete这样的库函数时,操作的内存区域就在堆中。堆的范围通常较大,如在32位Linux系统中,堆的上限理论值可以达到2.9GB。
5)共享库
该区域用于映射可执行文件用到的动态链接库。在Linux 2.4版本中,若可执行文件依赖共享库,则系统会为这些动态库在从0x40000000开始的地址分配相应空间,并在程序装载时将其载入到该空间。在Linux 2.6内核中,共享库的起始地址被往上移动至更靠近栈区的位置(见下文加粗部分的特别说明)。
6)栈
栈用于维护函数调用的上下文,编译器用栈来实现函数调用。跟堆一样,用户栈在程序运行期间可以动态扩展和收缩。与堆相比,栈通常较小,典型值为数MB。
7)内核空间
内核总是驻留在内存中,是操作系统的一部分。内核空间就是为内核保留的,不允许应用程序读写这个区域的内容或直接调用内核代码定义的函数。32位Linux系统中,默认将高地址的1GB分配为内核空间;而Windows默认将高地址的2GB分配为内核空间,当然,也可以配置为1GB。
需要特别说明的问题:
从进程地址空间的布局可以看到,在有共享库的情况下,留给堆的可用空间还有两处:一处是从.bss段到0x40000000,约不到1GB的空间;另一处是从共享库到栈之间的空间,约不到2GB。这两块空间大小取决于栈、共享库的大小和数量。这样来看,是否应用程序可申请的最大堆空间只有2GB?事实上,这与Linux内核版本有关。在上面给出的进程地址空间经典布局图中,共享库的装载地址为0x40000000,这实际上是Linux kernel 2.6版本之前的情况了,在2.6版本里,共享库的装载地址已经被挪到靠近栈的位置,即位于0xBFxxxxxx附近,因此,此时的堆范围就不会被共享库分割成2个“碎片”,故kernel 2.6的32位Linux系统中,malloc申请的最大内存理论值在2.9GB左右。
2. IA32的通用寄存器组
函数调用栈的实现与CPU的寄存器组密切相关,因此,有必要做简单介绍。
Intel 32位体系结构(简称IA32)的CPU包含一组通用寄存器,由8个32-bit寄存器构成,如下图所示。 
在最初的8086中,寄存器是16-bit的,每个都有特殊用途,这些寄存器的名字就是反映这些不同的用途。由于IA32平台采用了平坦寻址模式,其对特殊寄存器的需求大大降低,但由于历史原因,这些寄存器的名称就这样保留下来。在大多数情况下,上图所示的前6个寄存器均可作为通用寄存器使用。之所以说“大多数情况”,是因为有些指令以固定的寄存器作为源寄存器或目的寄存器(如一些特殊的算术操作指令imull/mull/cltd/idivl/divl要求一个参数必须在%eax中,其运算结果存放在%edx(higher 32-bit)和%eax (lower32-bit)中;又如函数返回值通常保存在%eax中)。剩下两个寄存器(%ebp和%esp)在函数栈中起着重要作用,具体内容后面介绍函数栈时会做说明。
对于寄存器%eax, %ebx, %ecx和%edx,各自可被作为2个独立16-bit的寄存器使用,而对于其中的lower 16-bit寄存器,还可以继续分为2个独立8-bit的寄存器使用。编译器会根据操作数的大小选择合适的寄存器来生成汇编码。在汇编语言层面,这组通用寄存器以%e(AT&T syntax)或直接以e(Intel syntax)开头来引用,例如mov $5, %eax或mv eax, 5是指将立即数5赋值给register %eax。关于两种主流assembly在语法上的区别,可参见wikipedia相关词条。本文介绍了两部分基础知识,为理解栈与函数调用惯例做铺垫,正篇内容请见下篇笔记。^_^
=================== EOF ==================
栈与函数调用惯例(又称调用约定)— 正篇
在前篇笔记的基础上,本文继续介绍栈与函数调用约定的相关内容。
1. 函数调用的栈帧结构
IA32程序用栈来实现函数调用。机器用栈来传递函数参数、保存返回地址、保存寄存器(即函数调用的上下文)及存储本地局部变量等。为单个函数调用分配的那部分栈称为栈帧(stack frame),栈帧的边界由2个指针界定:寄存器%ebp为帧指针(严谨的说法是,帧指针存放在%ebp中),指向当前栈帧的起始处,通常较固定;寄存器%esp为栈指针,指向当前栈帧的栈顶位置,当程序执行时,栈指针可以移动,因此大多数数据的访问都是相对于帧指针的。
下图给出了栈帧的通用结构。
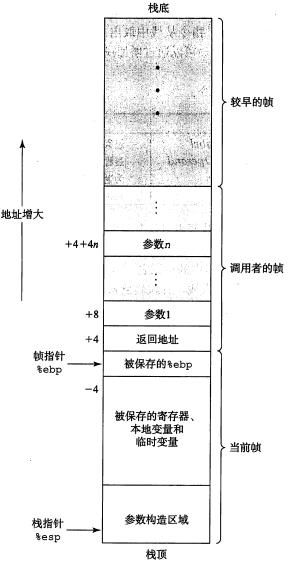
结合前篇笔记介绍的进程虚拟地址空间和上图的栈帧结构,我们可以看到,在经典的操作系统(如各种类UNIX操作系统)中,栈总是向下增长的,压栈(push)时栈顶地址减小,弹栈(pop)时栈顶地址增大。另外还可以注意到,堆通常是向上增长的,但在Windows系统中,大部分堆由HeapCreate()产生,而HeapCreate系列函数却完全不遵照堆向上增长的规律。
下面根据函数调用中典型的栈帧结构,对函数调用栈的实现过程做如下描述:
若函数P(调用者caller)调用函数Q(被调用者,callee),则Q的参数存放在P的栈帧中(在对应的汇编代码中,表现为在跳转至callee startaddress之前,通过push指令将函数Q所需的参数依次压入栈中,压栈顺序与本文主题—函数调用约定有关,具体实现过程大家看到后面的汇编代码就会清楚)。另外,当P调用Q时,P中的返回地址被压入栈中(call指令实现返回地址压栈并跳转至callee入口地址处),形成P的栈帧末尾。返回地址其实就是P中调用Q的指令执行完后下一条将要执行的指令地址。接着,需要保存P的帧指针(用于从Q返回时恢复P的栈帧结构)并将P栈帧当前的栈顶地址值(存放在%esp中,是P的栈帧边界之一)装入帧指针寄存器%ebp,Q的栈帧边界即从该%ebp开始,可见,经过这样的操作流程,当前的%ebp指向的位置既是P栈帧的结束边界,又是Q栈帧的开始边界。接着是保存其它寄存器的值。最后开始真正执行函数Q包含的功能指令。
对上段让人眼晕的关于函数调用栈实现的描述做个总结:
1)将被调用函数的参数压栈(注:在x86_64平台中,CPU拥有16个通用64-bit寄存器,故调用函数时,前6个参数通常由寄存器来传递,剩下的才通过栈传递)
2)将当前指令,即函数调用指令的下一条指令地址作为返回地址压入栈中
3)跳转到函数体执行
其中,第2、3步由call指令来实现。跳转到函数体后,该函数体的开始指令通常是这样的:
1)push %ebp :将调用者的帧指针%ebp压栈,即保存旧栈帧的帧指针以便函数返回时恢复旧栈帧
2)mov %esp, %ebp:将当前栈顶地址传给%ebp,此时,%ebp既是旧栈帧的结束地址,又是被调用者的新栈帧的起始地址
3)sub xxx, %esp:将栈顶下移,即为被调用函数开辟栈空间,xxx为立即数且通常为16的整数倍(这会浪费一些空间,但gcc采用该规则来保证数据的严格对齐)
4)push xxx:该命令为可选项,如有必要,由被调用者负责保存/恢复某些寄存器
不难推导出函数返回时通常由如下指令序列构成:
1)pop xxx:可选项,与进入函数时是否push xxx保存寄存器相对应
2)mov %ebp, %esp:恢复调用者的栈顶指针,即调用者栈帧的结束边界
3)pop %ebp:调用者的帧指针弹栈,即恢复调用者栈帧的起始边界
4)ret:从栈中得到返回地址,并跳转到该位置处继续执行
注意:函数退出前指令序列的第2、3步也可由指令leave来实现,具体用哪种方式,由编译器决定。
上面给出的是函数调用时,典型的进入/退出指令序列,某些情况下,编译器生成的指令序列并不按照上面的方式进行。例如若C函数被声明为static(只在本编译单元内可见)且函数在编译单元内被直接调用,没有被显示或隐式取地址(即没有任何函数指针指向该函数),在这种情况下,编译器确信该函数不会被其它编译单元调用,因此可以随意修改其进/出指令序列以达到优化的目的。
2. 寄存器使用约定
从前面介绍的函数进入/退出指令序列,已经看到,在函数调用过程中,有些寄存器是由被调用者负责保存/恢复的。在正式介绍函数调用惯例之前,有必要先对寄存器使用惯例做个说明。
程序寄存器组是唯一能被所有函数共享的资源,虽然在给定时刻只有一个函数是活动的,但我们必须保证当某个函数(caller)调用另一个函数(callee)时,callee不会覆盖caller稍后会使用到的寄存器值。为此,IA32采用了一套统一的寄存器使用惯例,所以的函数(包括库函数)调用都必须遵守。
根据惯例,寄存器%eax、%edx和%ecx为调用者保存寄存器(caller-saved registers),当函数P调用Q时,Q可以覆盖这些寄存器,而不会破坏任何P所需的数据。寄存器%ebx、%esi和%edi为被调用者保存寄存器(callee-saved registers),即Q在覆盖这些寄存器的值时,必须先把它们保存到栈中,并在返回前恢复它们,因为P可能会用到这些值。此外,根据惯例,必须保持寄存器%ebp和%esp,即函数返回后,这两个寄存器必须恢复到调用前的值,换句话说,必须恢复调用者的栈帧。
只要各函数调用遵守上述惯例,就可以正常工作。
3. 函数调用惯例(calling convention,又称调用约定)
前面介绍的一系列基础知识都是为能彻底搞清楚本节内容,下面开始切入正题。目前,我们已经掌握了函数调用时函数栈的实现原理及寄存器的使用惯例,在这些知识的支撑下,理解函数调用约定变得相当容易。
根据前面的分析我们已知,编译器根据一套简单的惯例来产生栈结构代码。参数在栈上传递给函数,callee可以从栈中用相对于%ebp的正偏移量(+8,+12,…)来访问参数。可以用push指令或栈指针下移(sub一个立即数)为callee分配栈空间。在callee返回前,函数必须将栈恢复到调用前的状态(通过恢复所有的被调用者保存寄存器和%ebp且重置%esp使其指向返回地址来实现)。为保证程序能正确执行,让所有函数调用都遵守一套建立/恢复栈帧的一致惯例非常重要。
一个函数调用惯例一般会规定如下几方面内容:
1)函数参数的传递顺序和方式
函数参数传递方式由多种,最常见的是通过栈传递。caller将参数压入栈中,callee从栈中将参数取出。对于有多个参数的函数,调用惯例要规定caller将参数压栈的顺序(从左至右还是从右至左)。有些调用惯例还允许使用寄存器传参以提高性能。
2)栈的维护方式
在caller将参数压栈后,callee的函数体会被调用,返回时需要将被压栈的参数全部弹出,以便保持栈在函数调用前后的一致。这个弹栈过程可以由caller负责完成,也可由callee负责完成。
3)名字修饰(Name-mangling)策略
为了链接时对调用惯例进行区分,调用惯例要对函数本身的名字做修饰。不同的调用惯例有不同的名字修饰策略。几种主要的函数调用惯例总结如下:

此外,不少编译器还提供一种称为naked call的调用惯例,这种调用惯例特点是编译器不产生任何保存寄存器的代码,故称为naked call,用于一些特殊场合。
对C++而言,以上几种调用惯例的名字修饰策略有所改变,因为C++支撑函数重载、命名空间和成员函数等新语法特征,因此,一个函数名可以对应多个函数定义,上面提到的名字修饰策略显然无法区分各个不同同名函数定义,故C++有一套更加复杂的名字修饰策略。此外,C++还有一种特殊的调用惯例,称为thiscall,专用于类成员函数的调用。其特点随编译器不同而不同,对于gcc,thiscall和cdecl完全一样,只是将this看做函数的第1个参数;而在VC中,this指针存放在%ecx中,参数从右至左压栈。
4. 函数返回值传递
除参数传递外,函数与调用方还可以通过返回值进行交互。对于函数返回值的实现细节,有以下几条原则:
1)对于小于4字节的返回值,调用惯例通常将其存在%eax中,调用方通过读取%eax获取返回值。
2)对于返回值为5-8字节对象的情况,几乎所有的调用约定都采用%eax和%edx联合返回的方式进行,其中%edx保存返回值的高4字节,%eax保存返回值的低4字节。
3)对于超过8字节的返回类型,实现方式稍微复杂,可以总结为:a. 调用者在栈上额外开辟空间并将该空间的一部分作为传递返回值的临时对象,这里称为temp; b. 将temp对象地址作为隐藏参数传递给被调用的函数;c. 被调用函数将待返回数据拷贝给temp对象并将temp对象的地址存入%eax;d. 被调用函数返回后,调用者将%eax指向的temp对象拷贝给接收返回值的对象。
可见,如果返回值类型的size太大,C语言在函数返回时会使用一个临时的栈上内存区域作为中转,结构返回值对象会被拷贝两次。因此,不到万不得已,不要轻易返回size较大的对象,我们可以通过传入相应指针来接收返回值的方法来代替函数直接返回大对象。
此外还要注意,函数传递大size返回值所使用的方法是不可移植的,不同的编译器、不同的平台、不同的调用惯例甚至不同的编译参数都可能采用不同的实现方法。
关于大size返回值的实现细节分析,要涉及到较大篇幅的汇编代码分析,本文不再展开。感兴趣或想深究的同学,建议阅读《程序员的自我修养—链接、装载与库》一书10.2小节的内容。
【参考资料】
1. Computer Systems: A Programmer’sPerspective, 2E. 第3章
2. 程序员的自我修养—链接、装载与库. 第10章
3. http://www.cs.virginia.edu/~evans/cs216/guides/x86.html
================ EOF =================