Kubernetes Scheduler源码分析--启动过程与多队列缓存
源码为k8s v1.6.1版本,github上对应的commit id为b0b7a323cc5a4a2019b2e9520c21c7830b7f708e
本文将对Scheduler的启动过程和Pod的处理过程进行分析,主要分析Pod在各个缓存队列中的流动过程。
一、Schedule中Pod处理的主要流程
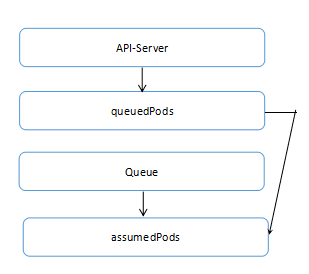
在Kubernetes Scheduler中,对于pod的处理,采用多缓存队列的形式。其中相关的缓存队列包括queuedPods,schedule监听对象中的Queue,ScheduleCache对象中的assumedPods。
其中具体的处理过程为:
(1) 通过监听获取变化的Pod信息,并放入queuePods队列
(2) scheduleOne中获取queuePods中的Pod,进行调度
(3) 调度完成后,将Pod放入assumedPods中
(4) 在processLoop中,取出Pod,刷新assumedPods中Pod的信息
(5) cleanupAssumedPods进行定期检查
二、Schedule启动过程中Pod队列的初始化
(1) 启动流程中,属于固定流程,从main函数跳入对应的New函数中
源代码:kubernetes\plugin\cmd\kube-scheduler\scheduler.go
func main() {
s := options.NewSchedulerServer()
s.AddFlags(pflag.CommandLine)
flag.InitFlags()
logs.InitLogs()
defer logs.FlushLogs()
verflag.PrintAndExitIfRequested()
if err := app.Run(s); err != nil {
glog.Fatalf("scheduler app failed to run: %v", err)
}
}// NewSchedulerServer creates a new SchedulerServer with default parameters
func NewSchedulerServer() *SchedulerServer {
versioned := &v1alpha1.KubeSchedulerConfiguration{}
api.Scheme.Default(versioned)
cfg := componentconfig.KubeSchedulerConfiguration{}
api.Scheme.Convert(versioned, &cfg, nil)
cfg.LeaderElection.LeaderElect = true
s := SchedulerServer{
KubeSchedulerConfiguration: cfg,
}
return &s
}然后进去ScheduleServer的Run函数中:
// Run runs the specified SchedulerServer. This should never exit.
func Run(s *options.SchedulerServer) error {
kubecli, err := createClient(s)
if err != nil {
return fmt.Errorf("unable to create kube client: %v", err)
}
recorder := createRecorder(kubecli, s)
informerFactory := informers.NewSharedInformerFactory(kubecli, 0)
sched, err := createScheduler(
s,
kubecli,
informerFactory.Core().V1().Nodes(),
informerFactory.Core().V1().PersistentVolumes(),
informerFactory.Core().V1().PersistentVolumeClaims(),
informerFactory.Core().V1().ReplicationControllers(),
informerFactory.Extensions().V1beta1().ReplicaSets(),
informerFactory.Apps().V1beta1().StatefulSets(),
informerFactory.Core().V1().Services(),
recorder,
)
if err != nil {
return fmt.Errorf("error creating scheduler: %v", err)
}
go startHTTP(s)
stop := make(chan struct{})
defer close(stop)
informerFactory.Start(stop)
run := func(_ <-chan struct{}) {
sched.Run()
select {}
}
if !s.LeaderElection.LeaderElect {
run(nil)
panic("unreachable")
}
id, err := os.Hostname()
if err != nil {
return fmt.Errorf("unable to get hostname: %v", err)
}
// TODO: enable other lock types
rl := &resourcelock.EndpointsLock{
EndpointsMeta: metav1.ObjectMeta{
Namespace: "kube-system",
Name: "kube-scheduler",
},
Client: kubecli,
LockConfig: resourcelock.ResourceLockConfig{
Identity: id,
EventRecorder: recorder,
},
}
leaderelection.RunOrDie(leaderelection.LeaderElectionConfig{
Lock: rl,
LeaseDuration: s.LeaderElection.LeaseDuration.Duration,
RenewDeadline: s.LeaderElection.RenewDeadline.Duration,
RetryPeriod: s.LeaderElection.RetryPeriod.Duration,
Callbacks: leaderelection.LeaderCallbacks{
OnStartedLeading: run,
OnStoppedLeading: func() {
glog.Fatalf("lost master")
},
},
})
panic("unreachable")
}这里的关键步骤包括:
(1) 初始化了informerFactory对象
// NewSharedInformerFactory constructs a new instance of sharedInformerFactory
func NewSharedInformerFactory(client clientset.Interface, defaultResync time.Duration) SharedInformerFactory {
return &sharedInformerFactory{
client: client,
defaultResync: defaultResync,
informers: make(map[reflect.Type]cache.SharedIndexInformer),
startedInformers: make(map[reflect.Type]bool),
}
}type sharedInformerFactory struct {
client clientset.Interface
lock sync.Mutex
defaultResync time.Duration
informers map[reflect.Type]cache.SharedIndexInformer
// startedInformers is used for tracking which informers have been started.
// This allows Start() to be called multiple times safely.
startedInformers map[reflect.Type]bool
} sched, err := createScheduler(
s,
kubecli,
informerFactory.Core().V1().Nodes(),
informerFactory.Core().V1().PersistentVolumes(),
informerFactory.Core().V1().PersistentVolumeClaims(),
informerFactory.Core().V1().ReplicationControllers(),
informerFactory.Extensions().V1beta1().ReplicaSets(),
informerFactory.Apps().V1beta1().StatefulSets(),
informerFactory.Core().V1().Services(),
recorder,
)// createScheduler encapsulates the entire creation of a runnable scheduler.
func createScheduler(
s *options.SchedulerServer,
kubecli *clientset.Clientset,
nodeInformer coreinformers.NodeInformer,
pvInformer coreinformers.PersistentVolumeInformer,
pvcInformer coreinformers.PersistentVolumeClaimInformer,
replicationControllerInformer coreinformers.ReplicationControllerInformer,
replicaSetInformer extensionsinformers.ReplicaSetInformer,
statefulSetInformer appsinformers.StatefulSetInformer,
serviceInformer coreinformers.ServiceInformer,
recorder record.EventRecorder,
) (*scheduler.Scheduler, error) {
configurator := factory.NewConfigFactory(
s.SchedulerName,
kubecli,
nodeInformer,
pvInformer,
pvcInformer,
replicationControllerInformer,
replicaSetInformer,
statefulSetInformer,
serviceInformer,
s.HardPodAffinitySymmetricWeight,
)
// Rebuild the configurator with a default Create(...) method.
configurator = &schedulerConfigurator{
configurator,
s.PolicyConfigFile,
s.AlgorithmProvider}
return scheduler.NewFromConfigurator(configurator, func(cfg *scheduler.Config) {
cfg.Recorder = recorder
})
}// NewConfigFactory initializes the default implementation of a Configurator To encourage eventual privatization of the struct type, we only
// return the interface.
func NewConfigFactory(
schedulerName string,
client clientset.Interface,
nodeInformer coreinformers.NodeInformer,
pvInformer coreinformers.PersistentVolumeInformer,
pvcInformer coreinformers.PersistentVolumeClaimInformer,
replicationControllerInformer coreinformers.ReplicationControllerInformer,
replicaSetInformer extensionsinformers.ReplicaSetInformer,
statefulSetInformer appsinformers.StatefulSetInformer,
serviceInformer coreinformers.ServiceInformer,
hardPodAffinitySymmetricWeight int,
) scheduler.Configurator {
stopEverything := make(chan struct{})
schedulerCache := schedulercache.New(30*time.Second, stopEverything)
c := &ConfigFactory{
client: client,
podLister: schedulerCache,
podQueue: cache.NewFIFO(cache.MetaNamespaceKeyFunc),
pVLister: pvInformer.Lister(),
pVCLister: pvcInformer.Lister(),
serviceLister: serviceInformer.Lister(),
controllerLister: replicationControllerInformer.Lister(),
replicaSetLister: replicaSetInformer.Lister(),
statefulSetLister: statefulSetInformer.Lister(),
schedulerCache: schedulerCache,
StopEverything: stopEverything,
schedulerName: schedulerName,
hardPodAffinitySymmetricWeight: hardPodAffinitySymmetricWeight,
}
// On add/delete to the scheduled pods, remove from the assumed pods.
// We construct this here instead of in CreateFromKeys because
// ScheduledPodLister is something we provide to plug in functions that
// they may need to call.
var scheduledPodIndexer cache.Indexer
scheduledPodIndexer, c.scheduledPodPopulator = cache.NewIndexerInformer(
c.createAssignedNonTerminatedPodLW(),
&v1.Pod{},
0,
cache.ResourceEventHandlerFuncs{
AddFunc: c.addPodToCache,
UpdateFunc: c.updatePodInCache,
DeleteFunc: c.deletePodFromCache,
},
cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc},
)
c.scheduledPodLister = corelisters.NewPodLister(scheduledPodIndexer)
// Only nodes in the "Ready" condition with status == "True" are schedulable
nodeInformer.Informer().AddEventHandlerWithResyncPeriod(
cache.ResourceEventHandlerFuncs{
AddFunc: c.addNodeToCache,
UpdateFunc: c.updateNodeInCache,
DeleteFunc: c.deleteNodeFromCache,
},
0,
)
c.nodeLister = nodeInformer.Lister()
// TODO(harryz) need to fill all the handlers here and below for equivalence cache
return c
}在NewConfigFactory中,创建了schedulerCache对象,然后再创建了一个podQueue队列(FIFO队列)
func newSchedulerCache(ttl, period time.Duration, stop <-chan struct{}) *schedulerCache {
return &schedulerCache{
ttl: ttl,
period: period,
stop: stop,
nodes: make(map[string]*NodeInfo),
assumedPods: make(map[string]bool),
podStates: make(map[string]*podState),
}
}// NewIndexerInformer returns a Indexer and a controller for populating the index
// while also providing event notifications. You should only used the returned
// Index for Get/List operations; Add/Modify/Deletes will cause the event
// notifications to be faulty.
//
// Parameters:
// * lw is list and watch functions for the source of the resource you want to
// be informed of.
// * objType is an object of the type that you expect to receive.
// * resyncPeriod: if non-zero, will re-list this often (you will get OnUpdate
// calls, even if nothing changed). Otherwise, re-list will be delayed as
// long as possible (until the upstream source closes the watch or times out,
// or you stop the controller).
// * h is the object you want notifications sent to.
//
func NewIndexerInformer(
lw ListerWatcher,
objType runtime.Object,
resyncPeriod time.Duration,
h ResourceEventHandler,
indexers Indexers,
) (Indexer, Controller) {
// This will hold the client state, as we know it.
clientState := NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, indexers)
// This will hold incoming changes. Note how we pass clientState in as a
// KeyLister, that way resync operations will result in the correct set
// of update/delete deltas.
fifo := NewDeltaFIFO(MetaNamespaceKeyFunc, nil, clientState)
cfg := &Config{
Queue: fifo,
ListerWatcher: lw,
ObjectType: objType,
FullResyncPeriod: resyncPeriod,
RetryOnError: false,
Process: func(obj interface{}) error {
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Added, Updated:
if old, exists, err := clientState.Get(d.Object); err == nil && exists {
if err := clientState.Update(d.Object); err != nil {
return err
}
h.OnUpdate(old, d.Object)
} else {
if err := clientState.Add(d.Object); err != nil {
return err
}
h.OnAdd(d.Object)
}
case Deleted:
if err := clientState.Delete(d.Object); err != nil {
return err
}
h.OnDelete(d.Object)
}
}
return nil
},
}
return clientState, New(cfg)
}// Run begins processing items, and will continue until a value is sent down stopCh.
// It's an error to call Run more than once.
// Run blocks; call via go.
func (c *controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
go func() {
<-stopCh
c.config.Queue.Close()
}()
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
c.config.Queue,
c.config.FullResyncPeriod,
)
r.ShouldResync = c.config.ShouldResync
r.clock = c.clock
c.reflectorMutex.Lock()
c.reflector = r
c.reflectorMutex.Unlock()
r.RunUntil(stopCh)
wait.Until(c.processLoop, time.Second, stopCh)
}到这里对Queue的初始化完成。随后会重新回到SchedulerServer的Run函数中,启动go startHTTP(s)
informerFactory.Start(stop)
sched.Run()
select {}
}
// Run begins watching and scheduling. It starts a goroutine and returns immediately.
func (s *Scheduler) Run() {
go wait.Until(s.scheduleOne, 0, s.config.StopEverything)
}(请ScheduleOne的分析参考:Kubernetes Scheduler源码分析--启动过程与多队列缓存(续))