Linux搭建Kafka集群
Linux搭建Kafka集群
1 说明
1.1 编写目的
本文编写旨在介绍Kafka的集群架构配置,了解Kafka的基本使用。
1.2 适用范围
本文适用于对高效率消息中间件及对大数据处理比较有兴趣的童鞋。本文仅介绍了Kafka的基本知识、集群架构,以及Kafka的基本使用。
2 Kafka简介
2.1 什么是kafka
Apache Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka使用Scala编写,是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
其主要设计目标为:
1、以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
2、高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输。
3、支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输。
4、同时支持离线数据处理和实时数据处理。
5、 Scale out:支持在线水平扩展。
2.2 Kafka基本概念
1、Producer:消息生产者,就是向kafka broker发消息的客户端。
2、Consumer:消息消费者,向kafka broker取消息的客户端。
3、Topic:特定类型的消息流,可以理解为一个队列。
4、Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个CG只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
5、Broker:已发布的消息保存在一组服务器中,称之为Kafka集群。一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
6、Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
7、Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
2.3 Kafka架构
2.3.1 集群示意

Kafka集群的业务处理示意如上图所示。生产者发布消息到集群中,消费者订阅某topic,创建消息流。生产者发布到该话题的消息被均衡地分发到这些流中。
2.3.2 整体架构
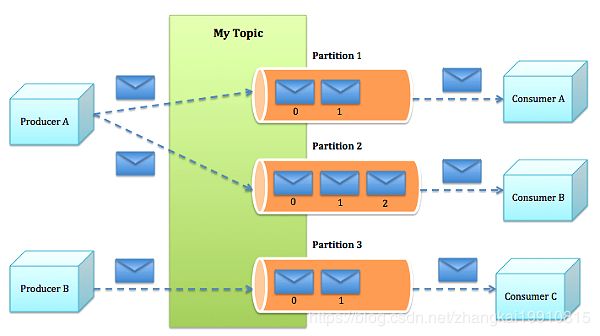
Kafka的整体架构如上图所示,展示了生产者、消费者、Topic、Partition之间的关系和数据传递。因为Kafka内在就是分布式的,一个Kafka集群通常包括多个代理。为了均衡负载,将话题分成多个分区,每个代理存储一或多个分区。多个生产者和消费者能够同时生产和获取消息。
3 配置准备
3.1 服务器准备
一般情况下,Kafka集群至少需要3台机器。本文档就以3台机器作为安装环境进行配置,操作系统以Centos 7为例。
各个节点及描述如下表所示:
| 机器名 | IP |
|---|---|
| node1 | 192.168.204.127 |
| node2 | 192.168.204.128 |
| node3 | 192.168.204.129 |
如以下步骤使用机器名替代ip需要在/etc/hosts文件中配置例如192.168.204.127 node1信息 ,直接使用ip则不需要配置
3.2 环境准备
由于Kafka需要通过Zookeeper进行分布式系统的协调和促进,通过Zookeeper协调Broker、生产者和消费者。所以安装前需在每台机器上安装好Zookeeper(虽然Kafka自带有Zookeeper,但一般使用外置安装),具体安装步骤见https://blog.csdn.net/zhangkai19910815/article/details/84230349。
3.3 软件准备
Kafka属于Apache的一个子项目,需到其官网上进行下载,下载方式为:
wget https://www.apache.org/dyn/closer.cgi?path=/kafka/1.1.1/kafka_2.12-1.1.1.tgz
(具体版本以官网为准)
4 Kafka安装
如无特别说明,以下操作均需要在每台服务器上完成。
4.1 Kafka安装
1、进入某一目录(本文以/home/tmp/为例),执行如下命令完成kafka的下载:
wget https://www.apache.org/dyn/closer.cgi?path=/kafka/1.1.1/ kafka_2.12-1.1.1.tgz
2、执行命令解压压缩包至软件安装常用目录(本人常用目录为/usr/local/apps,个人按情况而定)
[root@node1 tmp]# tar zxvf kafka_2.12-1.1.1.tgz -C /usr/local/apps
3、为了方便操作,进入 /usr/local/apps 并修改安装目录名:
[root@ node1 tmp]# cd /usr/local/apps
[root@ node1 apps]# mv kafka_2.12-1.1.1 kafka
4、配置环境变量
vi /etc/profile
添加系统变量并修改PATH:
export KAFKA_HOME=/usr/local/apps/kafka
export PATH=.:${JAVA_HOME}/bin:${ZK_HOME}/bin:${STORM_HOME}/bin:$PATH:${KAFKA_HOME}/bin
4.2 Kafka配置
安装完成后需对Kafka进行配置,配置主要体现在config目录下的server.properties
[root@ node1 config]# cd /user/local/apps/kafka/config/
[root@ node1 config]# vi server.properties
将配置信息按如下内容进行基础性的修改:
1、 修改broker.id,确保每台机器的broker.id不一致,本文3台服务器的broker.id分别设置为1、2、3;
2、 port默认为9092,可以根据需要进行修改,一般情况下保持3台服务器一致;
3、 修改host.name为本机真实IP;
4、 num.partitions默认为1,可根据集群要求进行修改,本文修改为4;
5、 修改zookeeper.connect,其值为所有服务器上zookeeper的IP端口串,如下所示:
zookeeper.connect=192.168.204.127:2181,192.168.204.128:2181,192.168.204.129:2181
6、 log.dirs=/usr/local/apps/kafka/kafka-logs 配置kafka日志目录
4.3 启动与停止
4.3.1 启动
Kafka的启动顺序为启动Zookeeper—>启动Kafka。
1、 启动Zookeeper
在Zookeeper的安装目录下执行启动命令:
[root@node1 bin]#./zkServer.sh start
Zookeeper相关配置可见
https://blog.csdn.net/zhangkai19910815/article/details/84230349
2、 启动Kafka
执行如下命令,进行Kafka启动:
[root@ node1 bin]#./kafka-server-start.sh …/config/server.properties &
4.3.2 停止
Kafka的停止与启动顺序刚好相反:停止Kafka—>停止Zookeeper
1、停止Kafka
执行如下命令,进行Kafka停止:
[root@ node1 bin]#./kafka-server-stop.sh
第一次启动Kafka建议进入Kafka安装目录执行
bin/kafka-server-start.sh config/server.properties命令,方便查看详情启动日志
2、停止Zookeeper
在Zookeeper的安装目录下执行启动命令:
[root@ node1 bin]#./zkServer.sh stop
如果仅仅是停止Kafka而不是停止整个集群环境,可以不用停止Zookeeper。
5 Kafka常用命令
5.1 创建topic
在安装目录下执行以下命令进行topic的创建:
创建一个1个分区,3个副本,topic名为test01。
./kafka-topics.sh --create --zookeeper 192.168.204.127:2181 --replication-factor 3 --partitions 1 --topic test01
5.2 查看topic
在安装目录下执行以下命令,可查看kafka的topic情况:
[root@ node1 bin]# ./kafka-topics.sh --describe --zookeeper 192.168.204.127:2181
5.3 创建发送者
在安装目录下执行以下命令,可创建kafka生产者进行消息发布:
[root@node1 bin]#./kafka-console-producer.sh --broker-list 192.168.204.127:9092 --topic test01
Test msg1
Test msg2
5.4 创建消费者
结合5.3创建消费者使用,在一台机器的安装目录下执行以下命令,可创建kafka消费者进行消息读取:
[root@ node1 bin]#./kafka-console-consumer.sh --zookeeper 192.168.204.128:2181 --topic test01 --from-beginning
Test msg1
Test msg2