Netty源码阅读笔记2: 线程模型
一般来说基于Netty的服务端应用所使用的线程模型如下图所示:
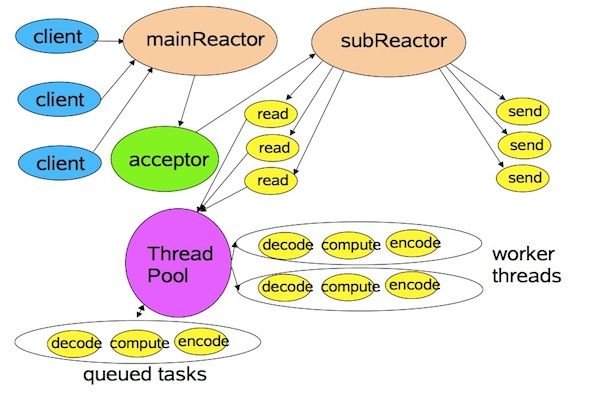
netty使用了reactor模式,使用很少的IO线程来处理大量的连接请求和IO操作,用较小的开销,实现了很高的性能。这其中的核心在于EventLoop和EventLoopGroup这两个接口,可以说它们是整个Netty框架的心脏,它们不仅处理IO操作,还负责系统Task和定时任务的执行,并能够控制IO和其它操作占用时间的比例。
先说EventLoop,它其实就充当上图中Reactor的角色。熟悉java nio的都知道,java nio的核心组件是一个selector和多个channel,Netty用NioEventLoop对selector进行了封装(用另一个Channel对java原生的channel进行了封装),不仅如此EventLoop还提供了selector进行IO轮询操作的线程模型。IO事件和系统Task都在EventLoop的线程中处理,为了保证线程安全性,同时最大程度的保证性能,EventLoop内部维护了一个队列,所有用户线程的操作都封装成一个task提交到这个队列,由IO线程负责执行。
下面的代码随处可见,目的是保证线程安全,确保不会有IO线程之外的线程直接发起IO操作:
@Override
public void invokeRead(final ChannelHandlerContext ctx) {
if (executor.inEventLoop()) {
invokeReadNow(ctx);
} else {
AbstractChannelHandlerContext dctx = (AbstractChannelHandlerContext) ctx;
Runnable task = dctx.invokeReadTask;
if (task == null) {
dctx.invokeReadTask = task = new Runnable() {
@Override
public void run() {
invokeReadNow(ctx);
}
};
}
executor.execute(task);
}
}再来说说EventLoopGroup,顾名思义,它就是一个线程组,负责管理EventLoop。在高并发的环境下,单一的IO线程可能无法应对,导致IO超时等现象,因此往往用一组IO线程来处理IO操作,每一个IO线程又负责处理多个连接。那么问题来了,如何保证每一个IO线程所负责的连接数大致相同呢?EventLoopGroup接口有一个next方法:
/**
* Return the next {@link EventLoop} to use
*/
@Override
EventLoop next();专门来进行连接的分配。使用java nio编程,我们需要注册channel到selector上,同样,使用Netty开发,我们需要注册Channel(这里是Netty定义的Channel)到EventLoopGroup,EventLoopGroup负责给我们分配一个EventLoop。NioEventLoopGroup使用下面的分配方式分配EventLoop:
private final class PowerOfTwoEventExecutorChooser implements EventExecutorChooser {
@Override
public EventExecutor next() {
return children[childIndex.getAndIncrement() & children.length - 1];
}
}
private final class GenericEventExecutorChooser implements EventExecutorChooser {
@Override
public EventExecutor next() {
return children[Math.abs(childIndex.getAndIncrement() % children.length)];
}
}children成员实际上就是一个EventLoop数组,那么上面两种选择方式都是轮询调度。这里有一个值得注意的地方:*
PowerOfTwoEventExecutorChooser对取模操作做了优化,因为如果N是2的整数次幂,那么对N取模和直接跟N-1进行位与操作是等价的,后者速度更快*
前面说了EventLoop除了负责IO操作之外,还负责系统Task和定时任务的执行,下面就是核心代码(为简洁起见,去掉了源码中的部分注释):
@Override
protected void run() {
for (;;) {
boolean oldWakenUp = wakenUp.getAndSet(false);
try {
if (hasTasks()) {
selectNow();
} else {
select(oldWakenUp);
if (wakenUp.get()) {
selector.wakeup();
}
}
cancelledKeys = 0;
needsToSelectAgain = false;
final int ioRatio = this.ioRatio;
if (ioRatio == 100) {
processSelectedKeys();
runAllTasks();
} else {
final long ioStartTime = System.nanoTime();
processSelectedKeys();
final long ioTime = System.nanoTime() - ioStartTime;
runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
if (isShuttingDown()) {
closeAll();
if (confirmShutdown()) {
break;
}
}
} catch (Throwable t) {
logger.warn("Unexpected exception in the selector loop.", t);
// Prevent possible consecutive immediate failures that lead to
// excessive CPU consumption.
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// Ignore.
}
}
}
}其中processSelectedKeys就是处理IO相关操作的方法,而runAllTasks是处理其它Task的方法。如果设置了ioRatio,即IO操作耗时整个事件循环的比例,那么会执行带时间参数的runAllTasks方法,根据本轮IO所花费的时间,计算分配给task的执行时间。
下面是runAllTasks方法的实现:
protected boolean runAllTasks(long timeoutNanos) {
fetchFromScheduledTaskQueue();
Runnable task = pollTask();
if (task == null) {
return false;
}
final long deadline = ScheduledFutureTask.nanoTime() + timeoutNanos;
long runTasks = 0;
long lastExecutionTime;
for (;;) {
try {
task.run();
} catch (Throwable t) {
logger.warn("A task raised an exception.", t);
}
runTasks ++;
// Check timeout every 64 tasks because nanoTime() is relatively expensive.
// XXX: Hard-coded value - will make it configurable if it is really a problem.
if ((runTasks & 0x3F) == 0) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
if (lastExecutionTime >= deadline) {
break;
}
}
task = pollTask();
if (task == null) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
break;
}
}
this.lastExecutionTime = lastExecutionTime;
return true;
}需要说明的是,NioEventLoop维护了两个Queue,一个用来存放系统任务的task Queue,另一个用来存放定时任务,因此runAllTasks首先会调用fetchFromScheduledTaskQueue() 把定时任务Queue中那些到期的定式任务挪到task Queue中,然后用pollTask()不断的从task Queue中取出任务来执行,直到用完所分配的时间片。
这里又有一个点值得注意,就是获取系统的纳秒级时间戳是一个重量级操作,因此这里每运行64个任务才判断一次时间,降低性能开销。另外这用runTasks & 0x3F 而不是 runTasks % 64,充分体现了Netty的开发者的细心和对性能的极致追求,值得我们学习!