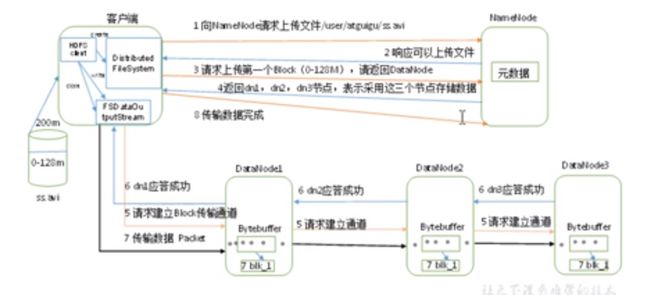
这是上一节的流程图:
1、网络拓扑距离最近,决定上一节中那三个datanode谁是第一个
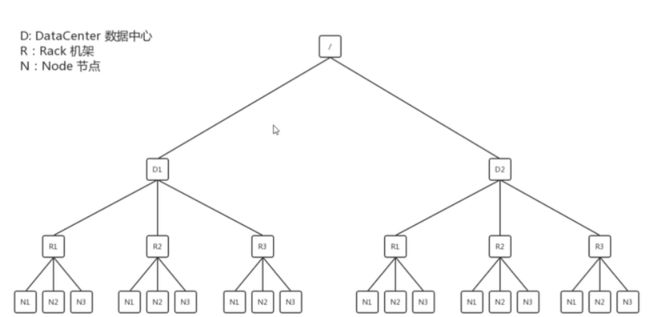
例如N!到N2的距离就通过数直线的方法获得就是2别的距离也是这样求出来。
2、选出第一个最近的节点之后,怎样选第二个和第三个啊
第二个是同机架的不同节点。第三个是不同机架的不用节点。不能跨越中心。(副本节点的存储命名为机架感知)
3、maven是什么:
他是管理项目的工具,在项目解决导入依赖存在jar冲突的问题,以及项目中的依赖的问题,
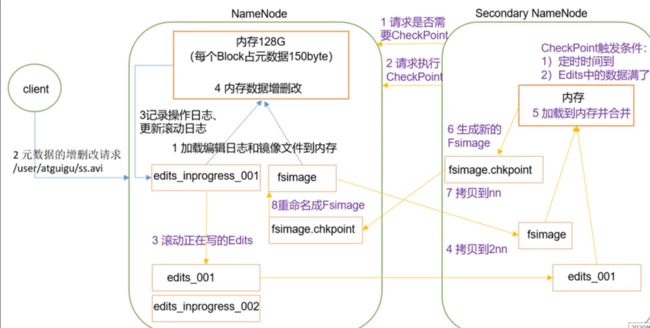
4、NN和2N的区别
NN是namenode。2N是secondarynamenode
简单说一下类似的:
Redis持久化分为:RDB和AOF
RDB:持久化的过程比较长,一定的时间或者操作量在生成RDB,加载比较快,安全性比较低
AOF:记录了每一条的操作,安全性高,占的空间比较大
现在说说HDFS:
假设Hsdoop中有类RDB和(Fsimage用起来时间短)类AOF(edits.log记录了所有的问题,用起来时间长)
2N中帮助hadoop把edits.log合并成Fsimage。流程图如下:
5、DN原理和校验原理
图解如下:
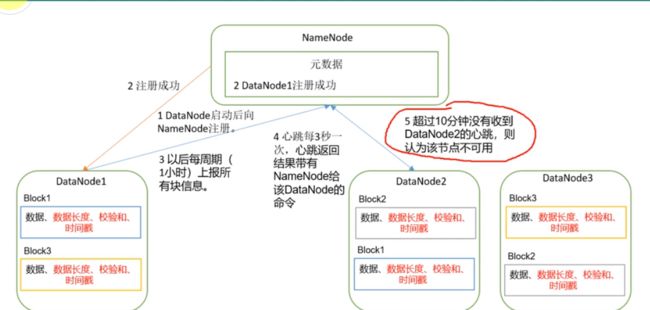
判断datanode死亡的依据:
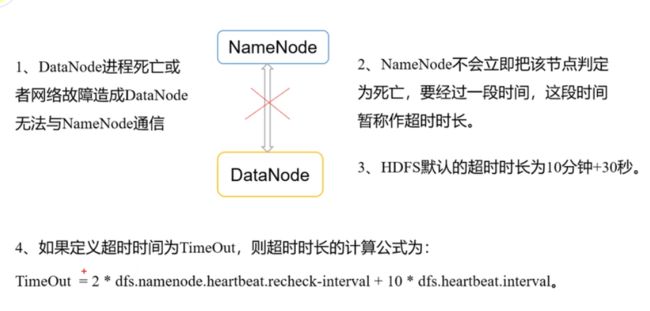
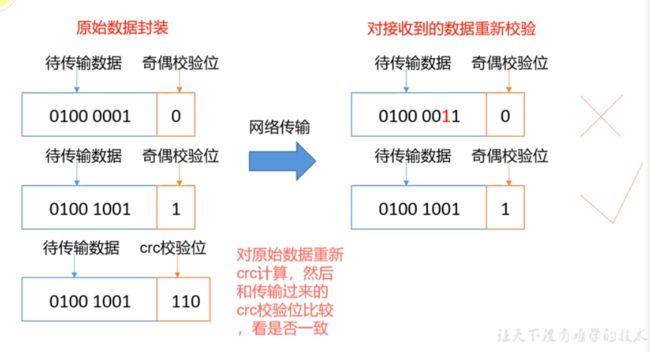
神魔是校验和:经过网络传输的过程,数据可能不可靠了。
如下是DataNode节点保证数据完整性的方法。。
1)当DataNode读取Block的时候,它会计算CheckSum.。
2)如果计算后的CheckSum,与Block创建时值不- -样,说明Block已经损坏。。
3) Client 读取其他DataNode上的Block..
4) DataNode 在其文件创建后周期验证CheckSum,如图一下;
相关重要知识点总结:
1、hadoop fs,hadoop dfs以及hdfs dfs区别
-
hadoop fs:
意思是说该命令可以用于其他文件系统,不止是hdfs文件系统内,也就是说该命令的使用范围更广 -
hadoop dfs
专门针对hdfs分布式文件系统 -
hdfs dfs
和上面的命令作用相同,相比于上面的命令更为推荐,并且当使用hadoop dfs时内部会被转为hdfs dfs命令
2、hadoop修改文件副本数
上传文件
命令上传文件,副本数为1
1 |
hadoop dfs -D dfs.replication=1 -put xxx /xxx |
检查单个文件的副本数
1 |
$ hadoop fsck -locations /xxx |
查看整的dfs上的文件副本数
1 |
$ hadoop fsck -locations |
修改已经存在的文件副本数
- 修改已保存文件的副本数量,为2副本
1 |
hadoop dfs -setrep 2 /shining/test.txt |
- 对文件夹中的所有文件都修改副本
1 |
hadoop dfs -setrep 2 -R /shining/ |
- 选项是-w,表示等待副本操作结束才退出命令
1 |
hadoop dfs -setrep -R -w 1 /shining |