NeuralNetwork(两层的实现)
实现两层的神经网络,利用反向传播算法,首先确定最优的超参数,然后确定权值,最后进行测试,准确率大概在47%左右,具体实现见如下代码:
import numpy as np
import pickle as pic
class neuralNet:
parameter=dict()
input_layer = 3072
hidden_layer = 80
output_layer = 10
learning_rate=0
regulation=0
learning_rate_decay=0
decay=0
decay_per=0
def readData(self, file):
with open(file, 'rb') as fo:
dict = pic.load(fo, encoding='bytes')
return dict
def getPrecision(self,data,label):
input1 = data.dot(self.parameter['W1'].T) + self.parameter['b1'] # batch_size*80
output1 = np.maximum(input1, 0) # batch_size*80
input2 = output1.dot(self.parameter['W2'].T) + self.parameter['b2'] # batch_size*10
output2 = input2 # batch_size*10
res=np.argmax(output2,axis=1)
return np.mean(res==label)
def Train_for_hyper(self,batch_size,iteration,train_data,train_label,
validate_data,validate_label,l_rate,re_rate,decay,deccay_per):
self.parameter['W1']=0.001*np.random.randn(self.hidden_layer,self.input_layer)
self.parameter['b1']=np.zeros(self.hidden_layer)
self.parameter['W2']=0.001*np.random.randn(self.output_layer,self.hidden_layer)
self.parameter['b2']=np.zeros(self.output_layer)
total=train_data.shape[0]
for i in range(0,iteration):
sample_ind=np.random.choice(total,batch_size,replace=False)
cur_train_data=train_data[sample_ind,:]
cur_train_label=train_label[sample_ind]
input1=cur_train_data.dot(self.parameter['W1'].T)+self.parameter['b1']#batch_size*80
output1=np.maximum(input1,0)#batch_size*80
input2=output1.dot(self.parameter['W2'].T)+self.parameter['b2']#batch_size*10
output2=input2#batch_size*10
#
output2=output2-np.max(output2,axis=1,keepdims=True)
output2=np.exp(output2)
sum=np.sum(output2,axis=1,keepdims=True)
output2=output2/sum#batch_size*10
#
output2[range(batch_size),cur_train_label]-=1#batch_size*10
output2=output2/batch_size#进行平均化处理
#
dw2=output2.T.dot(output1)+re_rate*self.parameter['W2']#10*80
db2=np.sum(output2,axis=0)#1*10
#
doutput1=output2.dot(self.parameter['W2'])#batch*80
doutput1[output1<=0]=0
#
dw1=doutput1.T.dot(cur_train_data)+re_rate*self.parameter['W1']#80*3072
db1=np.sum(doutput1,axis=0)
self.parameter['W1']-=l_rate*dw1
self.parameter['b1']-=l_rate*db1
self.parameter['W2']-=l_rate*dw2
self.parameter['b2']-=l_rate*db2
if(i%deccay_per==0):
l_rate*=decay
return self.getPrecision(validate_data,validate_label)
def Train_for_weight(self,batch_size,iteration,train_data,train_label):
self.parameter['W1'] = 0.001 * np.random.randn(self.hidden_layer, self.input_layer)
self.parameter['b1'] = np.zeros(self.hidden_layer)
self.parameter['W2'] = 0.001 * np.random.randn(self.output_layer, self.hidden_layer)
self.parameter['b2'] = np.zeros(self.output_layer)
total = train_data.shape[0]
for i in range(0, iteration):
sample_ind = np.random.choice(total, batch_size, replace=False)
cur_train_data = train_data[sample_ind, :]
cur_train_label = train_label[sample_ind]
input1 = cur_train_data.dot(self.parameter['W1'].T) + self.parameter['b1'] # batch_size*80
output1 = np.maximum(input1, 0) # batch_size*80
input2 = output1.dot(self.parameter['W2'].T) + self.parameter['b2'] # batch_size*10
output2 = input2 # batch_size*10
#
output2 = output2 - np.max(output2, axis=1, keepdims=True)
output2 = np.exp(output2)
sum = np.sum(output2, axis=1, keepdims=True)
output2 = output2 / sum # batch_size*10
#
output2[range(batch_size), cur_train_label] -= 1 # batch_size*10
output2 = output2 / batch_size # 进行平均化处理
#
dw2 = output2.T.dot(output1) + self.regulation* self.parameter['W2'] # 10*80
db2 = np.sum(output2, axis=0) # 1*10
#
doutput1 = output2.dot(self.parameter['W2']) # batch*80
doutput1[output1 <= 0] = 0
#
dw1 = doutput1.T.dot(cur_train_data) + self.regulation * self.parameter['W1'] # 80*3072
db1 = np.sum(doutput1, axis=0)
self.parameter['W1'] -= self.learning_rate * dw1
self.parameter['b1'] -= self.learning_rate * db1
self.parameter['W2'] -= self.learning_rate * dw2
self.parameter['b2'] -= self.learning_rate * db2
if (i % self.decay_per == 0):
self.learning_rate *= self.decay
def Test(self,path_train,path_test):
train_data,train_label,validate_data,validate_label,test_data,test_label=[],[],[],[],[],[]
for i in range(1,6):
cur_path=path_train+str(i)
read_temp=self.readData(cur_path)
if(i==1):
train_data=read_temp[b'data']
train_label=read_temp[b'labels']
else:
train_data=np.append(train_data,read_temp[b'data'],axis=0)
train_label+=read_temp[b'labels']
mean_image = np.mean(train_data, axis=0)
train_data = train_data - mean_image # 预处理
read_infor = self.readData(path_test)
train_label = np.array(train_label)
test_data = read_infor[b'data'] # 测试数据集
test_label = np.array(read_infor[b'labels']) # 测试标签
test_data = test_data - mean_image # 预处理
#train_data = np.hstack([train_data, np.ones((train_data.shape[0], 1))])
#test_data = np.hstack([test_data, np.ones((test_data.shape[0], 1))])
amount_train = train_data.shape[0]
amount_validate = 20000
amount_train -= amount_validate
validate_data = train_data[amount_train:, :] # 验证数据集
validate_label = train_label[amount_train:] # 验证标签
train_data = train_data[:amount_train, :] # 训练数据集
train_label = train_label[:amount_train] # 训练标签
l_range=[6e-4,7e-4,8e-4,9e-4,9e-4+6e-5,9e-4+7e-5]
re_range=[0.001,0.01,0.05]
decay_range=[0.97,0.99]
decay_per_iter=[200,500]
pre=-1
for lr in l_range:
for re in re_range:
for decay in decay_range:
for decay_per in decay_per_iter:
precision=self.Train_for_hyper(200,1000,train_data,
train_label,validate_data,validate_label,lr,re,decay,decay_per)
if(precision>pre):
pre=precision
self.learning_rate=lr
self.regulation=re
self.decay=decay
self.decay_per=decay_per
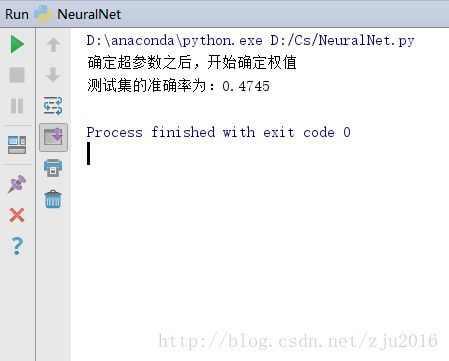
print("确定超参数之后,开始确定权值")
train_data=np.append(train_data,validate_data,axis=0)
train_label = np.append(train_label, validate_label, axis=0)
self.Train_for_weight(200,1000,train_data,train_label)
print("测试集的准确率为:"+str(self.getPrecision(test_data,test_label)))
a=neuralNet()
a.Test("D:\\data\\cifar-10-batches-py\\data_batch_",
"D:\\data\\cifar-10-batches-py\\test_batch")结果样例: