PySpark---SparkSQL中的DataFrame(一)
DataFrame是按照列名来组织数据的分布式数据集,是SparkSQL最重要的抽象。由于基于DataFrame的算法在性能和优化的余地上(Tungstun和Catalyst)有更大的空间,因此,现在Spark里基于DataFrame的机器学习库ml及Structured Streaming都采用这种数据结构。而且未来spark基于RDD的机器学习库mllib不会再更新,最新的算法都采用基于DataFrame来实现。
pyspark.sql.DataFrame(jdf,sql_stx)的一个DataFrame对象,在SparkSQL里面可以简单的理解为一张关系型数据库的表,并且是可以通过SparkSession上的很多个接口读取外部数据生成DataFrame对象.例如通过读取parquet格式文件的形式得到DataFrame.
df=spark.read.paarquet('路径/文件名.parquet')当然,可以通过类似表名.列名的方式来得到表中的内容,语法如: df.列名
下面介绍一些DataFrame的常用方法:(按照方法名称的字典序排列)
首先通过读取csv文件来创建一个df.这个df的结构如下:

1.agg(*exprs)
Aggregate on the entire :class:`DataFrame` without groups(shorthand for ``df.groupBy.agg()``)
传入要聚合的字段及聚合的方式,以字典的方式进行组合
df.agg({"grade1":"max","grade2":"sum"}).show()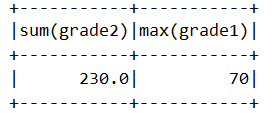
注意:如果对同一个列,做多次聚合操作,只保留最后的聚合操作,如下:
df.agg({"grade2":"sum","grade2":"avg","grade2":"min"}).show()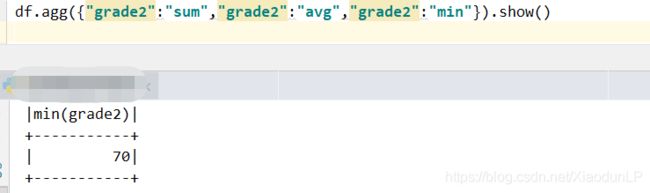
2.alias(alias)
Returns a new :class:`DataFrame` with an alias set.
为DataFrame定义一个别名,然后在函数中就可以利用这个别名来做相关的运 算,例如说自关联。
df1 = df.alias("d1")
df2 = df.alias("d2")
from pyspark.sql import functions as F # 这里只是为了方便,在这里引入了
df3 = df1.join(df2,F.col("d1.id")==F.col("d2.id"),'inner')
df3.show()
3.cache()
"""Persists the :class:`DataFrame` with the default storage level (C{MEMORY_AND_DISK}). ..
note:: The default storage level has changed to C{MEMORY_AND_DISK} to match Scala in 2.0. """
将DataFrame缓存到StorageLevel对应的缓存级别中,默认是 MEMORY_AND_DISK
df_cached = df.cache()
df_cached.后续操作将频繁需要查询的数据缓存起来,这样下一次要查询的时候就可以直接在内存中读取数据,从而提升数据的读取速度提升计算的效率。
4.checkpoint(eager=True)
"""Returns a checkpointed version of this Dataset. Checkpointing can be used to truncate the logical plan of this DataFrame, which is especially useful in iterative algorithms where the plan may grow exponentially. It will be saved to files inside the checkpoint directory set with L{SparkContext.setCheckpointDir()}."""
对DataFrame设置断点,这个方法是Spark2.1引入的方法,这个方法的调用会斩断在这个DataFrame上的逻辑执行计划,将前后的依赖关系持久化到checkpoint文件中去。这个方法对于需要大量需要迭代的算法非常有用,因为算法在迭代的过程中逻辑计划的数据量会呈现指数级别的上升。要使用这个方法需要使用sparkcontext上面的setCheckpointDir设置检查点数据在HDFS中的存储目录。有一个关键字参数eager,默认为True表示是否立即设置断点。
这里为了方便记录,我将程序定位在windows上执行,也将检查点的目录定位在桌面上
spark.sparkContext.setCheckpointDir(r'C:\Users\asus\Desktop\checkdir')
df.checkpoint()
df.show()
程序执行,桌面的检查点目录下已经有数据存在,更加深入的看一下

5.coalesce(numPartitions)
"""
Returns a new :class:`DataFrame` that has exactly `numPartitions` partitions.
Similar to coalesce defined on an :class:`RDD`, this operation results in a
narrow dependency, e.g. if you go from 1000 partitions to 100 partitions,
there will not be a shuffle, instead each of the 100 new partitions will
claim 10 of the current partitions. If a larger number of partitions is requested,
it will stay at the current number of partitions.
However, if you're doing a drastic coalesce, e.g. to numPartitions = 1,
this may result in your computation taking place on fewer nodes than
you like (e.g. one node in the case of numPartitions = 1). To avoid this,
you can call repartition(). This will add a shuffle step, but means the
current upstream partitions will be executed in parallel (per whatever
the current partitioning is).
>>> df.coalesce(1).rdd.getNumPartitions()
1
"""重分区算法,传入的参数是DataFrame的分区数量。 DataFrame上的这个方法和RDD上面的coalesce重分区方法是类似的。
由于这里使用的是local模式,这里程序最开始的分区数由线程数决定
输入目录如下

spark = SparkSession.builder.master("local[6]").getOrCreate()
df = spark.read.csv(r"C:\Users\25182\Desktop\input", header=True)
# 读取文件后的分区数
print(df.rdd.getNumPartitions())
df1 = df.coalesce(10)
df2 = df.coalesce(1)
# 重分区后的分区数
print(df1.rdd.getNumPartitions())
print(df2.rdd.getNumPartitions())结果如下:

我们发现:当前分区数如果少于方法传入的指定分区数是不起作用的.
6.repartition(numPartitions, *cols)
"""
Returns a new :class:`DataFrame` partitioned by the given partitioning expressions. The
resulting DataFrame is hash partitioned.
``numPartitions`` can be an int to specify the target number of partitions or a Column.
If it is a Column, it will be used as the first partitioning column. If not specified,
the default number of partitions is used.
.. versionchanged:: 1.6
Added optional arguments to specify the partitioning columns. Also made numPartitions
optional if partitioning columns are specified.
"""这个方法和coalesce(numPartitions) 方法一样,都是 对DataFrame进行重新的分区,但是repartition这个方法会使用hash算法,在整个集群中进行shuffle,效率较低。repartition方法不仅可以指定分区数,还可以指定按照哪些列来做分区。
# 将上面的coalesce方法用repartition代替
spark = SparkSession.builder.master("local[6]").getOrCreate()
df = spark.read.csv(r"C:\Users\25182\Desktop\input", header=True)
# 读取文件后的分区数
print(df.rdd.getNumPartitions())
df1 = df.repartition(10)
df2 = df.repartition(1)
# 重分区后的分区数
print(df1.rdd.getNumPartitions())
print(df2.rdd.getNumPartitions())结果如下;
=======================分割线=======================
在集群上找了一些大文件来演示重分区的两个方法:
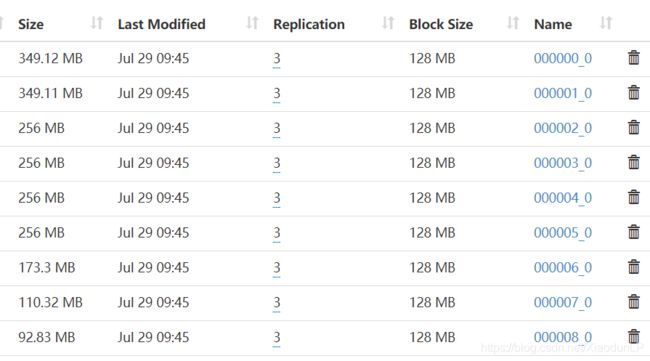
启动pyspark

这里为什么是18个分区呢?
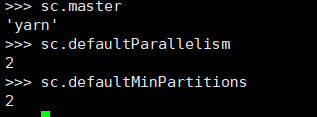
从hdfs分布式文件系统hdfs://生成的rdd,操作时如果没有指定分区数,则默认分区数规则为:rdd的分区数 = max(hdfs文件的block数目, sc.defaultMinPartitions),所以上面的18就知道怎么计算来的了把!
使用coalesce来重分区df

使用repartition来重分区df
