Kafka安装部署,快速入门
目录
1 简介
2 kafka安装
3 自带zookeeper配置和启动
4 kafka配置和启动
4.1 配置
4.2 启动服务
5 测试
6 问题解决
1 简介
它最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统。
本文主要是说明其消息系统的功能。 Apache Kafka是分布式发布-订阅消息系统,主要采取拉取模型(Pull)消费消息,即消费者可以自己控制消费速度和进度。
主要设计目标如下:
- 设计为一个分布式系统,易于向外扩展,支持在线水平扩展;
- 为发布和订阅提供高吞吐量,即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输;
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输;
- 支持离线数据处理和实时数据处理;
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
2 kafka安装
官网地址:http://kafka.apache.org/
官网安装包下载地址:http://kafka.apache.org/downloads
本文以安装包 kafka_2.13-2.4.0.tgz 为例。
将安装包上传到对应linux服务器上,并解压出来。
tar -xzvf kafka_2.13-2.4.0.tgz

3 自带zookeeper配置和启动
kafka和zookeeper都依赖于jdk,故在启动这两个之前得先检查下服务器上是否存在jdk,本文以jdk1.8为例,已经安装好的。
kafka依赖于zookeeper,所以需要先启动一个zookeeper服务。如果你还没有,则可以使用随kafka一起打包的便捷脚本来获取一个快速但是比较粗糙的单节点zookeeper实例。
# 进入kafka根目录
cd kafka_2.13-2.4.0/
# 启动zookeeper服务,以此命令启动,会将日志打印出来,且随着窗口的关闭也会停止进程
./bin/zookeeper-server-start.sh config/zookeeper.properties
# 后台启动zookeeper服务
./bin/zookeeper-server-start.sh -daemon config/zookeeper.propertieszookeeper.properties配置文件,主要有下面这三个配置,其中我们需要记住的是 clientPort=2181 配置参数,是kafka连接zookeeper需要用到的端口,后面配置kafka时会用到。
# the directory where the snapshot is stored.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
4 kafka配置和启动
4.1 配置
当前服务器ip为:192.168.17.137
| 配置项 | 默认值/示例值 | 说明 |
|---|---|---|
| broker.id | 0 | Broker唯一标识,要求大于等于0 |
| listeners | PLAINTEXT://192.168.17.137:9092 | 监听信息地址,PLAINTEXT表示明文传输 |
| advertised.listeners | PLAINTEXT://192.168.17.137:9092 | 监听信息地址,PLAINTEXT表示明文传输。优先以此参数,若没则以listeners参数。 |
| log.dirs | /tmp/kafka-logs | kafka数据存放地址,可以填写多个。用","间隔 |
| message.max.bytes | message.max.bytes | 单个消息长度限制,单位是字节 |
| num.partitions | 1 | 默认分区数 |
| log.flush.interval.messages | Long.MaxValue | 在数据被写入到硬盘和消费者可用前最大累积的消息的数量 |
| log.flush.interval.ms | Long.MaxValue | 在数据被写入到硬盘前的最大时间 |
| log.flush.scheduler.interval.ms | Long.MaxValue | 检查数据是否要写入到硬盘的时间间隔。 |
| log.retention.hours | 24 | 控制一个log保留时间,单位:小时 |
| zookeeper.connect | 192.168.17.137:2181 | ZooKeeper服务器地址,多台用","间隔 |
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
# 提供给客户端响应的端口
#port=9092
# broker的主机地址
#host.name=192.168.17.137
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://192.168.17.137:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
#advertised.listeners=PLAINTEXT://your.host.name:9092
# A comma separated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
# Zookeeper连接字符串,是一个使用逗号分隔的host:port字符串,多个以,隔开。
zookeeper.connect=192.168.17.137:2181
4.2 启动服务
服务的启动其实与zookeeper的一样。
# 启动kafka服务,以此命令启动,会将日志打印出来,且随着窗口的关闭也会停止进程
./bin/kafka-server-start.sh config/server.properties
# 后台启动kafka服务
./bin/kafka-server-start.sh -daemon config/server.properties
# 查看启动的zookeeper和kafka服务
jps
停止服务有两种方式:
(1)直接kill掉对应进程即可。
# 结束kafka进程
kill -9 5996
# 结束zookeeper进程
kill -9 5102(2)通过执行对应脚本停止。
# 结束kafka进程
./bin/kafka-server-stop.sh
# 结束zookeeper进程
./bin/zookeeper-server-stop.sh
5 测试
(1)使用以下命令创建的topic,名字为mytest,副本数为1,分区为1
./bin/kafka-topics.sh --create --zookeeper 192.168.17.137:2181 --replication-factor 1 --partitions 1 --topic mytest
(2)启动一个消费者(可以有多个消费者)
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.17.137:9092 --topic mytest --from-beginning
(3)启动生产者
./bin/kafka-console-producer.sh --broker-list 192.168.17.137:9092 --topic mytest
此时,界面上会出现一个输入界面,在此生产者界面随便输入信息,而在消费者界面会对应的输出信息。
![]()

(4)查看topic列表
./bin/kafka-topics.sh --list --zookeeper 192.168.17.137:2181
![]()
(5)查看mytest主题的详细信息
./bin/kafka-topics.sh --describe --zookeeper 192.168.17.137:2181 --topic mytest
![]()
第一行给出了所有分区的摘要,每个附加行给出了关于一个分区的信息。 由于我们只有一个分区,所以只有一行。
“Leader”: 是负责给定分区的所有读取和写入的节点。 每个节点将成为分区随机选择部分的领导者。
“Replicas”: 是复制此分区日志的节点列表,无论它们是否是领导者,或者即使他们当前处于活动状态。
“Isr”: 是一组“同步”副本。这是复制品列表的子集,当前活着并被引导到领导者。
6 问题解决
这里总结了下在安装部署kafka过程中可能会遇到的问题。
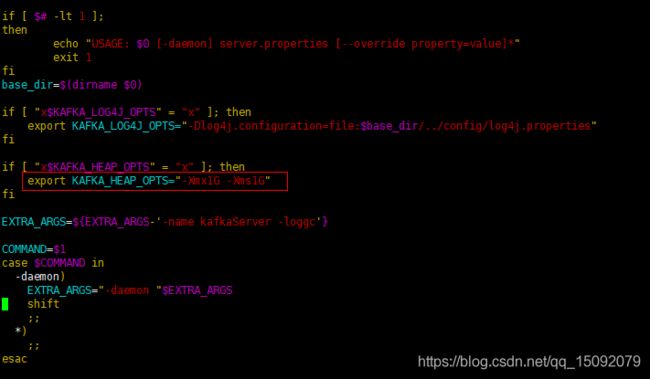
(1)failed; error=‘Cannot allocate memory,kafka报内存不足的异常。
vim bin/kafka-server-start.sh
# 找到这一行export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
# 改为 export KAFKA_HEAP_OPTS="-Xmx256M -Xms256M"
(2)could not be established. Broker may not be available,没有配置或配置错了监听地址。
vim config/server.properties
#设置好这两个参数(listeners,advertised.listeners)中的其中一个即可,大致意思就是,优先使用advertised.listeners配置的监听地址,否则就使用listeners的,若两个都没有配置则会报错。
listeners=PLAINTEXT://192.168.17.137:9092
