业务数仓项目总结
1 熟悉8张表的业务字段,每张表记住3-5个字段
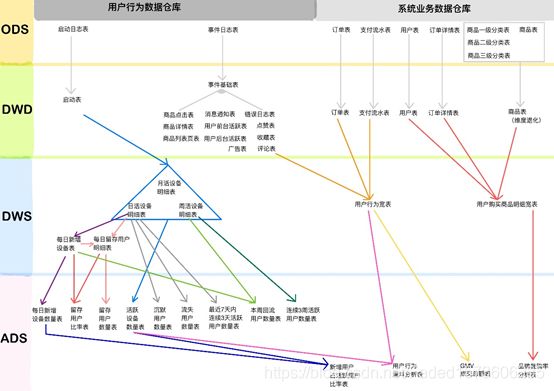
2 数仓理论
1)表的分类:实体表、维度表、事务型事实表、周期型事实表
2)表的同步策略:
实体表(全量)
维度表(全量)
事务型事实表(增量)
周期型事实表(新增和变化、拉链表)
3)范式理论:
一范式原则:属性不可切割;
二范式原则:不能存在部分函数依赖;
三范式原则:不能存在传递函数依赖;
4)数仓维度建模模型
星型模型,维度一层;
雪花模型,维度多层;
星座模型,多个事实表;
性能优先选择星型模型,灵活优先选择雪花模型。企业中星型模型多一些。
3 Sqoop参数
/opt/module/sqoop/bin/sqoop import \
--connect \
--username \
--password \
--target-dir \
--delete-target-dir \
--num-mappers \
--fields-terminated-by \
--query "$2" ' and $CONDITIONS;'
3.1 Sqoop导入导出Null存储一致性问题
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-string。
3.2 Sqoop数据导出一致性问题
1)场景1:如Sqoop在导出到Mysql时,使用4个Map任务,过程中有2个任务失败,那此时MySQL中存储了另外两个Map任务导入的数据,此时老板正好看到了这个报表数据。而开发工程师发现任务失败后,会调试问题并最终将全部数据正确的导入MySQL,那后面老板再次看报表数据,发现本次看到的数据与之前的不一致,这在生产环境是不允许的。
官网:http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html
Since Sqoop breaks down export process into multiple transactions, it is possible that a failed export job may result in partial data being committed to the database. This can further lead to subsequent jobs failing due to insert collisions in some cases, or lead to duplicated data in others. You can overcome this problem by specifying a staging table via the --staging-table option which acts as an auxiliary table that is used to stage exported data. The staged data is finally moved to the destination table in a single transaction.
–staging-table方式
sqoop export --connect jdbc:mysql://192.168.137.10:3306/user_behavior --username root --password 123456 --table app_cource_study_report --columns watch_video_cnt,complete_video_cnt,dt --fields-terminated-by "\t" --export-dir "/user/hive/warehouse/tmp.db/app_cource_study_analysis_${day}" --staging-table app_cource_study_report_tmp --clear-staging-table --input-null-string '\N'
2)场景2:设置map数量为1个(不推荐,面试官想要的答案不只这个)
多个Map任务时,采用–staging-table方式,仍然可以解决数据一致性问题。
3.3 Sqoop底层运行的任务是什么
只有Map阶段,没有Reduce阶段的任务。
3.4 Sqoop数据导出的时候一次执行多长时间
Sqoop任务5分钟-2个小时的都有。取决于数据量。
4 需求指标分析
1)GMV:一段时间内的网站成交金额(包括付款和未付款)
计算:基于用户行为宽表,对订单总金额进行sum。
2)转化率:(先分别计算分子和分母,再相除)
(1)新增用户占活跃用户的比率;
cast(sum( uc.nmc)/sum( uc.dc)*100 as decimal(10,2)) new_m_ratio
(2)下单人数占活跃用户的比率;
sum(if(order_count>0,1,0)) order_count
cast(ua.order_count/uv.day_count*100 as decimal(10,2)) visitor2order_convert_ratio
(3)支付人数占下单人数的比率;
sum(if(payment_count>0,1,0)) payment_count
cast(ua.payment_count/ua.order_count*100 as decimal(10,2)) order2payment_convert_ratio
3)复购率:(先分别计算分子和分母,再相除)
sum(if(mn.order_count>=1,1,0)) buycount,
sum(if(mn.order_count>=2,1,0)) buyTwiceLast,
sum(if(mn.order_count>=2,1,0))/sum( if(mn.order_count>=1,1,0)) buyTwiceLastRatio,
sum(if(mn.order_count>=3,1,0)) buy3timeLast ,
sum(if(mn.order_count>=3,1,0))/sum( if(mn.order_count>=1,1,0)) buy3timeLastRatio ,
5 拉链表
1)通过关系型数据库的create time和operation time获取数据的新增和变化。
2)用临时拉链表解决Hive了中数据不能更新的问题。
6 Azkaban
1)每天集群运行多少job?
2)多个指标(200)*6=1200(1000-2000个job)
3)每天集群运行多少个task? 1000*(5-8)=5000多个
4)任务挂了怎么办?运行成功或者失败都会发邮件
7 项目中表关系