数据仓库(二) 数仓理论(重点核心)
文章目录
- 数据仓库(二) 数仓理论(重点核心)
- 数仓分层
- 数据仓库分层
- ODS层
- DWD层
- DWS层
- DWT层
- ADS层
- 数据仓库分层的好处
- 关系建模与维度建模
- 关系建模
- 维度建模
- 星型模型
- 雪花模型
- 星型模型与雪花模型的区别
- 星座模型
- 模型的选择
- 维度表和事实表(重点)
- 维度表
- 维度表的概念
- 维表的特征
- 举例 - 时间维度表
- 事实表
- 事实表的概念
- 事实表的特征
- 事实表的分类
- 事务型事实表
- 周期型快照事实表
- 累积型快照事实表
- 数据仓库建模(绝对重点)
- ODS层
- DWD层
- 选择业务过程
- 声明粒度
- 确认维度
- 确认事实
- 小结
- DWS层
- DWT层
- ADS层
- 数据同步策略
- 全量同步策略
- 增量同步策略
- 新增及变化策略表
- 特殊策略(不变化)
数据仓库(二) 数仓理论(重点核心)
麻烦给我来一杯mojito,我喜欢数仓上头的感受~
数仓分层
数据仓库分层

ODS层
原始数据层,存放原始数据,直接加载原始日志,数据。数据保存原貌不做处理,起到备份数据的作用。
数据采用压缩,减少磁盘存储空间(例如:原始数据100G,可以压缩到10G左右,LZO)
创建分区表,防止后续的全表扫描。
DWD层
对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据),维度退化,脱敏等。
需构建维度模型,一般采用星型模型,呈现的状态一般为星座模型。
DWS层
以DWD为基础,按天进行轻度汇总。
统计各个主题对象的当天行为,服务于DWT层的主题宽表,以及一些业务明细数据,应对特殊需求(例如,购买行为,统计商品复购率)。
DWT层
以DWS为基础,按主题进行汇总。
以分析的主题对象为建模驱动,基于上层的应用和产品的指标需求,构建主题对象的全量宽表。
ADS层
为各种统计报表提供数据。
数据仓库分层的好处
- 把复杂问题简单化
将复杂的任务分解成多层来完成,每一层只处理简单的任务,方便定位问题。
- 减少重复开发
规范数据分层,通过中间层数据,能够减少极大的重复计算,增加一次计算结果的复用性。
- 隔离原始数据
不论是数据的异常还是数据的敏感性,使真实数据和统计数据解耦开。
关系建模与维度建模
当今的数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing),联机分析处理OLAP(on-line analytical processing)。
- OLTP是传统的关系型数据库的主要应用,主要是基本的,日常的事务处理,例如银行交易。
- OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
二者的主要区别对比:
| 对比属性 | OLTP | OLAP |
|---|---|---|
| 读特性 | 每次查询只返回少量记录 | 对大量记录进行汇总 |
| 写特性 | 随机,低延时写入用户的输入 | 批量导入 |
| 使用场景 | 用户,JavaEE项目 | 内部分析师,为决策提供支持 |
| 数据表征 | 最新数据状态 | 随时间变化的历史状态 |
| 数据规模 | GB | TB 到 PB |
关系建模
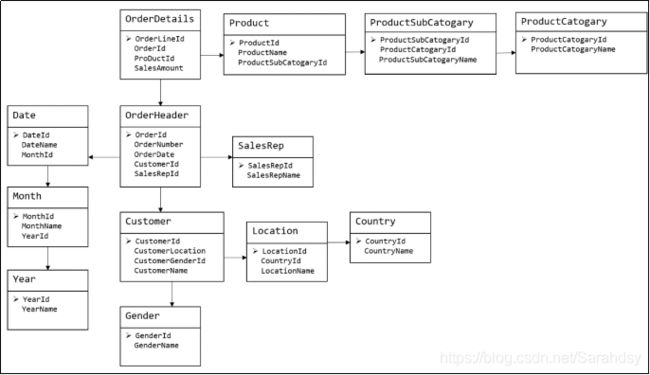
- 关系模型如图所示,严格遵守第三范式(3NF)。
从图中可以看出,较为松散,零碎。物理表数量多,而数据冗余程度低。
由于数据分布于众多的表中,这些数据可以更为灵活的被应用,功能性较强。
关系模型主要应用于OLTP系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统的表都是遵循第三范式的。
维度建模
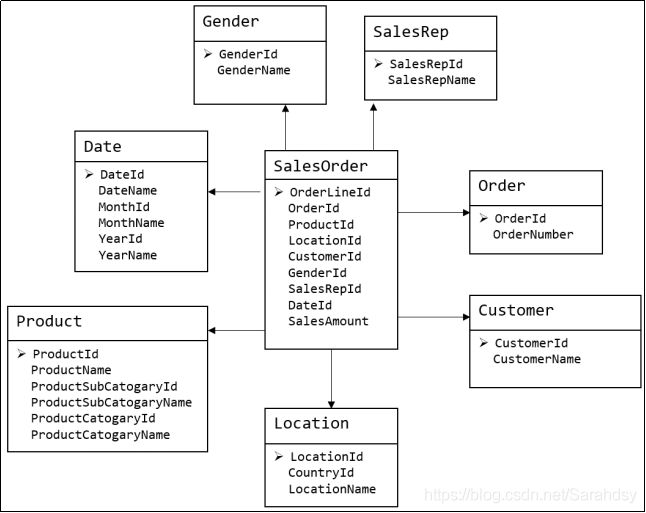
- 维度模型如同所示,主要应用于OLAP系统中,通常以某一个事实表为中心进行表的组织。
主要面向业务,特征是可能存在数据的冗余,但是能方便的得到数据。
关系模型虽然冗余少,但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。
所以通常我们采用维度模型建模,把相关各种表整理成两种:事实表和维度表两种。
- 在维度建模的基础上又分为三种模型:星型模型,雪花模型,星座模型。
星型模型

雪花模型

雪花模型,比较靠近3NF,但是无法完全遵守,因为遵循3NF的性能成本太高。
星型模型与雪花模型的区别
区别主要在于维度的层次。标准的星型模型维度只有一层,而雪花模型可能会涉及多层。
星座模型

- 星座模型与前两种情况的区别是事实表的数量,星座模型是基于多个事实表。
基本上是很多数据仓库的常态,因为很多数据仓库都是多个事实表的。所以星座不星座只反映是否有多个事实表,他们之间是否共享一些维度表。
所以星座模型并不和前两个模型冲突。
模型的选择
- 星座不星座只跟数据和需求有关系,跟设计没关系,不用选择。
- 星型还是雪花,取决于性能优先,还是灵活更优先。
实际企业开发中,根据情况灵活组合,甚至并存(一层维度和多层维度都保存)。
但是整体来看,更倾向于维度更少的星座模型。尤其是Hadoop体系,减少join就是减少Shuffle,性能差距很大。
维度表和事实表(重点)
维度表
维度表的概念
一般是对事实的描述信息。每一张维表对应业务中一个对象或者概念。
例如:用户,商品,日期,地区等。
维表的特征
- 维表的范围很宽(具有多个属性,列比较多)
- 跟事实表相比,行数相对较小:通常<10万条
- 内容相对固定:例如:编码表
举例 - 时间维度表
| 日期ID | day of week | day of year | 季度 | 节假日 |
|---|---|---|---|---|
| 2020-01-01 | 2 | 1 | 1 | 元旦 |
| 2020-01-02 | 3 | 2 | 1 | 无 |
事实表
事实表的概念
事实表中每行数据代表一个业务事件(下单,支付,退款,评价等)。
“事实”这个术语表示的是业务事件的度量值(可统计次数,个数,金额等),例如,订单事件中的下单金额。
每一个事实表的行包括:具有可加性的数值型的度量值,与维表相连接的外键。通常具有两个和两个以上的外键。
事实表的特征
- 数据量非常的大
- 内容相对的窄:列数比较少
- 经常发生变化,每天会新增加很大。
事实表的分类
事务型事实表
以每个事务或事件为单位, 例如:一个销售订单记录,一笔支付记录等,作为事实表里的一行数据。
一旦事务被提交,事实表数据被插入,数据就不再进行更改。
其更新方式为增量。
周期型快照事实表
周期型快照事实表中不会保留所有数据,只保留固定时间间隔的数据。
不关心具体的业务操作,只关心结果。
例如,每天或者每月的销售额,或每月的账户余额等。
其更新方式为全量。
累积型快照事实表
累积快照事实表用于跟踪业务事实的变化。
例如,数据仓库中可能需要累积或者存储订单从下订单开始,到订单商品被打包,运输,签收的各个业务阶段的时间点数据来跟踪订单生命周期的进展情况。
当这个业务过程进行时,事实表的记录也要不断更新。
其更新方式为新增及变化。
| 订单id | 用户id | 下单时间 | 打包时间 | 发货时间 | 签收时间 | 订单金额 |
|---|---|---|---|---|---|---|
| 3-8 | 3-8 | 3-9 | 3-10 |
数据仓库建模(绝对重点)
ODS层
- 保持数据原貌不做任何修改,起到备份数据的作用。
- 数据采用压缩,减少磁盘存储空间(例如:原始数据100G,可以压缩到10G左右)
- 创建分区表,防止后续的全表扫描
DWD层
- DWD层需构建维度模型,一般采用星型模型,呈现的状态一般为星座模型。
维度建模一般按照以下四个步骤:
选择业务过程 -> 声明粒度 -> 确认维度 -> 确认事实
选择业务过程
在业务系统中,挑选我们感兴趣的业务线,比如下单业务,支付业务,退款业务,物理业务。
一条业务线对应一张事实表。
声明粒度
数据粒度:指数据仓库的数据中保存数据的细化程度或综合程度的级别。
声明粒度:意味着精确定义事实表的一行数据表示什么,应该尽可能选择最小粒度,以此来应对各种各样的需求。
典型的粒度声明:
- 订单详情表中,每行数据对应一个订单中的一个商品项
- 订单表中,每行数据对应一个订单
确认维度
维度的主要作用是描述业务是事实,主要表示的是“谁,何处,何时”等信息。
方法:退化维度主题,罗列出所有维度(主题),然后确认哪些业务与哪些维度(主题)有关。
确认事实
此处的“事实”一词,指的是业务中的度量值,例如订单金额,下单次数等。
小结
- 在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。
- 构建维度退化的维度表。

- 至此,数仓的维度建模已经完毕。
- DWS,DWT,ADS都和维度建模已经没有关系了。DWS和DWT层是为了优化重复查询相同的数据而生成的
- DWS和DWT都是建宽表,宽表都是按照主题去建。主题相当于观察问题的角度,对应着维度表。
- 所谓的宽表:以维度表为中心,去关联相关的事实表,然后确定度量值。然后进行汇总,接着使用维度数据去替换外键,生成最终的宽表。也就是说,宽表里存的是真实维度值和汇总度量值
DWS层
统计各个主题对象的当天行为,服务于DWT层的主题宽表,以及一些业务明细数据,应对特殊需求(例如,购买行为,统计商品复购率)。
- 每日设备行为
- 每日会员行为
- 每日商品行为
- 每日地区统计
- 每日活动统计
DWT层
以分析的主题对象为建模驱动,基于上层的应用和产品的指标需求,构建主题对象的全量宽表。
- 设备主题
- 会员主题
- 商品主题
- 地区主题
- 活动主题
ADS层
对电商系统各大主题指标分别进行分析。
数据同步策略
数仓中的数据有一个时间轴的概念,体现在数据上就是以年-月-日进行数据同步和分区。保存历史状态。
我们可以以时间为维度,分析各种指标在时间上的延续性。
这里的数据同步指的是数据从业务服务器传到数仓
- 全量表:存储完整的数据
- 增量表:存储新增加的数据
- 新增及变化表:存储新增加的和变化的数据
- 特殊表:只需要存储一次
全量同步策略
每日全量:就是每天存储一份完整数据,作为一个分区
适用:表数据量不大,且每天既会有新数据插入,也会有旧数据修改的场景
例如:
- 维度表:
- 编码字典维度表:编码字典表
- 商品维度表:品牌表,商品三级分类,商品二级分类,商品一级分类,SKU商品表,SPU商品表
- 活动维度表:活动规则表,活动表,活动参与商品表
- 优惠券维度表:优惠券表
- 事实表:
- 加购表
- 商品收藏表
这两张事实表数据量也不小,用全量同步策略是因为业务需求。数仓用来做周期性快照事实表。
Sqoop:
where 1=1
增量同步策略
每日增量:就是每天存储一份增量数据,作为一个分区。
适用:表数据量大,且每天只会有新数据插入的场景。
例如:
- 事实表:
- 退单表,订单状态表,支付流水表,订单详情表,活动与订单关联表
- 商品评论表
Sqoop:
where date_format(create_time,'%Y-%m-%d')='$do_date'
新增及变化策略表
每日新增及变化:就是存储创建时间和操作时间都是今天的数据。
适用:表的数据量大,既会有新增,又会有变化。
例如:
- 维度表:更新使用拉链表
- 用户表
- 事实表:更新使用累积型快照事实表
- 订单表,优惠券领用表
Sqoop:
where (date_format(create_time,'%Y-%m-%d')='$do_date'
or date_format(operate_time,'%Y-%m-%d')='$do_date'
特殊策略(不变化)
某些特殊的维度表,可不必遵循上述同步策略。
-
1)客观世界维度
没变化的客观世界维度可以只存一份固定值。比如 性别,地区,名族,政治成分,鞋子尺码。 -
2)日期维度
日期维度可以一次性导入一年或若干年的数据。 -
3)地区维度
省份表,地区表
Sqoop:
where 1=1