ElasticSearch(四)--分布式文档存储
前边的章节中,我们已经学习了如何将数据存储到索引中,并检索他们,我们忽略了数据是如何分布式存储和匹配的技术细节,本章节就是为了此目的,虽然你不必真正的需要理解数据是如何分布式工作的,就能使用它工作。
1. 路由文档
每个文档都会存储在单独的一个分片上,那么在检索文档的时候,如何知道文档存储在哪个分片上呢?
当创建一个新文档时,如何确定它是要存储到哪一个分片上呢?
根据一个简单的算法:
shard = hash(routing) % number_of_primary_shards通过这样的算法确定一个文档应当被分配到哪一个分片上存储,而且记录下来作为检索文档时的路由.
这样解释了为什么主分片的数量在创建索引时确定,后期不能更改,因为更改后会破化路由信息.
所有的文件操作API都接受一个routing参数,这个参数可以用来自定义文档到分片的映射.自定义路由值可以确保相关文档被保存到同一分片上,例如隶属于同一个人的文档.
2. 主副分片的交互
为了解释方便,我们设想一个有三个节点的集群,它包含一个名为blogs的索引,该索引有两个主分片,每个主分片有两个复制分片,同一个分片的备份不能分配到同一个节点上,所以该集群可以如图所示

我们可以发送请求到集群中的任何一个节点,每个节点有足够的能力服务任何请求,每个节点都知道每个文档在集群中的位置,然后转发请求到相应的节点,在下边的例子中,我们发送所有的请求到节点node1,我们称该节点为协调节点coordinating node.
注意:当发送请求时,比较好的做法是,对集群中的所有节点进行循环请求,以使负载均衡。
3. 创建 索引 删除文档
创建create,索引index,删除delete 请求都是
写write操作,这些操作必须先在主分片里完成,然后再复制到其他所有的复制分片中去。如图:

这是一系列的步骤,在主分片和复制分片上都进行创建,索引,删除操作:
1. 客户端发送一个写请求到节点node1
2. 节点使用文档的_id决定文档属于分片0,转发请求到node3,分片0的主分片存储在这里
3. node3执行请求在主分片,如果执行成功,它并行的转发请求到位于node1和node2的复制分片上,一旦所有的复制分片报告成功,node3才报告一个成功消息给协调节点node1,它给客户端发送成功报告。
当客户端收到一个成功响应之后,文档的改变操作在主分片和复制分片上已经成功。这个改变是安全的。
有很多参数允许你可以对这一过程产生影响,很可能以牺牲数据安全为代价,换取性能。这些选项很少使用,因为ES已经够快了,但是为了完整性,还是讲明。
consistency
默认的,在执行写操作前,主分片需要获得一个关于分片备份(主分片和复制分片都是)的法定数目
quorum,这可以阻止写数据到错误的网络分区,quorum的定义:
int( (primary + number_of_replicas) / 2 ) + 1
number_of_replicas是指在索引设置中指明的复制分片的数量,而不是当前活跃的复制分片的数量,如果指定一个索引有三个复制分片,quorum的值为:
int( (primary + 3 replicas) / 2 ) + 1 = 3
timeout
那么,不足的分片备份时,会发生什么?ES会等,希望更多的分片出现。但是默认的等待时间是1min,如果需要,可以使用timeout参数是它更快:100为100毫秒,30s为30秒。
注意:默认情况下,一个新的索引有一个复制分片,这意味着需要2个活跃分片来满足quroum,然而这些默认的设置将会阻止我们做任何有用的事情,在一个单节点集群内。
所以,为避免这个问题,只有当number_of_replicas大于1时,quorum的要求才会生效。
4. 检索文档
一个文档可以从主分片和任何复制分片中检索,如图:
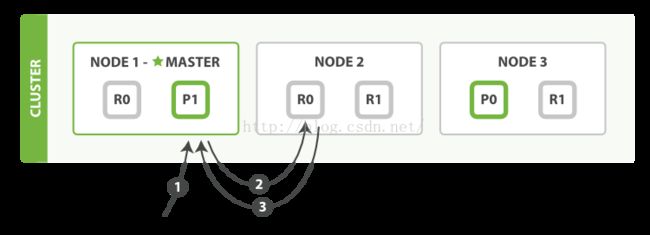
步骤:
1. 客户端发送请求到节点node1,
2. node1使用文档的_id决定文档属于分片0,分片0的所有备份在三个节点上都存在,在这种情况下,它把请求转发给node2,
3. node2返回文档给Node1,node1返回文档给客户端。
对于读请求,协调节点会选择不同的分片回应每个请求,以使负载均衡,它轮转所有的分片。
这种状况是可能的,一个文档被索引,主分片上已经存在,但是复制分片上还没有被拷贝,在这种状况下,复制分片会报告文档不存在,而主分片会成功返回文档。
一旦一个检索请求返回成功,文档在主分片和复制分片上都是可以请求得到的。