library(data.table)
ID <- c(NA,1,2,2)
ID
Time <- c(1,2,NA,1)
Time
X1 <- c(5,3,NA,2)
X1
X2 <- c(NA,5,1,4)
X2
mydata <- data.table(ID,Time,X1,X2)
mydata
``````````````````````````
ID Time X1 X2
1: NA 1 c NA
2: 1 2 a 5
3: 2 NA NA 1
4: 2 1 b 4
md <- melt(mydata, id=c("ID","Time"))
##melt以使每一行都是一个唯一的标识符-变量组合
md
````````````````````````````
## ID Time variable value
## 1: NA 1 X1 5
## 2: 1 2 X1 3
## 3: 2 NA X1 NA
## 4: 2 1 X1 2
## 5: NA 1 X2 NA
## 6: 1 2 X2 5
## 7: 2 NA X2 1
## 8: 2 1 X2 4
``````````````````````````````
str(md)
str(mydata)
## Classes 'data.table' and 'data.frame': 8 obs. of 4 variables:
## $ ID : num NA 1 2 2 NA 1 2 2
## $ Time : num 1 2 NA 1 1 2 NA 1
## $ variable: Factor w/ 2 levels "X1","X2": 1 1 1 1 2 2 2 2
## $ value : num 5 3 NA 2 NA 5 1 4
## - attr(*, ".internal.selfref")=
setcolorder(md,c("ID","variable","Time","value"))
## ID variable Time value
## 1: NA X1 1 5
## 2: 1 X1 2 3
## 3: 2 X1 NA NA
## 4: 2 X1 1 2
## 5: NA X2 1 NA
## 6: 1 X2 2 5
## 7: 2 X2 NA 1
## 8: 2 X2 1 4
##setcolorder()可以用来修改列的顺序。
mdr <- melt(mydata, id=c("ID","Time"),variable.name="Xzl",value.name="Vzl",na.rm = TRUE)
#variable.name定义变量名
mdr
## ID Time Xzl Vzl
## 1: NA 1 X1 5
## 2: 1 2 X1 3
## 3: 2 1 X1 2
## 4: 1 2 X2 5
## 5: 2 NA X2 1
## 6: 2 1 X2 4
mdr1 <- melt(mydata, id=c("ID","Time"),variable.name="Xzl",value.name="Vzl",measure.vars=c("X1"),na.rm = TRUE)
#measure.vars筛选
mdr1
## ID Time Xzl Vzl
## 1: NA 1 X1 5
## 2: 1 2 X1 3
## 3: 2 1 X1 2
#执行整合
newmd<- dcast(md, ID~variable, mean)
#value为数值型
## ID X1 X2
## 1: 1 3 5.0
## 2: 2 NA 2.5
## 3: NA 5 NA
newmd2<- dcast(md, ID+variable~Time)
newmd2
## ID variable 1 2 NA
## 1: 1 X1 NA 3 NA
## 2: 1 X2 NA 5 NA
## 3: 2 X1 2 NA NA
## 4: 2 X2 4 NA 1
## 5: NA X1 5 NA NA
## 6: NA X2 NA NA NA
#ID+variable~Time 使用Time对(ID,variable)分组 Time:1,2,NA 类似excel的数据透析
newmd3<- dcast(md, ID~variable+Time)
newmd3
#variable:X1,X2 Time:1,2,NA 类似excel的数据透析
## ID X1_1 X1_2 X1_NA X2_1 X2_2 X2_NA
## 1: 1 NA 3 NA NA 5 NA
## 2: 2 2 NA NA 4 NA 1
## 3: NA 5 NA NA NA NA NA
##实例
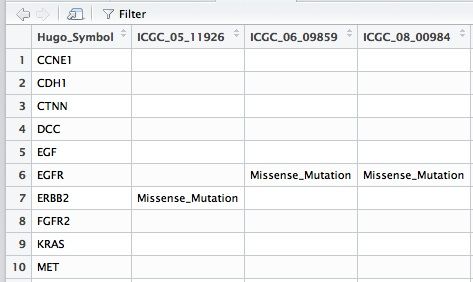
data <- read.table("data.txt",header = T)
##
Hugo_Symbol Variant_Classification Tumor_ICGC_Barcode
1 ERBB2 Missense_Mutation ICGC_05_11926
2 EGFR Missense_Mutation ICGC_06_09859
3 EGFR Missense_Mutation ICGC_08_00984
4 EGF Missense_Mutation ICGC_08_14667
5 CTNN Missense_Mutation ICGC_09_02266
6 MET Missense_Mutation ICGC_09_02266
7 MET Missense_Mutation ICGC_09_06938
8 CCNE1 Missense_Mutation ICGC_09_06938
9 CTNN Missense_Mutation ICGC_09_07343
str(data)
data2 <- dcast(data, Hugo_Symbol ~ Tumor_ICGC_Barcode,
fun.aggregate = function(x) {ifelse(test = length(as.character(x))>1 ,
no = as.character(x), yes = vcr(x, gis = FALSE))
},
value.var = 'Variant_Classification', fill = '')
vcr = function(x, gis = FALSE) {
x = as.character(x)
x = strsplit(x = x, split = ';', fixed = TRUE)[[1]]
x = unique(x)
xad = x[x %in% c('Amp', 'Del')]
xvc = x[!x %in% c('Amp', 'Del')]
if(gis){
x = ifelse(test = length(xad) > 1, no = xad, yes = 'Complex')
}else{
if(length(xvc)>0){
xvc = ifelse(test = length(xvc) > 1, yes = 'Multi_Hit', no = xvc)
}
x = ifelse(test = length(xad) == 1, yes = paste(xvc, xad, sep = ';'), no = xvc)
}
return(x)
}
#data2 即将数据转换为透视表格式