生成本地log最好生成多个文件放在一个文件夹里,特别多的时候一个小时一个文件
配置好Nginx后,通过flume收集日志到hdfs
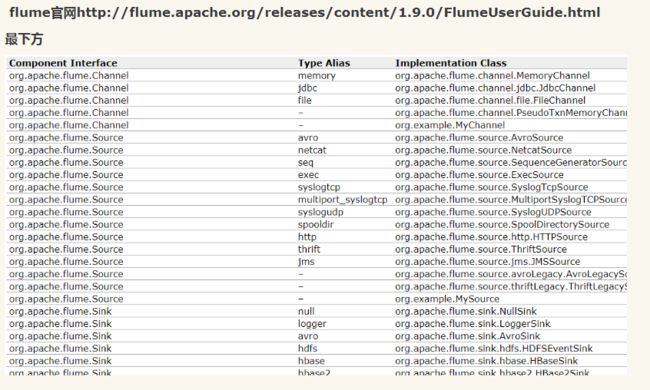
可参考flume的文件
用flume的案例二
执行的注意点

![]()


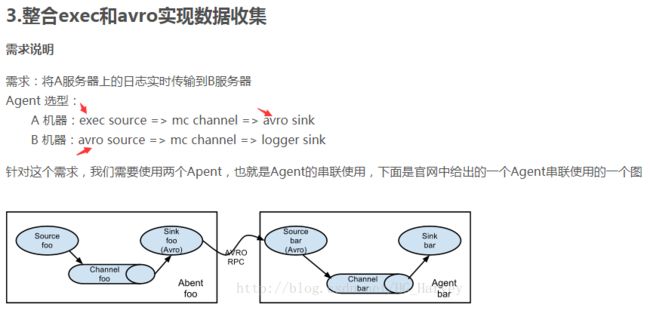
avro和exec联合用法
https://blog.csdn.net/HG_Harvey/article/details/78358304
exec实质是收集文件


spool用法
https://blog.csdn.net/a_drjiaoda/article/details/84954593


或者下面这个代码
名字为
conf/job/project/flume-hdfs.conf
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/data/access.log
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://master:9000/project/log/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 10240000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.callTimeout = 60000
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.idleTimeout = 10
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动hdfs的前提下
start-all.sh
执行
flume-ng agent --conf conf/ --name a1 --conf-file conf/job/project/flume-hdfs.conf