精通Kubernetes:高可用性最佳实践
建立可靠和高可用的分布式系统是一项宏大的任务。本节将介绍部分最佳实践用例,这些用例使基于Kubernetes的系统能够可靠地工作,还能应对各种类型的故障。
4.2.1 创建高可用性集群
要创建一个高可用性Kubernetes集群,主组件必须是冗余的。这意味着etcd必须以集群的形式部署(常常是跨3个或5个节点的集群),并且Kubernetes API服务器必须是冗余的。如果有必要,则Heapster存储之类的辅助集群管理服务也可进行冗余部署。图4.1展示了一个典型的可靠和高可用的Kubernetes集群,其中包含几个负载均衡的主节点,每个主节点包含完整的主组件和etcd组件。
这并非配置高可用性集群的唯一方法。例如,为优化机器的工作负载部署单例etcd集群或者为etcd集群配置比其他主节点更多的冗余。
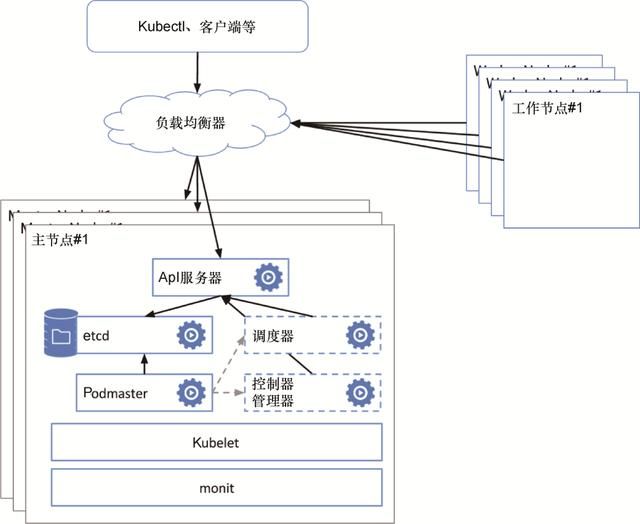
图4.1 可靠和高可用性的Kubernetes集群
4.2.2 确保节点可靠
节点或某些组件可能发生故障,但许多故障都是暂时的。一些基本的保障可确保Docker 后台支撑服务和Kubelet在发生故障时自动重启。
如果运行CoreOS、现代的Debian-based OS(Ubuntu≥16.04版本)或任何其他使用Systemd作为其初始化机制的操作系统,则很容易将Docker和Kubelet部署为自启动后台支撑服务,代码如下所示。
systemctl enable docker
systemctl enable kublet对于其他操作系统,Kubernetes项目为其高可用性用例提供了Monit,读者可根据需求自行选择任意过程监视器。
4.2.3 保护集群状态
Kubernetes集群状态存储在etcd集群中,etcd集群被设计得非常可靠,且分布在多个节点上。将这些能力应用到可靠和高可用的Kubernetes集群上非常重要。
1.etcd集群
在etcd群集中至少应该有3个节点。如果读者需要更强的可靠性和冗余,则可以使用5个、7个或任何其他奇数个节点。考虑到网络分裂的情况,节点的数量必须是奇数的。
为了创建一个集群,etcd节点应该能够发现彼此。有几种方法可以做到这一点。
2.静态发现
通过静态发现,可以直接管理每个etcd的IP地址/主机名。这并不意味着可以在Kubernetes集群之外管理etcd集群,或对etcd集群的健康运行状态负责。etcd节点将作为Pod运行,并在需要时自动重新启动。
假设etcd集群包含3个节点,代码如下所示。
etcd-1 10.0.0.1
etcd-2 10.0.0.2
etcd-2 10.0.0.3每个节点将接收这个初始集群信息作为命令行信息,代码如下所示。
--initial-cluster etcd-1=http://10.0.0.1:2380,etcd-
2=http://10.0.0.2:2380,etcd-3=http://10.0.0.3:2380
--initial-cluster-state new或者,接收其作为环境变量,代码如下所示。
ETCD_INITIAL_CLUSTER="etcd-1=http://10.0.0.1:2380,etcd-
2=http://10.0.0.2:2380,etcd-3=http://10.0.0.3:2380"
ETCD_INITIAL_CLUSTER_STATE=new3.etcd发现
使用etcd发现,可以使用现有的集群来让新集群的节点发现彼此。当然,这需要新的集群节点能够访问现有的集群。如果读者不担心依赖项和安全隐患,也可以使用https://discovery.etcd.io上的公共etcd发现服务。
读者需要创建一个发现令牌,如有必要可以指定集群大小,默认值为3,如下代码中是需要输入的命令。
$ curl https://discovery.etcd.io/new?size=3
https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
在使用发现服务时,需要将令牌作为命令行参数传递,代码如下所示。
--discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
还可以将其作为环境变量传递,代码如下所示。
ETCD_DISCOVERY=https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
值得注意的是,发现服务仅与初始集群的初始引导有关,一旦启动集群并使用初始节点运行,就使用单独的协议从正在运行的集群中添加和删除节点,这样便不会对公共etcd发现服务保持永久的依赖性。
4.DNS发现
也可以使用DNS并通过SRV记录来建立发现,SRV记录可以包含或者不包含TLS,本书不涉及这部分内容,读者可以通过寻找etcd DNS发现来寻找解决方案。
5.etcd.yaml文件
根据发现的思路,在每个节点上启动etcd实例的命令和在etcd.yaml Pod清单中的配置略有不同。清单应复制粘贴到每个etcd节点的/etc/kubernetes/manifests中。
如下代码展示了etcd.yaml清单文件的不同部分。
apiVersion: v1
kind: Pod
metadata:
name: etcd-server
spec:
hostNetwork: true
containers:
- image: gcr.io/google_containers/etcd:2.0.9
name: etcd-container
初始部分包含Pod的名称,指定它使用的主机网络,并定义一个名为etcd- container的容器。然后,最关键的部分是所使用的Docker镜像。在如下代码所示的案例中,它是etcd: 2.0.9,类似于在etcd V2中。
command:
- /usr/local/bin/etcd
- --name
-
- --initial-advertise-peer-urls
- http://:2380
- --listen-peer-urls
- http://:2380
- --advertise-client-urls
- http://:4001
- --listen-client-urls
- http://127.0.0.1:4001
- --data-dir
- /var/etcd/data
- --discovery
-
命令部分列出etcd正确操作所需的命令行参数。在以上代码所示的案例中,因为使用了etcd发现机制,所以需要指定discovery标志。
ports:
- containerPort: 2380
hostPort: 2380
name: serverport
- containerPort: 4001
hostPort: 4001
name: clientport
在以上代码所示的案例中,端口部分列出了服务器(2380)和客户端(4001)端口,这些端口被映射到主机上的相同端口。
volumeMounts:
- mountPath: /var/etcd
name: varetcd
- mountPath: /etc/ssl
name: etcssl
readOnly: true
- mountPath: /usr/share/ssl
name: usrsharessl
readOnly: true
- mountPath: /var/ssl
name: varssl
readOnly: true
- mountPath: /usr/ssl
name: usrssl
readOnly: true
- mountPath: /usr/lib/ssl
name: usrlibssl
readOnly: true
- mountPath: /usr/local/openssl
name: usrlocalopenssl
readOnly: true
- mountPath: /etc/openssl
name: etcopenssl
readOnly: true
- mountPath: /etc/pki/tls
name: etcpkitls
readOnly: true
挂载部分列出/var/etcd处的varetcd挂载,etcd在其中写入数据,还有一些etcd没有修改的SSL和TLS只读挂载,代码如下所示。
volumes:
- hostPath:
path: /var/etcd/data
name: varetcd
- hostPath:
path: /etc/ssl
name: etcssl
- hostPath:
path: /usr/share/ssl
name: usrsharessl
- hostPath:
path: /var/ssl
name: varssl
- hostPath:
path: /usr/ssl
name: usrssl
- hostPath:
path: /usr/lib/ssl
name: usrlibssl
- hostPath:
path: /usr/local/openssl
name: usrlocalopenssl
- hostPath:
path: /etc/openssl
name: etcopenssl
- hostPath:
path: /etc/pki/tls
name: etcpkitls
volumes部分为映射到相应主机路径的每个挂载提供一个存储卷。虽然只读挂载尚且可行,但用户也许会希望将varetcd卷映射到更健壮的网络存储,而不是仅仅依赖于etcd节点本身的冗余。
6.验证etcd集群
一旦etcd集群启动并运行,就可以访问etcdctl工具来检查集群状态和健康状况。Kubernetes允许通过exec命令直接在Pod或容器中执行命令(类似于docker exec)。
建议的命令代码如下所示。
- etcdctl member list
- etcdctl cluster-health
- etcdctl set test ("yeah, it works!")
- etcdctl get test (should return "yeah, it works!")
7.etcd v2与etcd v3
在本书撰写时,Kubernetes 1.4仅支持etcd v2,但etcd v3有了显著的改进,也增加了许多值得称赞的新特性,例如以下特性。
- 从JSON REST切换到protobufs gRPC,本地客户端的性能提高了一倍。
- 支持租赁与冗长的密钥TTL,从而改进了性能。
- 使用gRPC将多个Watch复用在一个连接上,而不是为每个Watch保持一个开放的连接。
etcd v3已被证明可以在Kubernetes上运行,但尚未被正式支持,这是一大进步,该项工作正在进行中。希望读者读到本书时,v3能正式被Kubernetes官方所支持。若非如此,也有可能将etcd v2迁移到etcd v3。
4.2.4 保护数据
保护集群状态和配置很重要,但保护自身数据却更为重要。如果集群状态遭到破坏,那么通常可以从头开始重新构建集群(尽管在重建期间集群将不可用)。但是如果数据被破坏或丢失,那么就会陷入麻烦。同样的规则适用于冗余,但是当Kubernetes集群状态为动态时,大部分数据可能并不同步(非动态)。例如,许多历史数据往往很重要,可以备份和恢复;实时数据可能会丢失,但整个系统可能会恢复到早期版本,并且只受到暂时性的损坏。
4.2.5 运行冗余API服务器
API服务器是无状态的,从etcd集群中能获取所有必要的数据。这意味着可以轻松地运行多个API服务器,而不需要在它们之间进行协调。一旦有多个API服务器运行,就可以把负载均衡器放在它们之前,使其对用户透明。
4.2.6 用Kubernetes运行领导选举
一些主组件(如调度器和控制器管理器)不能同时具有多个实例。多个调度器试图将同一个Pod调度到多个节点或多次进入同一个节点将导致混乱。高度可扩展的Kubernetes集群可以让这些组件在领导者选举模式下运行。这意味着虽然多个实例在运行,但是每次只有一个实例是活动的,如果它失败,则另一个实例被选为领导者并代替它。
Kubernetes通过--leader-elect标志支持这种模式。调度器和控制器管理器可以通过将它们各自的清单复制到/etc/kubernetes/manifests来部署为Pod。
如下代码是调度器清单中的一个片段,它显示了标志的用法。
command:
- /bin/sh
- -c
- /usr/local/bin/kube-scheduler --master=127.0.0.1:8080 --v=2
--leader-elect=true 1>>/var/log/kube-scheduler.log
2>&1
如下代码是控制器管理器清单中的一个片段,它显示了标志的用法。
- command:
- /bin/sh
- -c
- /usr/local/bin/kube-controller-manager --master=127.0.0.1:8080
--cluster-name=e2e-test-bburns
--cluster-cidr=10.245.0.0/16 --allocate-node-cidrs=true --cloud-
provider=gce --service-account-private-key-file=/srv/kubernetes/server.
key
--v=2 --leader-elect=true 1>>/var/log/kube-controller-manager.log
2>&1
image: gcr.io/google_containers/kube-controller-manager:fda24638d51a4
8baa13c35337fcd4793
需要注意的是,这里无法像其他Pod那样由Kubernetes自动重新启动这些组件,因为这些组件负责重新启动失败Pod的Kubernetes组件,所以如果失败,它们就不能重新启动自己。此处必须有一个现成的组件来随时准备替换。
领导选举用于应用程序
领导选举对于应用程序也非常有用,但却很难实施。幸运的是,Kubernetes有巧妙的办法,它有一个文件化的程序,通过Google的Leader-elector容器来支持用户申请的领导人选举。基本概念是使用Kubernetes端点结合资源转换和注解。当将这个容器作为辅助工具耦合到应用程序Pod中时,用户将以非常流畅的方式获得领导人选举功能。
如下代码展示了用3个Pod和一个叫作election的选择程序来运行leader-elector。
> kubectl run leader-elector --image=gcr.io/google_containers/leader-
elector:0.4 --replicas=3 -- --election=election –http=0.0.0.0:4040
稍后,会看到集群上出现3个新的Pod,称为leader-elector-xxx,代码如下所示。
> kubectl get pods
NAME READY STATUS RESTARTS AGE
echo-3580479493-n66n4 1/1 Running 12 22d
leader-elector-916043122-10wjj 1/1 Running 0 8m
leader-elector-916043122-6tmn4 1/1 Running 0 8m
leader-elector-916043122-vui6f 1/1 Running 0 8m
但是哪个是主节点?如下代码演示了如何查询选举端点。
> kubectl get endpoints election -o json
{
"kind": "Endpoints",
"apiVersion": "v1",
"metadata": {
"name": "election",
"namespace": "default",
"selfLink": "/api/v1/namespaces/default/endpoints/election",
"uid": "48ffc442-b451-11e6-9db1-c2777b74ca9d",
"resourceVersion": "892261",
"creationTimestamp": "2016-11-27T03:26:29Z",
"annotations": {
"control-plane.alpha.kubernetes.io/leader":
"{\"holderIdentity\":\"leader-elector-916043122-10wjj\",\"leaseDura
tionSeconds\":10,\"acquireTime\":\"2016-11-27T03:26:29Z\",\"renewTi
me\":\"2016-11-27T03:38:02Z\",\"leaderTransitions\":0}"
}
},
"subsets": []
}如果上述过程相对较难,则可以在metadata.annotations中查阅更多内容。为了便于检测,我推荐使用jq程序进行切片和切割JSON。它对解析Kubernetes API或kubectl的输出非常有用,代码如下所示。
kubectl get endpoints election -o json | jq -r .metadata.annotations[]
| jq .holderIdentity
"leader-elector-916043122-10wjj"如下代码展示了如何删除领导,以证明选举的有效性。
kubectl delete pod leader-elector-916043122-10wjj
pod "leader-elector-916043122-10wjj" deleted这样,便有了一个新的领导,代码如下所示。
kubectl get endpoints election -o json | jq -r .metadata.annotations[]
| jq .holderIdentity
"leader-elector-916043122-6tmn4"还可以通过HTTP的方式找到领导,因为每个leader-elector容器通过运行在端口4 040的本地Web服务器公开领导。
Kubectl proxy
http http://localhost:8001/api/v1/proxy/namespaces/default/pods/
leader-elector-916043122-vui6f:4040/ | jq .name
"leader-elector-916043122-6tmn4"本地Web服务器允许leader-elector容器充当同一个Pod中的主应用程序容器的边车(sidecar)容器。由于应用程序容器与leader-elector容器共享相同的本地网络,因此它可以访问http://localhost:4040并获得当前领导的名称。只有与所选领导共享Pod的应用程序容器才会运行应用程序,其他Pod中的其他应用程序容器将处于休眠状态。如果它们收到请求,会转发给领导,并且一些负载均衡技巧可以自动将所有请求发送给当前的领导。
4.2.7 使预演环境高度可用
高可用性十分重要,如果遇到了设置高可用性的问题,那将意味着有一个高度可用系统的商业案例。因此,在将集群部署到生产环境之前(除非是在生产环境中进行测试的Netflix),需要测试可靠且高度可用的集群。此外,理论上对集群的任何更改都可能会破坏高可用性,而不会破坏其他集群功能。
默认用户需要测试可靠性和高可用性,那最好的方法便是创建一个可以尽可能地复制生产环境的预演环境,这可能会很昂贵,下面展示了几种控制成本的方案。
- Ad hoc HA预演环境:仅在HA测试期间创建一个大型HA集群。
- 压缩时间:提前创建有意义的事件流和场景,提供输入,并快速连续地模拟情境。
- 将HA测试与性能和压力测试相结合:在性能和压力测试结束时,对系统进行过载,并查看可靠性和高可用性配置如何处理负载。
4.2.8 测试高可用性
测试高可用性需要制定计划并对系统有深入理解。每个测试的目标是揭示系统设计和/或实现中的缺陷,并提供足够的覆盖范围,测试通过将能够保证系统按预期运行。
在可靠性和高可用性领域,这意味着需要找出破坏系统的方法,并将它们重新组合在一起观察效果。
这就需要以下几种方式。
- 全面列出可能出现的故障(包括合理的组合)。
- 对于每一个可能的故障,需要清楚系统应该如何应对。
- 一种诱发故障的方法。
- 一种观察系统反应的方法。
上述每种方式都很重要,根据以往经验,最好的方法是增量执行它,并尝试提出相对少量的通用故障类别和通用响应,而不是一个详尽的、不断变化的低级故障列表。
例如,一般故障类别是节点无响应的;一般响应可能是重新启动节点,导致故障的方式可能是停止节点的VM(如果它是VM),并且当节点停机时,系统仍然基于标准验收测试,节点最终上升,系统恢复正常。开发者可能还想测试许多其他内容,例如问题是否被记录、相关警报是否发给相应人员,以及是否更新了各种统计和报告。
需要注意的是,有时故障不能在单一的响应中解决。例如,在无响应节点的情况下,如果是硬件故障,那么重新启动将无济于事。在这种情况下,第二响应开始执行,也许是新的VM被启动、配置并连接到节点。在这种情况下,不能定义得太宽泛,可能需要为节点上特定类型的Pod/角色(etcd、Master、Worker、数据库、监控)创建测试。
如果有更高的要求,则要花费比生产环境更多的时间来设置适当的测试环境和测试。
最重要的一点是,尽量做到非侵入性。这意味着在理想情况下,生产系统将不具有允许关闭其部分功能或将其配置为以降低的测试容量运行的测试特性。原因是它增加了系统的攻击面,并且可能由于配置错误而意外触发。理想情况下,开发者可以控制测试环境,而不需要修改将在生产中部署的代码或配置。使用Kubernetes,通常很容易注入具有定制测试功能的Pod和容器,这些功能可以与生产环境中的系统组件交互,但永远不能在生产中部署。
本节介绍了拥有一个可靠和高可用的集群需要些什么(包括etcd、API服务器、调度器和控制器管理器),探讨了保护集群本身以及数据的最佳实践,并特别关注启动环境和测试的问题。
本文截选自《精通Kubernetes》第四章第4.2节。

- k8s初学者指南,针对K8s1.10,具备丰富实操案例
- 帮助读者掌握在各种云平台上设计和部署大型集群的技能
本书通过理论与实践相结合,全方位地介绍Kubernetes这一容器编排的理想工具。本书共14章,涉及的主题包括理解Kubernetes架构,创建Kubernetes集群,监控、日志记录和故障排除,高可用性和可靠性,配置Kubernetes安全、限制和账户,使用关键Kubernetes资源,管理Kubernetes存储,使用Kubernetes运行有状态应用程序,滚动更新、可伸缩性和配额,高级Kubernetes网络,在云平台和集群联邦中运行Kubernetes,自定义Kubernetes API和插件,操作Kubernetes软件包管理器以及Kubernetes的未来。本书综合考虑不同环境和用例,使读者了解如何创建大型系统并将其部署在Kubernetes上。在各章节主题中,读者提供了丰富的实践案例分析,娓娓道来,引人入胜。
本书可以作为Kubernetes的实践参考手册,聚焦于设计和管理Kubernetes集群,为开发人员、运维工程师详细介绍了Kubernetes所提供的功能和服务。