Spark Streaming源码解读之Job动态生成和深度思考
本博文主要包含以下内容:
1、 Spark Streaming Job 生成深度思考
2 、Spark Streaming Job 生成源码解析
一 :Spark Streaming Job 生成深度思考
输入的DStream有很多来源Kafka、Socket、Flume,输出的DStream其实是逻辑级别的Action,是Spark Streaming框架提出的,其底层翻译成为物理级别的Action,是RDD的Action,中间是处理过程是transformations,状态转换也就是业务处理逻辑的过程。
Spark Streaming二种数据来源:
1、基于DStream数据源。
2、基于其他DStream产生的数据源。
3、做大数据例如Hadoop,Spark等,如果不是流处理的话,一般会有定时任务。例如10分钟触发一次,1个小时触发一次,这就是做流处理的感觉,一切不是流处理,或者与流处理无关的数据都将是没有价值的数据,以前做批处理的时候其实也是隐形的在做流处理。
所以就有统一的抽象,所有处理都是流处理的方式,所有的处理都将会被纳入流处理。企业大型开发项目都有j2ee后台支撑来提供各种人操作大数据中心。
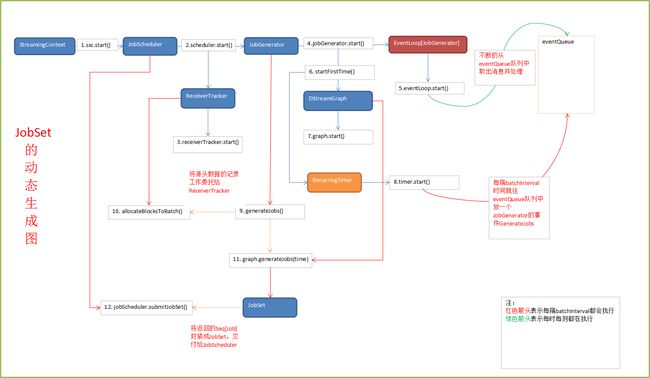
4、JobGenerator构造的时候有一个核心的参数是jobScheduler, jobScheduler是整个作业的生成和提交给集群的核心,JobGenerator会基于DStream生成Job。这里面的Job就相当于Java中线程要处理的Runnable里面的业务逻辑封装。Spark的Job就是运行的一个作业。
5、Spark Streaming除了基于定时操作以外参数Job,还可以通过各种聚合操作,或者基于状态的操作。
JobGenerator会基于DStream生成Job.
DStream
输入DStream: 数据可以有不同的输入来源来构建输入的DStream(例如,Kafka,Socket,Flume).
输出DStream: 逻辑级别的action.
Transformation DStream
6、每5秒钟JobGenerator都会产生Job,此时的Job是逻辑级别的,也就是说这个Job,并且说这个Job具体该怎么去做,此时并没有执行。具体执行的话是交给底层的RDD的action去触发,此时的action也是逻辑级别的。底层物理级别的,Spark Streaming他是基于DStream构建的依赖关系导致的Job是逻辑级别的,底层是基于RDD的逻辑级别的。
7、Spark Streaming的触发器是以时间为单位的,storm是以事件为触发器,也就是基于一个又一个record. Spark Streaming基于时间,这个时间是Batch Duractions
![]()
8、从逻辑级别翻译成物理级别,最后一个操作肯定是RDD的action,但是并不想一翻译立马就触发job。这个时候怎么办?
action触发作业,这个时候作为Runnable的接口封装,他会定义一个方法,这个方法里面是基于DStream的依赖关系生成的RDD。翻译的时候是将DStream的依赖关系翻译成RDD的依赖关系,由于DStream的依赖关系最后一个是action级别的,翻译成RDD的时候,RDD的最后一个操作也应该是action级别的,如果翻译的时候直接执行的话,就直接生成了Job,就没有所谓的队列,所以会将翻译的事件放到一个函数中或者一个方法中,因此,如果这个函数没有指定的action触发作业是执行不了的。
9、Spark Streaming根据时间不断的去管理我们的生成的作业,所以这个时候我们每个作业又有action级别的操作,这个action操作是对DStream进行逻辑级别的操作,他生成每个Job放到队列的时候,他一定会被翻译为RDD的操作,那基于RDD操作的最后一个一定是action级别的,如果翻译的话直接就是触发action的话整个Spark Streaming的Job就不受管理了。因此我们既要保证他的翻译,又要保证对他的管理,把DStream之间的依赖关系转变为RDD之间的依赖关系,最后一个DStream使得action的操作,翻译成一个RDD之间的action操作,整个翻译后的内容他是一块内容,他这一块内容是放在一个函数体中的,这个函数体,他有函数的定义,这个函数由于他只是定义还没有执行,所以他里面的RDD的action不会执行,不会触发Job,当我们的JobScheduler要调度Job的时候,转过来在线程池中拿出一条线程执行刚才的封装的方法。
二:Spark Streaming Job生成源码解析
下面主要从三个类进行解析:
- JobGenerator类:根据batchDuration及内部默认的时间间隔生成Jobs;
- JobScheduler:根据batchDuration负责Spark Streaming Job的调度;
- ReceiverTracker:负责Driver端元数据的接收和启动executor中的接收数据线程;
1、JobScheduler的start方法被调用的时候,会启动JobGenerator的start方法。
/** Start generation of jobs */
def start(): Unit = synchronized {
//eventLoop是消息循环体,因为不断的生成Job
if (eventLoop != null) return // generator has already been started
// Call checkpointWriter here to initialize it before eventLoop uses it to avoid a deadlock.
// See SPARK-10125
checkpointWriter
//匿名内部类
eventLoop = new EventLoop[JobGeneratorEvent]("JobGenerator") {
override protected def onReceive(event: JobGeneratorEvent): Unit = processEvent(event)
override protected def onError(e: Throwable): Unit = {
jobScheduler.reportError("Error in job generator", e)
}
}
//调用start方法。
eventLoop.start()
if (ssc.isCheckpointPresent) {
restart()
} else {
startFirstTime()
}
}EvenLoop: 的start方法被调用,首先会调用onstart方法。然后就启动线程。
/**
* An event loop to receive events from the caller and process all events in the event thread. It
* will start an exclusive event thread to process all events.
*
* Note: The event queue will grow indefinitely. So subclasses should make sure `onReceive` can
* handle events in time to avoid the potential OOM.
*/
private[spark] abstract class EventLoop[E](name: String) extends Logging {
private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]()
private val stopped = new AtomicBoolean(false)
//开启后台线程。
private val eventThread = new Thread(name) {
setDaemon(true)
override def run(): Unit = {
try {
//不断的从BlockQueue中拿消息。
while (!stopped.get) {
//线程的start方法调用就会不断的循环队列,而我们将消息放到eventQueue中。
val event = eventQueue.take()
try {
//
onReceive(event)
} catch {
case NonFatal(e) => {
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
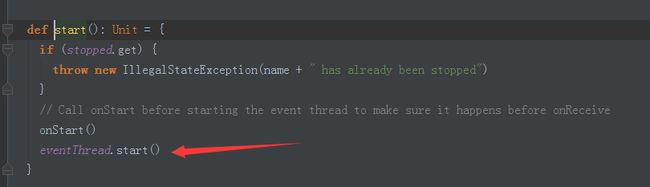
def start(): Unit = {
if (stopped.get) {
throw new IllegalStateException(name + " has already been stopped")
}
// Call onStart before starting the event thread to make sure it happens before onReceive
onStart()
eventThread.start()
}onReceive:不断的从消息队列中获得消息,一旦获得消息就会处理。
不要在onReceive中添加阻塞的消息,如果这样的话会不断的阻塞消息。
消息循环器一般都不会处理具体的业务逻辑,一般消息循环器发现消息以后都会将消息路由给其他的线程去处理。
/**
* Invoked in the event thread when polling events from the event queue.
*
* Note: Should avoid calling blocking actions in `onReceive`, or the event thread will be blocked
* and cannot process events in time. If you want to call some blocking actions, run them in
* another thread.
*/
protected def onReceive(event: E): Unit消息队列接收到事件后具体处理如下:
基于Batch Duractions生成Job,并完成checkpoint.
Job生成的5个步骤。
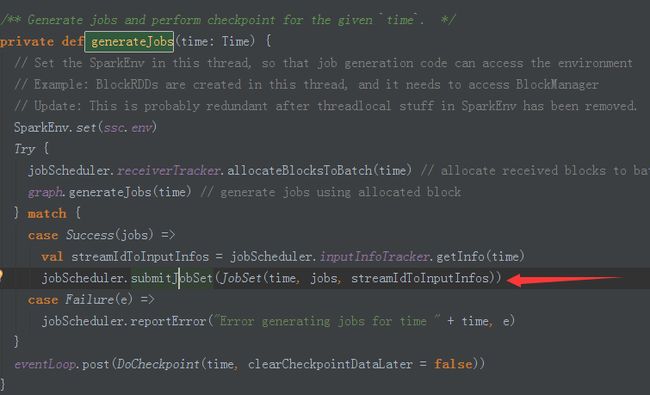
/** Generate jobs and perform checkpoint for the given `time`. */
private def generateJobs(time: Time) {
// Set the SparkEnv in this thread, so that job generation code can access the environment
// Example: BlockRDDs are created in this thread, and it needs to access BlockManager
// Update: This is probably redundant after threadlocal stuff in SparkEnv has been removed.
SparkEnv.set(ssc.env)
Try {
//第一步:获取当前时间段里面的数据。根据分配的时间来分配具体要处理的数据。
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
//第二步:生成Job,获取RDD的DAG依赖关系。在此基于DStream生成了RDD实例。
graph.generateJobs(time) // generate jobs using allocated block
} match {
case Success(jobs) =>
//第三步:获取streamIdToInputInfos的信息。BacthDuractions要处理的数据,以及我们要处理的业务逻辑。
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
//第四步:将生成的Job交给jobScheduler
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
}
//第五步:进行checkpoint
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
}此时的outputStream是整个DStream中的最后一个DStream,也就是foreachDStream.
def generateJobs(time: Time): Seq[Job] = {
logDebug("Generating jobs for time " + time)
val jobs = this.synchronized {
outputStreams.flatMap { outputStream =>
//根据最后一个DStream,然后根据时间生成Job.
val jobOption = outputStream.generateJob(time)
jobOption.foreach(_.setCallSite(outputStream.creationSite))
jobOption
}
}
logDebug("Generated " + jobs.length + " jobs for time " + time)
jobs
}此时的JobFunc就是我们前面提到的用函数封装了Job。
generateJob基于给定的时间生成Spark Streaming 的Job,这个方法会基于我们的DStream的操作物化成了RDD,由此可以看出,DStream是逻辑级别的,RDD是物理级别的。
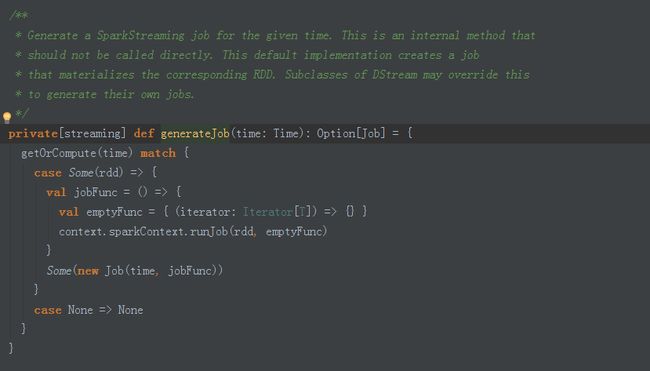
Job这个类就代表了Spark业务逻辑,可能包含很多Spark Jobs.
**
* Class representing a Spark computation. It may contain multiple Spark jobs.
*/
private[streaming]
class Job(val time: Time, func: () => _) {
private var _id: String = _
private var _outputOpId: Int = _
private var isSet = false
private var _result: Try[_] = null
private var _callSite: CallSite = null
private var _startTime: Option[Long] = None
private var _endTime: Option[Long] = None
def run() {
//调用func函数,此时这个func就是我们前面generateJob中的func
_result = Try(func())
}此时put函数中的RDD是最后一个RDD,虽然触发Job是基于时间,但是也是基于DStream的action的。
**
* Get the RDD corresponding to the given time; either retrieve it from cache
* or compute-and-cache it.
*/
private[streaming] final def getOrCompute(time: Time): Option[RDD[T]] = {
// If RDD was already generated, then retrieve it from HashMap,
// or else compute the RDD
//基于时间生成RDD
generatedRDDs.get(time).orElse {
// Compute the RDD if time is valid (e.g. correct time in a sliding window)
// of RDD generation, else generate nothing.
if (isTimeValid(time)) {
val rddOption = createRDDWithLocalProperties(time, displayInnerRDDOps = false) {
// Disable checks for existing output directories in jobs launched by the streaming
// scheduler, since we may need to write output to an existing directory during checkpoint
// recovery; see SPARK-4835 for more details. We need to have this call here because
// compute() might cause Spark jobs to be launched.
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
//
compute(time)
}
}
//然后对generated RDD进行checkpoint
rddOption.foreach { case newRDD =>
// Register the generated RDD for caching and checkpointing
if (storageLevel != StorageLevel.NONE) {
newRDD.persist(storageLevel)
logDebug(s"Persisting RDD ${newRDD.id} for time $time to $storageLevel")
}
if (checkpointDuration != null && (time - zeroTime).isMultipleOf(checkpointDuration)) {
newRDD.checkpoint()
logInfo(s"Marking RDD ${newRDD.id} for time $time for checkpointing")
}
//以时间为Key,RDD为Value,此时的RDD为最后一个RDD
generatedRDDs.put(time, newRDD)
}
rddOption
} else {
None
}
}
}回到JobGenerator中的start方法。
if (ssc.isCheckpointPresent) {
//如果不是第一次启动的话,就需要从checkpoint中恢复。
restart()
} else {
//否则的话,就是第一次启动。
startFirstTime()
}
}StartFirstTime的源码如下:
** Starts the generator for the first time */
private def startFirstTime() {
val startTime = new Time(timer.getStartTime())
//告诉DStreamGraph第一个Batch启动时间。
graph.start(startTime - graph.batchDuration)
//timer启动,整个job不断生成就开始了。
timer.start(startTime.milliseconds)
logInfo("Started JobGenerator at " + startTime)
}这里的timer是RecurringTimer。RecurringTimer的start方法会启动内置线程thread.

Timer.start源码如下:
**
* Start at the given start time.
*/
def start(startTime: Long): Long = synchronized {
nextTime = startTime //每次调用的
thread.start()
logInfo("Started timer for " + name + " at time " + nextTime)
nextTime
}调用thread启动后台进程。
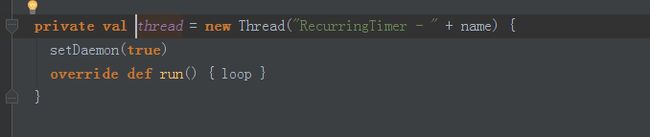
loop源码如下:
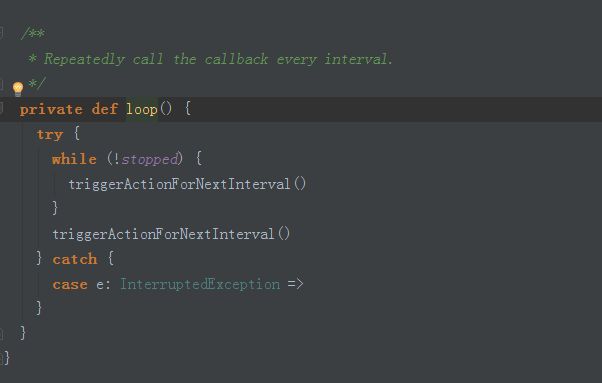
tiggerActionForNextInterval源码如下:
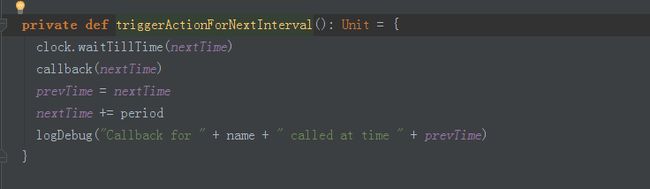
此时的callBack是RecurringTimer传入的。下面就去找callBack是谁传入的,这个时候就应该找RecurringTimer什么时候实例化的。
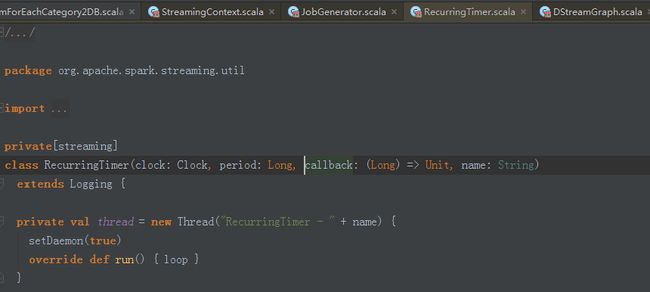
在jobGenerator中,匿名函数会随着时间不断的推移反复被调用。
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds,
//匿名函数,复制给callback。
longTime => eventLoop.post(GenerateJobs(new Time(longTime))), "JobGenerator")而此时的eventLoop就是JobGenerator的start方法中eventLoop.eventLoop是一个消息循环体当收到generateJobs,就会将消息放到线程池中去执行。
至此,就知道了基于时间怎么生成作业的流程就贯通了。
Job生成过程:
第四步:将生成的Job交给jobScheduler
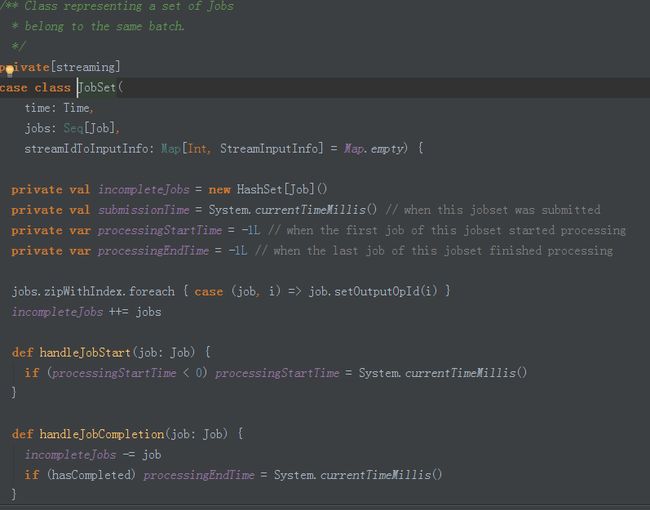
Jobs: 此时的jobs就是jobs的业务逻辑,就类似于RDD之间的依赖关系,保存最后一个job,然后根据依赖关系进行回溯。
streamIdToInputInfos:基于Batch Duractions以及要处理的业务逻辑,然后就生成了JobSet.
此时的JobSet就包含了数据以及对数据处理的业务逻辑。
submitJobSet:
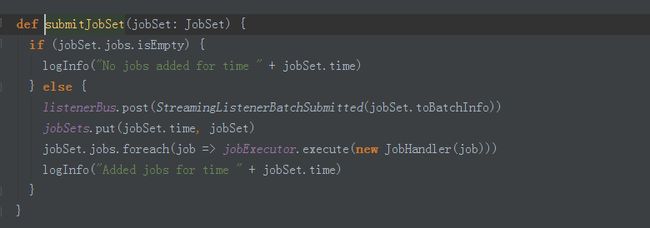
JobHandle是一个Runnable接口,Job就是我们业务逻辑,代表的就是一系列RDD的依赖关系,job.run方法就导致了func函数的调用。
private class JobHandler(job: Job) extends Runnable with Logging {
import JobScheduler._
def run() {
try {
val formattedTime = UIUtils.formatBatchTime(
job.time.milliseconds, ssc.graph.batchDuration.milliseconds, showYYYYMMSS = false)
val batchUrl = s"/streaming/batch/?id=${job.time.milliseconds}"
val batchLinkText = s"[output operation ${job.outputOpId}, batch time ${formattedTime}]"
ssc.sc.setJobDescription(
s"""Streaming job from $batchLinkText""")
ssc.sc.setLocalProperty(BATCH_TIME_PROPERTY_KEY, job.time.milliseconds.toString)
ssc.sc.setLocalProperty(OUTPUT_OP_ID_PROPERTY_KEY, job.outputOpId.toString)
// We need to assign `eventLoop` to a temp variable. Otherwise, because
// `JobScheduler.stop(false)` may set `eventLoop` to null when this method is running, then
// it's possible that when `post` is called, `eventLoop` happens to null.
var _eventLoop = eventLoop
if (_eventLoop != null) {
_eventLoop.post(JobStarted(job, clock.getTimeMillis()))
// Disable checks for existing output directories in jobs launched by the streaming
// scheduler, since we may need to write output to an existing directory during checkpoint
// recovery; see SPARK-4835 for more details.
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
//
job.run()
}
_eventLoop = eventLoop
if (_eventLoop != null) {
_eventLoop.post(JobCompleted(job, clock.getTimeMillis()))
}
} else {
// JobScheduler has been stopped.
}
} finally {
ssc.sc.setLocalProperty(JobScheduler.BATCH_TIME_PROPERTY_KEY, null)
ssc.sc.setLocalProperty(JobScheduler.OUTPUT_OP_ID_PROPERTY_KEY, null)
}
}
}
}此时job.run()的func就是基于DStream的业务逻辑。也就是RDD之间依赖的业务逻辑。

其中ThreadPoolExcutor.execute就会在线程池中执行JobHandler中的run方法。
/**
* Executes the given task sometime in the future. The task
* may execute in a new thread or in an existing pooled thread.
*
* If the task cannot be submitted for execution, either because this
* executor has been shutdown or because its capacity has been reached,
* the task is handled by the current {@code RejectedExecutionHandler}.
*
* @param command the task to execute
* @throws RejectedExecutionException at discretion of
* {@code RejectedExecutionHandler}, if the task
* cannot be accepted for execution
* @throws NullPointerException if {@code command} is null
*/
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}