Hadoop学习(十)——数据倾斜及案例汇总
笔者是一个痴迷于挖掘数据中的价值的学习人,希望在平日的工作学习中,挖掘数据的价值,找寻数据的秘密,笔者认为,数据的价值不仅仅只体现在企业中,个人也可以体会到数据的魅力,用技术力量探索行为密码,让大数据助跑每一个人,欢迎直筒们关注我的公众号,大家一起讨论数据中的那些有趣的事情。
我的公众号为:livandata

本文主要是对数据倾斜的一些问题以及前面的一些常见案例做一些汇总:
1、 解决数据倾斜思路
MapReduce本身是分布式程序,比如:一个程序在某个服务器上运行,将其中的一部分jar文件放在另一个服务器上,可以进行运行;
Wc.jar文件放在客户端,然后通过socket直接传给其他的服务器,然后再客户端运行wc.jar文件,让各个wc.jar文件在各个服务器上独立运行,然后再搭建一个服务器,将上面的服务器中的运行结果规整在一台服务器上,形成一个总的结果,然后再统计一次,形成一个最终的结果;

平时在运行时通过增加map的服务器,来增加运算量;
MapReduce本身就是一个分布式程序,因此他本身有客户端和服务端;
1) main函数即为MapReduce的客户端,其中有jobsubmitter,这个类负责将jar包(包括mapper、reducer、maptask、reducetask、inputformat等),这个jar包会被发布到各个服务器中,这些服务器有一个resourcemanager,和多个nodemanager,客户端一开始不知道改将jar文件发给谁,故先访问rm,rm给出资源的路径,客户端就会将jar包以及对应的配置文件,放置在对应服务器的目录下,上传时用到的方法为copyfromlocal方法;
2) 客户端上传到服务器,并决定副本量,保证每个机器上都有,这些资源上传给nm,此时会创建一个appmastercontext,(/bin/bash %PWD等启动程序的环境变量)用来请求程序运行,他会请求rm,并作为一个任务描述,放在rm的队列中,每个nm会定时到rm中请求任务,并形成一个container,将程序运行所需要的资源、jar文件、切片信息等放在container中,并启动程序;
3) 程序启动后,会根据切片文件来判断启动多少个maptask,他会到rm中请求多个container,用来运行多个maptask,此时会在rm队列中存在多个maptask任务,rm会根据各个nm的空闲情况,形成多个container,并分别放在多个空闲的服务器上,这些container在形成的时候会带有要处理的切片信息、运行信息等(这些信息由appmaster申请资源任务时定义完成),这时这些container中的maptask会反向寻找hdfs,找到需要的资源切片,rm中如果任务无处安放,则会等在队列中;
4) Container中的maptask运行完后会产生一个结果文件,当maptask全部运行完之后,APPmaster会再次请求rm,分配container,运行reducetask,这些reducetask会去找各个maptask,但是各个maptask已经销毁,所以reducetask会对应的去找nodemanager,nm会将maptask的处理结果给到reducetask,一般会拿到与map数量一致的文件,reduce会将map结果文件合并,并进行reduce处理,处理完后会将结果给到hdfs;

如果仔细查看可以发现,map中产生的数据用来进行分区,正常的分区是按照key来分区的,通常是按照哈希算法来进行,如果reduce有几个,那么分区就能分成几个;

在通常的生产过程中会产生数据倾斜的情况,比如小米手机买的特别好,但是锤子手机买的比较少,则小米和锤子分别被发在一个map中,两个reduce同时运行的时候,其中一个reduce就会运行的非常慢,导致数据倾斜;
上例中p00011比较多,用在了一个reduce中,另外一个p00001用在了另一个reduce中,导致相应的倾斜;
为什么会产生倾斜,因为我们需要将同一个pid拼接在一起,所以使用reduce,但是是否可以取消reduce,如果没有reduce,如何实现数据的拼接,
首先假如在一个maptask中有一个产品全表,每拿到一个产品信息其中必有一个pid,根据这个pid是否可以在自己的产品全表中拿到产品信息,然后再拼上来;
问题在于产品全表怎么给出:
把产品全表看成一个文件,放在服务器上,然后给每个服务器赋值一个文件,当各个map处理完成后,直接拼接在文件中,就完成了map的join工作,因此避免数据倾斜的一个方法为:去掉reduce;
但是问题在于需要将产品文件加载在服务器中才可以加载,而map的运行位置是随机分配的,且文件分配时map还没有形成工作目录,只有工作目录启动之后才会有container才会有编号,因此存在问题,该如何给maptask对应的工作目录:
一个方法为将文件放在redis中,但是这样是通过网络传输,比本地磁盘要慢,因此不常用,为此mapreduce提供了一个常用的分布式缓存机制distributedcache,我们可以将产品信息表放在distributedcache中,由这个cache在程序运行的时候,自动将文件发到maptask的工作目录中,然后再在maptask中调用cache中的文件即可。

Map端实现join编码:

![]()


此时就实现了map端的分析,去掉了reduce,解决了数据倾斜的问题。
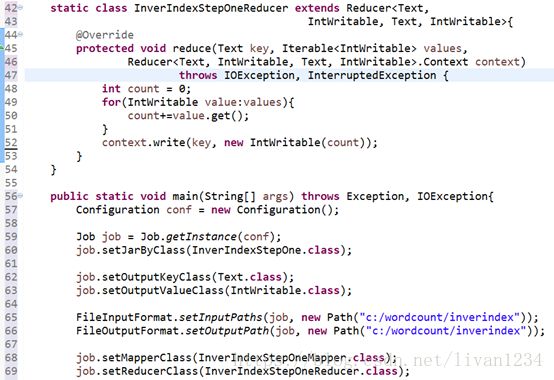
如何实现倒排索引:
有大量的文本(文档、网页),需要建立搜索索引;
对文档排序有两个地方需要注意:
1)分词:
2)统计每个词在每个文档出现的次数;
3)将这些数据放在一个文档中,作为索引文档;
假如有三个文件:

现在需要将这三个词统计出来:

具体的实现需要用mapreduce来实现:
Key一致的数据会进入到同一个reduce中;
思路:
将单词跟文件作为key,则单词跟文件的次数就会统计出来,供reduce计算;



执行结果为:

此时不是我们需要的结果,所以需要进行进一步处理:
因此需要建立第二个文件:



结果为:

2、 找出QQ共同好友:

求出哪些人两两之间有共同好友,及他俩的共同好友都有谁?
这一思路为:
1) 求c是哪些人的共同好友,将这些人拼起来,就可以找到有共同好友的人;
2) 然后再确定任意两个好友的共同好友;
3) 计算共同好友

代码为:



其运行结果为:

第二步中将value中的值两两拼接,对于value中的值需要先进性排序,主要是为了避免c-b和b-c这样的重复:



输出结果为:

3、 web日志处理:
对下面的内容进行处理:

思路:
1) 首先过滤掉js等文件记录;
2) 对时间进行处理,统一成一个格式,便于处理;
3) 字段与字段之间的分隔符统一;






另外一个解析类为:WebLogParser



主文件为:



处理完结果为:

因此需要在map中添加一个静态方法:

形成一个可以插拔的过滤方法;此时网站规划时需要进行对应的处理;
4、 使用groupingcomparator求同一订单中最大金额的订单

确定出各个订单中的最大交易;
效率比较低的方式为:
1) 以id作为key,传给reduce;
2) 在reduce中进行排序,找到最大值;
但是这一方法效率比较低,因为需要将数据拿到reduce中进行缓存;另外一个方法效率比较高:
排序的工作由框架完成,将金额的bean放在框架中作为key来传,金额放在bean中,bean放在key中;
思路:

1)每条记录中“订单”、“商品”、“金额”作为一个bean,这三个为其中的三个字段;如何将同一个订单传入到一个reduce中,将其写入到一个partition中(partitional.getpartitional(bean.orderid)),进而传入到同一个reduce中,在reduce中传入同一个订单的多个bean;
订单id相同的这些bean会进入到同一个reduce中,
2)每个partition中根据bean的compare方法来进行排序,将金额最大的放前面;将这些bean传给reduce,bean作为key,null为value;
3) Reduce中一次调用一个(k,value)值,此时reduce只会取第一个值,因此统计出现问题,此时有一个方法,将不同的bean定义为一致,将数据同时传给reduce,value会通过一个迭代器取值,此处没有用处,顾可以不考虑;
4) 此方法为非常规用法;
5) 那么如果将不相同的bean作为一组传给reduce,此时用到了groupingcompatator方法;
这一方法为:

5、流量日志增强—自定义outputformat:

对日志做增强,需要用到MapReduce,每读一条就将url切出来,匹配知识库,如果知识库中有url的内容,则将其拿过来追加到本行的后面,然后计入到新的文件中,此时需要用到新的文件,新的文件中存在原始内容和新的内容;

如果匹配不到,则写道另外一个文件中,在hdfs上叫做“增强后的日志”;

代码为:


Dbloader:



LogEnHanceOutputFormat:




6、小文件处理:自定义inputformat:

如果有多个文件服务器,如何自定义inputformat,来导入个性化的文件:
1) 首先定义一个切片,将小文件合并成一个整体文件,以一个大文件输出;
2) 一个小文件的文件名为key,然后文件的内容为value;

每个小文件作为value写入到map中,然后通过context.write(文件名,文件内容bytes)写出去,假如只有一个reduce,则会全部到reduce中,在reduce中处理完成后,然后定义一个sequenceOutputformat,将文件数据传出,进入到一个文件中,然后再通过sequenceinputformat。

此时问题也还是有的,如果数据过大,reduce有可能数据过大;




转换格式:

转换主内容:



多个job串联如何使用:


![]()
