hbase通过mapreduce进行数据导入迁移报错
说在文前,本人菜鸟一只,要是文中有什么说的不对的话,请大家批评指正~!!
hbase有这样的功能,通过mapreduce进行数据导入或者迁移(也可以自己编码的,在Windows上编码也会有点报错,具体看我另一篇文章,里面的代码是个数据迁移的功能)。
执行hbase/lib包下面的hbase-server-0.98.6-hadoop2.jar这个jar包里面有些类可以供我们直接使用。例如:
CellCounter: Count cells in HBase table //统计cell个数
completebulkload: Complete a bulk data load.
copytable: Export a table from local cluster to peer cluster
export: Write table data to HDFS.
import: Import data written by Export.
importtsv: Import data in TSV format.
rowcounter: Count rows in HBase table //统计rowkey的个数
verifyrep: Compare the data from tables in two different clusters. WARNING: It doesn't work for incrementColumnValues'd cells since the timestamp is changed after being appended to the log.Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/hbase/filter/Filter
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2570)
at java.lang.Class.getMethod0(Class.java:2813)
at java.lang.Class.getMethod(Class.java:1663)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.(ProgramDriver.java:60)
at org.apache.hadoop.util.ProgramDriver.addClass(ProgramDriver.java:104)
at org.apache.hadoop.hbase.mapreduce.Driver.main(Driver.java:39)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hbase.filter.Filter
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
... 12 more
所以有两种办法,一种是临时生效,一种是永久生效,其实处理方法都是一样的
第一种(临时生效):
HBase已经想到你会遇到这样的问题,所以他也告诉你需要哪些jar包,我们通过bin/hbase mapredcp这个命令就可以知道(这里的cp是classpath的意思)
那就是下面这些:
/opt/modules/hbase-0.98.6-hadoop2/lib/hbase-common-0.98.6-hadoop2.jar:/opt/modules/hbase-0.98.6-hadoop2/lib/protobuf-java-2.5.0.jar:/opt/modules/hbase-0.98.6-hadoop2/lib/hbase-client-0.98.6-hadoop2.jar:/opt/modules/hbase-0.98.6-hadoop2/lib/hbase-hadoop-compat-0.98.6-hadoop2.jar:/opt/modules/hbase-0.98.6-hadoop2/lib/hbase-server-0.98.6-hadoop2.jar:/opt/modules/hbase-0.98.6-hadoop2/lib/hbase-protocol-0.98.6-hadoop2.jar:/opt/modules/hbase-0.98.6-hadoop2/lib/high-scale-lib-1.1.1.jar:/opt/modules/hbase-0.98.6-hadoop2/lib/zookeeper-3.4.5.jar:/opt/modules/hbase-0.98.6-hadoop2/lib/guava-12.0.1.jar:/opt/modules/hbase-0.98.6-hadoop2/lib/htrace-core-2.04.jar:/opt/modules/hbase-0.98.6-hadoop2/lib/netty-3.6.6.Final.jar
export HADOOP
_HOME=/opt/modules/hadoop-2.5.0
export HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2
export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`$HADOOP_HOME/bin/yarn jar $HBASE_HOME/lib/hbase-server-0.98.6-hadoop2.jar
export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`$HADOOP_HOME/bin/yarn jar $HBASE_HOME/lib/hbase-server-0.98.6-hadoop2.jar
以上总共3行,在任意窗口输入前两行,然后通过第三行的方式去执行jar包,这个是临时的方法,但是。。。大家还是喜欢永久的。
第二种(永久生效):
其实永久生效就是把刚才那些配置写到hadoop-env.sh里面,让hadoop启动的时候自动读取这些包
我们修改hadoop-env.sh如下(不过我这里的方法是读取全部hbase里面的lib):
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
export JAVA_HOME=/opt/modules/jdk1.7.0_67
export HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2
export HADOOP_CLASSPATH=$HBASE_HOME/lib/*
# The jsvc implementation to use. Jsvc is required to run secure datanodes.
#export JSVC_HOME=${JSVC_HOME}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
# Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=/opt/modules/apache-hive-0.13.1-bin/conf:$HADOOP_CLASSPATH
else
export HADOOP_CLASSPATH=$f
fi
done
# The maximum amount of heap to use, in MB. Default is 1000.
#export HADOOP_HEAPSIZE=
#export HADOOP_NAMENODE_INIT_HEAPSIZE=""
# Extra Java runtime options. Empty by default.
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
#HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS"
# On secure datanodes, user to run the datanode as after dropping privileges
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
# Where log files are stored. $HADOOP_HOME/logs by default.
#export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER
# Where log files are stored in the secure data environment.
export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
# The directory where pid files are stored. /tmp by default.
# NOTE: this should be set to a directory that can only be written to by
# the user that will run the hadoop daemons. Otherwise there is the
# potential for a symlink attack.
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
# A string representing this instance of hadoop. $USER by default.
export HADOOP_IDENT_STRING=$USER
改成这样,要记得重启一下hadoop的相关服务,然后直接$HADOOP_HOME/bin/yarn jar $HBASE_HOME/lib/hbase-server-0.98.6-hadoop2.jar就可以了
成功结果如下图:
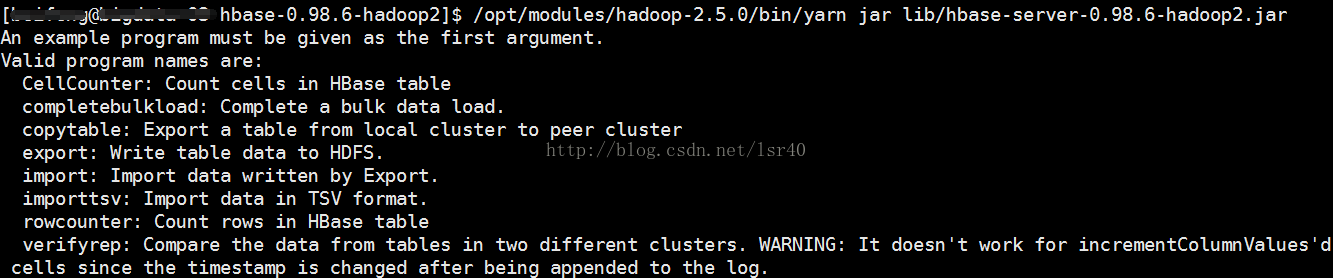
好了搞定~
然后,我居然发现我的hive不能用了。。。。我突然觉得自己仿佛一个智障=。=!
[test@bigdata-03 apache-hive-0.13.1-bin]$ bin/hive
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/hive/conf/HiveConf
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at org.apache.hadoop.util.RunJar.main(RunJar.java:205)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
... 3 more
其实是大概是hive的一些类啊配置啊没读到,我也是个菜鸡,你要我说出具体是什么错,我讲不明白。不过我把这个报错改好了~
在上面我有给出我的hadoop-env.sh,主要修改这个地方!!!(我标红了,就是添加标红色的地方)
export JAVA_HOME=/opt/modules/jdk1.7.0_67
export HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2
export HADOOP_CLASSPATH= $HADOOP_CLASSPATH:$HBASE_HOME/lib/*
export HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2
export HADOOP_CLASSPATH= $HADOOP_CLASSPATH:$HBASE_HOME/lib/*
然后重启hadoop的服务,这时候hbase也没问题,hive也没问题了!!!