YARN与Zookeeper区别及联系
YARN和Zookpeer都是为了解决什么问题而产生的,应用场景分别是什么,如何结合使用等等问题,估计很多人和我以前一样,有着比较深的困惑,而这些困惑,也许你自己花那么一些时间去搭建目前流行的大数据系统,可能就豁然开朗了。或许,你可以看看网上别人怎么说,看看官网的架构图及其解释,再加上自己以往的经验,也能看到它们的本质,当然,如果要使用,很多坑在等你跳,记住,跳坑是必经之路,没有人能替你完成。
首先来看一张YARN的架构图:
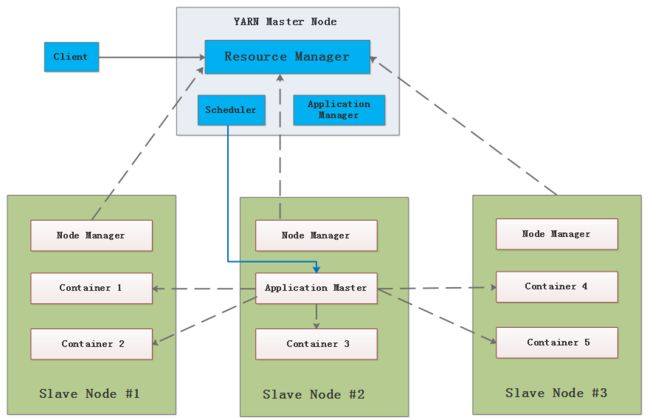
我们来解释一下这张图的步骤:
第一步:客户端提交任务(MapReduce, Java应用,Apache Spark任务等)到ResourceManager,同时传递一个命令,用于在NodeManager节点中启动任意一个container来运行ApplicationMaster;
第二步:Master节点上的ApplicationManager验证Job请求,然后传递给Scheduler进程进行资源分配;
第三步:Scheduler进程从某个Slave节点分配一个container来运行ApplicationMaster;
第四步: NodeManager后台进程在其中一个container中启动ApplicationMaster,使用第一步传递过来的命令。ApplicationMaster于是成为了任何应用的第一个container;
第五步: ApplicationMaster将数据的位置(如保存着哪个Slave节点上)、所需CPU、内存量等信息提供给ResourceManager,与其协商如何分配其他container;
第六步: ReourceManager在Slave节点中进行最合理的资源分配,然后将节点详细信息等返回给ApplicationMaster;
第七步: 然后,ApplicationMaster将请求(如建议在哪个Slave上启动container)发给NodeManagers;
第八步: ApplicationMaster管理所请求container运行时的资源使用情况,并在任务完成后通知ResourceManager;
第九步: NodeManagers周期性地将自身的状态(如可使用资源情况)通知ResourceManager,作为Scheduler在集群中协调新应用的依据;
第十步: 任意一个Slave节点失败时,ResourceManager会试图在一个最合适的Slave节点上分配一个新的container,这样ApplicationMaster可使用新的container继续工作下去;
再看另一张图:
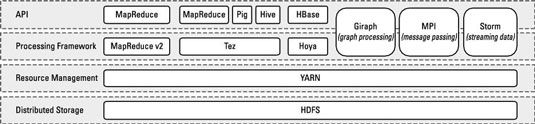
可以看到,HDFS是分布式存储,YARN是资源管理器,MapReduce等一些东西属于处理框架。有童鞋不禁要问了,如果没有YARN,Hadoop还能转吗?当然了,YARN是Hadoop V2才引入的,Hadoop V1的时候,通过JobTracker和TaskTracker来协调资源,然而人们发现,JobTracker做了太多的事情,以致于它快撑不住。怎么办呢,刚刚好,YARN过来拯救它了。更具体的,还是建议去对比下Hadoop不同版本的架构图。
上面这张图里没有Zookeeper,Zookeeper又是干嘛的呀?我从这里看到一些解释,感觉蛮不错,翻译过来大意就是:
因此,YARN是从资源分配和调度的角度进行集群的管理,Zookeeper则干别的事情:作为一个中心配置服务,维护配置信息、名称服务、分布式同步、组服务等。Zookeeper本身也是一个有着3、5个节点的集群,它并不管理其他集群,从表面上看像个数据库,允许读写,并保持一致性的(从CAP的角度看,它是一个CP系统)。
那么它们的关系就是: YARN本身使用了一个HA的变种,在这个HA的设置中,自动故障处理(Automatic failover,包含选主) 是通过Zookeeper来实现的。那这个自动故障处理是如何通过Zookeeper工作的呢?(我们假设不局限于YARN,可以是其他的集群):你可以想象,在Zookeeper中,有一项信息“what yarn nodes are there”,答案也许是0(糟,挂掉了)、1(OK,起来了)、2(不错,现在列表中的第一个节点是YARN Master,另外一个节点作为Standby,等待Failover,平时它就从Master节点同步更新的信息)。这只是关于选主的一个例子:节点列表中的第一个节点作为Master。可见,Zookeeper为分布式系统提供了一个分布式配置服务,一个同步服务和一个名字注册表,很多后台daemons(包括YARN)使用它来管理多节点以实现集群的高可用。
到这里,你是被整懵了还是击节赞叹:“靠,原来这样…”,不管怎样,我再给你献上一张大图吧,这是从网上弄下来的图,这张图虽然展现的是HDFS的HA架构使用Zookeeper的情况,这和YARN使用Zookeeper的原理是一样一样的:
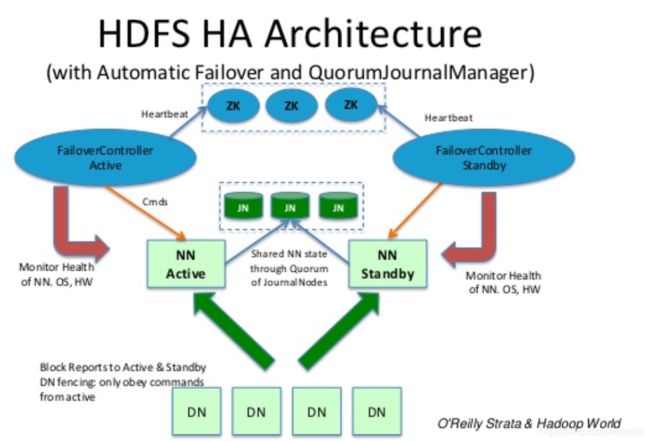
可以看到,HDFS的HA架构中,HA是通过Zookeeper来实现的,Zookeeper做的事情就是选择正确的Node来作为Active Name Node,也就是上文中提到的选主问题,防止脑裂。关于选主的算法,比较有名的是Paxos算法,我几年前也试图学习过一阵子,并写有一文在此:Paxos协议
这篇文章,严重参考了网上的博客文章等资料,有些图也是拿过来用的,在此非常感谢那些那些作者,这些链接如下,排名不分先后,哈哈。
YARN Architecture and Components
The YARN Architecture in Hadoop
What is Hadoop YARN Resource Manager?
What is the relationship between YARN and ZooKeeper, which both manage a cluster of nodes?
How does Hadoop Namenode failover process works?
hadoop+zookeeper+yarn搭建高可用完全分布式环境详细步骤
摘自 https://www.nndev.cn/archives/669