elasticsearch -基于hdfs的快照
概要:
首先了解什么是快照,所谓的快照就是对es中的数据进行的镜像copy,当es集群因为硬件故障或者是不可恢复的原因,导致重要数据全部丢失,在这种时候我们在某些情况下无法重新索引数据,此时就可以重新配置一个集群,然后用es之前保存的快照进行数据的恢复。
快照版本之间兼容事项:
快照包含组成索引的磁盘上数据结构的副本。这意味着快照只能还原到可以读取索引的Elasticsearch版本:
- 在6.x中创建的索引快照可以恢复到7.x。
- 在5.x中创建的索引快照可以恢复到6.x。
- 在2.x中创建的索引快照可以恢复到5.x。
- 可以将在1.x中创建的索引快照恢复到2.x。
相反,无法将在1.x中创建的索引快照还原到5.x或6.x,无法将在2.x中创建的索引快照还原到6.x或7.x,并且将快照在5中创建。 x 无法还原到7.x。
每个快照可以包含在各种版本的Elasticsearch中创建的索引,并且在还原快照时,必须有可能将所有索引还原到目标集群中。如果快照中的任何索引是在不兼容的版本中创建的,则将无法还原快照。
环境:
在我的环境中,我的es集群是7.2版本,hadoop版本是2.7.4,本文主要讲解es基于hdfs的快照,至于其他的共享文件系统方式请参考官网,原理大致一样,都是通过将es的数据通过网络的方式迁移到一个公共的网络存储空间之中。另外注意,快照是增量备份的,比如index1,我今天备份之后,明天执行同样的备份命令,那么只会copy一天中的增量到仓库中。
环境安装:
要执行hdfs备份快照,假定你已经拥有hadoop集群和es集群,接下来需要在每一个es节点安装插件:

等待安装完成之后就可以用了。
在kibana中测试:
1.创建仓库 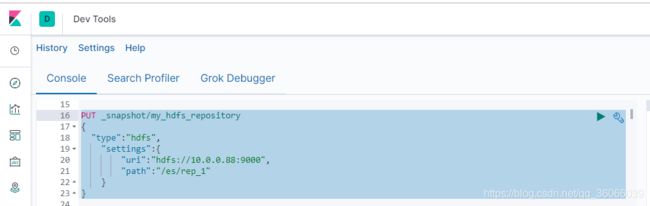
PUT _snapshot/my_hdfs_repository
{
"type":"hdfs",
"settings":{
"uri":"hdfs://10.0.0.88:9000",
"path":"/es/rep_1"
}
}
my_hdfs_repository是仓库的名称
"uri":"hdfs://10.0.0.88:9000" 是hdfs的入口
"path":"/es/rep_1 是仓库在hdfs的存储位置
2.在仓库中创建快照
PUT _snapshot/my_hdfs_repository/snapshot_1?wait_for_completion=true
{
"indices": "cdr-2019-4-10",
"ignore_unavailable": true,
"include_global_state": false,
"partial": true
}3.从快照中恢复数据到新的索引
POST /_snapshot/my_hdfs_repository/snapshot_1/_restore?wait_for_completion=true
{
"indices": "cdr-2019-4-10",
"rename_pattern": "cdr-(.+)",
"rename_replacement": "restored_index_$1"
}
除此之外,在跨集群还原索引快照的时候,我们需要在目标集群中创建与原始集群具体相同名称的存储库。例如原来的集群是,
PUT _snapshot/my_hdfs_repository
{
"type":"hdfs",
"settings":{
"uri":"hdfs://10.0.0.88:9000",
"path":"/es/rep_1"
}
}
如上述命令所示,假设我们在原始集群中创建了名为my_hdfs_repository的存储库,并且想将其存储的索引快照还原到目标集群,则需要在目标集群中创建如下存储库:
PUT _snapshot/my_hdfs_repository
{
"type":"hdfs",
"settings":{
"uri":"hdfs://10.0.0.99:9000",
"path":"/es/rep_1"
}
}
最后在新的集群上:
POST /_snapshot/my_hdfs_repository/snapshot_1/_restore?wait_for_completion=true
{
"indices": "cdr-2019-4-10",
"rename_pattern": "cdr-(.+)",
"rename_replacement": "restored_index_$1"
}