java集合整理 List源码解析
数组:
/**
* 数组大小固定,存储有序(存和取顺序一直)
* 直接打印输出对象需要重写toString()方法,否则会调用父类的toString()打印的是引用地址值
*/
Student[] students = new Student[5];
students[0] = new Student("张三", 1);
students[1] = new Student("李四", 2);
students[2] = new Student("王五", 3);
students[3] = new Student("赵六", 4);
Arrays.asList(students).forEach(b -> System.out.println(b));结果:
Student [name=张三, age=1]
Student [name=李四, age=2]
Student [name=王五, age=3]
Student [name=赵六, age=4]
null单列集合
/**
* Collection 单列集合跟根接口 ->List,Set;
* List子类:
* List->ArrayList(数组),List->LinkedList(链表实现),List->Vector(数组)
* Set子类:
* Set->HashSet(hash算法),Set->LinkedSet (链表)
*/
@SuppressWarnings("rawtypes")
Collection c =new ArrayList();
boolean add = c.add(1);
boolean add2 = c.add(new Student("张三", 1));
boolean add3 = c.add("c");
boolean add4 = c.add("c");
c.forEach(System.err::println);结果:
1
Student [name=张三, age=1]
c
c上图可以看出:ArrayList是存取有序,而且对于自定义类Student打印的是属性,并没有打印地址值,所以肯定重写了toString方法,在其父类的父类AbstractCollection找到了重写的toString,
public String toString() {
Iterator it = iterator();
//不存在返回[]
if (! it.hasNext())
return "[]";
StringBuilder sb = new StringBuilder();
sb.append('[');
//循环追加
for (;;) {
E e = it.next();
sb.append(e == this ? "(this Collection)" : e);
if (! it.hasNext())
return sb.append(']').toString();
sb.append(',').append(' ');
}
} ArrayList的add()方法返回值为boolean类型,这么做的原因是因为在List,Set的父级接口Collection为了区分这两个子接口能不能存储重复元素而设定的。如果在Set中存了相同的元素,那么就会返回false;而List的设定是可以存储相同元素的,所以一直返回true以下是List中的add()方法。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}迭代器源码解读:
public interface Iterator {
/**
* Returns {@code true} if the iteration has more elements.
* (In other words, returns {@code true} if {@link #next} would
* return an element rather than throwing an exception.)
*
* @return {@code true} if the iteration has more elements
*/
boolean hasNext();
/**
* Returns the next element in the iteration.
*
* @return the next element in the iteration
* @throws NoSuchElementException if the iteration has no more elements
*/
E next();
}
以上是迭代器的顶级接口,我这里贴了两个方法,然后我们的单列集合的接口Collection继承了该接口,不光是单列集合还有我们后续的Map等都继承了该接口,可自行去查api.这么做便于我们特定的子类,来实现自己特定的遍历方式,以ArrayList为例
/**
* Returns an iterator over the elements in this list in proper sequence.
*
* The returned iterator is fail-fast.
*
* @return an iterator over the elements in this list in proper sequence
*/
public Iterator iterator() {
return new Itr();
}
/**
* An optimized version of AbstractList.Itr
*/
private class Itr implements Iterator<E> {
int cursor; // 当前指针起始位0
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
//根据当前元素,跟集合大小判断是否继续进行遍历
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
} 上述代码中ArrayList通过内部类重写了自己的hasNext(),next()等方法。
LinkedList与Arraylist比较:
我们都知道List查询,修改比较快是因为List实现实现方式是数组,通过索引来查询,相对来说比较快。相反增删比较慢。
下图是没增删前的数组,

现在在索引1的位置将B替换为f,替换后的结果图

因此我们可以看到替换索引位置1的时候我们需要将原有的b,c,d,e整体向后移动,再进行替换,删除也是一样。所以花费的时间相对来说比较久。
而链表的方式增删却快很多例如没修改前依次连接A,B,C,D
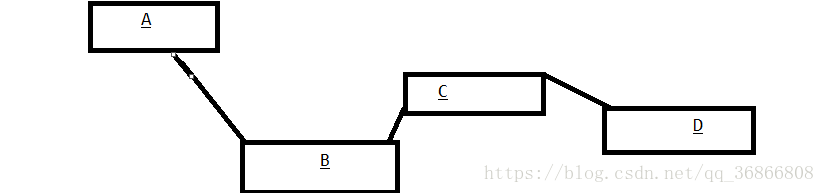
现在我们要在A,B之间添加一个元素F,只需将A,B之间的链接断开从新加入F,其他元素不需要修改
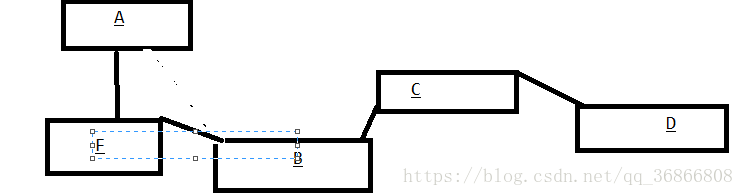
而链表方式查询慢的原因是因为当我们查询链表中的某个元素时都需要从头开始,或从尾部。比如查询C,先判断C离尾部比较近,所以从尾部的D开始查询,挨个去遍历所以查询的速度相对比较慢。修改也同理,需要先找到该元素再进行修改。
为了更好的印证我们来看LinkedList源码是如何进行查找元素
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}乍一看,像是通过索引查找,其实不然
/**
* Returns the (non-null) Node at the specified element index.
*/
Node node(int index) {
// assert isElementIndex(index);
//这行代码是判断我们当前元素距离头补近还是距离尾部近,链表长度右移两位,相当于除以2
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
//如果距离头部近向后移动
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
//如果距离尾部近向前移动
x = x.prev;
return x;
}
} 因此我们可以看出,链表查询的速度相对于数组来说慢了很多。而数据结构因为存在索引所以查询和修改相对快些。
ArrayList去除自定义对象重复元素
通过上面的解释骂我们已经知道List可以存储相同的元素,但有时候需要我们来去掉这些相同的元素,一般的做法就是判断从新定义一个集合来收集筛选后的结果
Student[] students = new Student[5];
students[0] = new Student("张三", 22);
students[1] = new Student("张三", 22);
students[2] = new Student("王五", 3);
students[3] = new Student("赵六", 4);
/*Arrays.asList(students).forEach(b -> System.out.println(b));*/
Arrays.asList(students).parallelStream().distinct().collect(Collectors.toList()).forEach(b -> System.out.println(b));
List list =new ArrayList();
list.add("a");
list.add("a");
list.add("b");
list.add("c");
((ArrayList) list.parallelStream().distinct().collect(Collectors.toList())).forEach(b -> System.err.println(b));结果:
Student [name=张三, age=22]
Student [name=张三, age=22]
Student [name=王五, age=3]
Student [name=赵六, age=4]
null
a
b
c我们可以看到String类型通过了筛选,而自定义类Student没有通过筛选,依然存储的是相同元素。
以下是ArrayList中的判断当前元素 是否属于集合的方法
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
public boolean equals(Object obj) {
return (this == obj);
}
最后我们定位到ArrayList中的equals(Object obj)方法,发现其并没有重写,所以比较的还是当前传入元素的引用,虽然Student的name,age属性一致。但在堆中存储在不同的地方。因此我们需要重写其equals 方法。