Hadoop:详解HDFS启动过程及相关节点工作机制(检查点机制、安全模式)
目录
namenode
HDFS启动流程
检查点机制
secondarynamenode
datanode
安全模式
namenode
Namenode是集群主从结构模型中的唯一的一个管理者,它负责
管理HDFS文件系统的命名空间(namespace):文件系统树及整棵树内的所有文件和目录的元数据,而这些信息以两种文件形式持久化地保存在本地磁盘中;
- 管理数据块位置信息:命名空间镜像文件(fsimage)
- 管理着客户端的读写操作:编辑日志文件(editlog)
同时namenode维护了块到datanode的映射,即每个文件各个块所在的数据节点信息,但这些信息保存在内存中,因为系统启动时会根据datanode信息重建映射信息
在一个搭建完hadoop分布式系统环境中,master机格式化namenode(hdfs namenode -format)之后,会在${hadoop.tmp.dir}中创建一个dfs目录,该目录下有一个子目录name
dfs
└── name
└── current
├── fsimage_0000000000000000000
├── fsimage_0000000000000000000.md5
├── seen_txid
└── VERSION
此时seen_txid的值为0,指的是第一个事务id
VERSION文件是一个Java属性文件,其中包含了正在运行的HDFS的版本信息:
namespaceID=993725495
clusterID=CID-22525aba-a03e-4ad4-9440-71f76baf37f6
cTime=0
storageType=NAME_NODE
blockpoolID=BP-163740078-192.168.80.120-1554104956001
layoutVersion=-63- namespaceID:文件系统命名空间的唯一标识符,是在namenode首次格式化时创建的
- clusterID:将HDFS集群作为一个整体赋予的唯一标识符
- cTime:标记了namenode存储系统的创建时间,对于刚格式化的存储系统此属性为0,文件系统升级后会更新到新的时间戳
- storageType:说明了该存储目录包含的数据结构
- blockpoolID:数据块池的唯一标识符,数据块池中包含了由一个namenode管理的命名空间中的所有文件
- layoutVersion:描述HDFS持久性数据结构(布局)的版本,此版本号与Hadoop发布包的版本号无关;只要布局发生变化,版本号就会递减,此时HDFS也需要升级,因为磁盘仍然使用旧版本的布局会导致新版本的namenode,datanode无法正常工作。
此时只有镜像文件而无编辑日志文件,可以通过以下命令下载fsimage文件转化为xml格式到本地并查看:
[jinge@master1 current]$ hdfs oiv -i fsimage_0000000000000000000 -o fi0.xml -p XML
选项解析:
-i,--inputFile
:要处理的镜像文件
-o,--outputFile:输出文件的名称;如果指定的文件存在,它将被覆盖
-p,--processor:选择要应用于镜像文件的处理器类型 (XML|FileDistribution|Web|Delimited) oiv中的i指定了image文件,如果下载编辑日志文件使用oev
fsimage保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。对于文件来说包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等
fsimage_0000000000000000000:
1000
1000
0
1073741824
0
16385
16385
DIRECTORY
0
jinge:supergroup:rwxr-xr-x
9223372036854775807
-1
0
16385
0
0
1
HDFS启动流程
此时开启HDFS(start-dfs.sh),可以在网页端查看启动过程
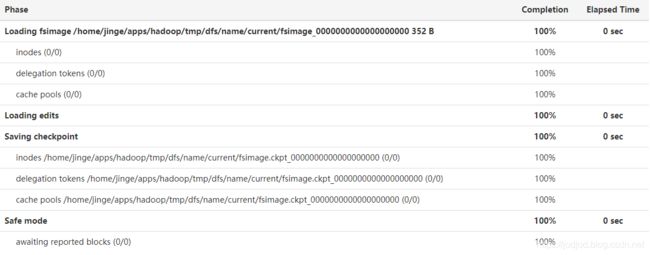
可见启动hdfs过程有4步:
- 加载文件系统镜像文件
- 加载编辑日志文件
- 设置检查点
- 安全模式
而刚格式化的系统中没有编辑日志文件,只加载了最新的fsimage_0000000000000000000镜像文件,并且通过辅助namenode设置了检查点,由于datanode中还没有数据所以安全模式时间为0秒
此时dfs目录中也多了secondarynamenode目录
dfs
├── name
│ ├── current
│ │ ├── edits_0000000000000000001-0000000000000000002
│ │ ├── edits_inprogress_0000000000000000003
│ │ ├── fi0.xml
│ │ ├── fsimage_0000000000000000000
│ │ ├── fsimage_0000000000000000000.md5
│ │ ├── fsimage_0000000000000000002
│ │ ├── fsimage_0000000000000000002.md5
│ │ ├── seen_txid
│ │ └── VERSION
│ └── in_use.lock
└── namesecondary
├── current
│ ├── edits_0000000000000000001-0000000000000000002
│ ├── fsimage_0000000000000000000
│ ├── fsimage_0000000000000000000.md5
│ ├── fsimage_0000000000000000002
│ ├── fsimage_0000000000000000002.md5
│ └── VERSION
└── in_use.lock
in_use.lock是一个锁文件,namenode和secondarynamenode使用该文件为存储目录加锁,可以避免其他namenode实例同时使用一个存储目录的情况
关于检查点机制与secondarynamenode工作流程会在下文谈到
此时多了两个编辑日志文件
edits_0000000000000000001-0000000000000000002:
hdfs oev -i edits_0000000000000000001-0000000000000000002 -o ed1-2.xml
-63
OP_START_LOG_SEGMENT
1
OP_END_LOG_SEGMENT
2
由于是第一次启动hdfs,edits_1-2中只有两个事务,分别用来开启和数据编辑日志段
此时,我们对文件系统进行创建目录和上传文件的操作
[jinge@master1 current]$ hdfs dfs -mkdir /d1
[jinge@master1 current]$ hdfs dfs -put seen_txid /d1再查看edits_inprogress_0000000000000000003:
[jinge@master1 current]$ hdfs oev -i edits_inprogress_0000000000000000003 -o edi3.xml
-63
OP_START_LOG_SEGMENT
3
OP_MKDIR
4
0
16386
/d1
1554109823822
jinge
supergroup
493
OP_ADD
5
0
16387
/d1/seen_txid._COPYING_
3
1554109857571
1554109857571
134217728
DFSClient_NONMAPREDUCE_-522026880_1
192.168.80.120
true
jinge
supergroup
420
571814e9-c526-4c11-8c40-452e3b2febde
3
OP_ALLOCATE_BLOCK_ID
6
1073741825
OP_SET_GENSTAMP_V2
7
1001
OP_ADD_BLOCK
8
/d1/seen_txid._COPYING_
1073741825
0
1001
-2
OP_CLOSE
9
0
0
/d1/seen_txid._COPYING_
3
1554109858382
1554109857571
134217728
false
1073741825
2
1001
jinge
supergroup
420
OP_RENAME_OLD
10
0
/d1/seen_txid._COPYING_
/d1/seen_txid
1554109858388
571814e9-c526-4c11-8c40-452e3b2febde
9
上传一个小于128M的文件一共分为了5个事务
编辑日志在概念上是单个实体,但它体现为磁盘上的多个文件。每个文件称为一个段(segment),名称由edits和后缀组成,后缀指出改文件所包含的事务id;任一时刻只有一个文件处于打开可写状态,名称前缀为edits_inprocess
并且可以从这几个文件的命名上发现以下规律:
...
...
edits_000(m)-000(n) m在每个事务完成之后,且在向客户端发送成功代码之前,文件都需要更新和同步,当namenode向多个目录写数据时,只有在所有写操作更新并同步到每个副本之后方可返回成功代码,以确保任何事务都不会因为机器故障而丢失
每个fsimage文件都是文件系统元数据的一个完整的永久性检查点,后缀表示镜像文件中的最后一个事务,并非每一个写操作都会更新镜像文件,因为fsimage是一个大型文件,如果频繁地执行写操作会使系统运行缓慢,这就需要将这些写操作存储在edits文件中;这样即使namenode发生故障,最近的fsimage文件将被载入到内存以重构元数据的最近状态,再想相关点开始向前执行编辑日志中记录的每个事务。其实这就是保存检查点的过程;
检查点机制
那么编辑日志会无线增长,尽管这对namenode的运行没什么影响,但由于要恢复很长一段时间的编辑日志中的各项事务,会导致namenode的重启会很慢。解决方案就是为主namenode内存中的文件系统元数据创建检查点,这个过程有两种实现方式:通过namenode本身或通过secondarynamenode;
手动在namenode中保存检查点:
首先需要进入安全模式,用法: hdfs dfsadmin [-safemode enter | leave | get | wait]
[jinge@master1 current]$ hdfs dfsadmin -safemode enter
Safe mode is ON
然后进行保存检查点(命名空间)
[jinge@master1 current]$ hdfs dfsadmin -saveNamespace
Save namespace successful此时dfs目录下:
dfs
├── name
│ ├── current
│ │ ├── edits_0000000000000000001-0000000000000000002
│ │ ├── edits_0000000000000000003-0000000000000000011
│ │ ├── edits_inprogress_0000000000000000012
│ │ ├── fsimage_0000000000000000002
│ │ ├── fsimage_0000000000000000002.md5
│ │ ├── fsimage_0000000000000000011
│ │ ├── fsimage_0000000000000000011.md5
│ │ ├── seen_txid
│ │ └── VERSION
│ └── in_use.lock
└── namesecondary
├── current
│ ├── edits_0000000000000000001-0000000000000000002
│ ├── fsimage_0000000000000000000
│ ├── fsimage_0000000000000000000.md5
│ ├── fsimage_0000000000000000002
│ ├── fsimage_0000000000000000002.md5
│ └── VERSION
└── in_use.lock
可见namesecondary目录中没有发生变化,而在name目录中保存了上一次镜像文件,并生成了一个新的镜像文件后缀为11;之前的edits_inprogress_003被重命名为了edits_003-011(第11条事务为END_LOG_SEGMENT),同时新建了一个名为edits_inprogress_012的日志文件;而namesecondary中并没有变化
secondarynamenode
或者可以通过运行secondarynamenode来创建检查点,创建步骤如下图
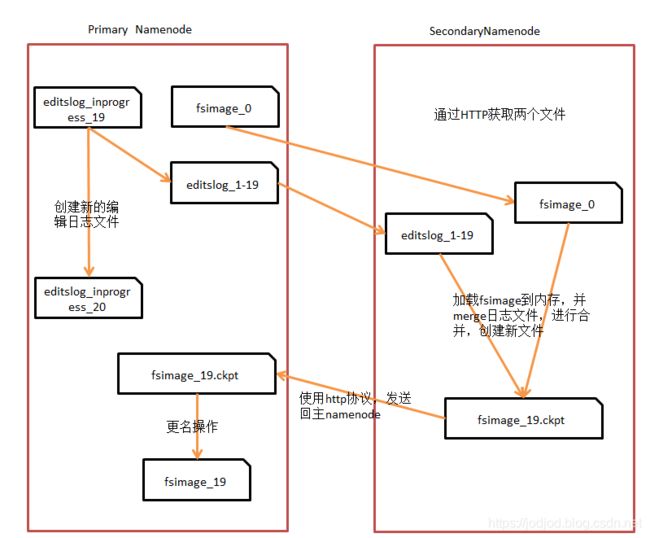
1、secondarynamenode请求namenode停止使用的edits_inprogress文件,新的编辑操作记录到一个新的edits_inprogress文件中,同时namenode会更新所有存储目录中的seen_txid
2、secondarynamenode从namenode中通过HTTP GET获取最近的fsimage和edits文件
3、secondarynamenode将fsimage文件载入内存,逐一执行edits文件中的事务,创建新的合并后的fsimage文件
4、secondarynamenode将新的fsimage文件通过HTTP PUT发送回主namenode,namenode将其保存为临时的.ckpt文件
5、namenode重命名临时的fsimage文件
可见secondarynamenode和主namenode拥有相近的内存需求,secondarynamenode也把fsimage文件载入内存,所以secondarynamenode在大型集群中也需要运行在一台专用的机器上
每次开启HDFS都会进行保存检查点,在重启之前再次上传一个文件
dfs
├── name
│ ├── current
│ │ ├── ed1-2.xml
│ │ ├── edi3.xml
│ │ ├── edits_0000000000000000001-0000000000000000002
│ │ ├── edits_0000000000000000003-0000000000000000011
│ │ ├── edits_0000000000000000012-0000000000000000019
│ │ ├── edits_0000000000000000020-0000000000000000020
│ │ ├── edits_0000000000000000021-0000000000000000022
│ │ ├── edits_inprogress_0000000000000000023
│ │ ├── fsimage_0000000000000000019
│ │ ├── fsimage_0000000000000000019.md5
│ │ ├── fsimage_0000000000000000022
│ │ ├── fsimage_0000000000000000022.md5
│ │ ├── seen_txid
│ │ └── VERSION
│ └── in_use.lock
└── namesecondary
├── current
│ ├── edits_0000000000000000001-0000000000000000002
│ ├── edits_0000000000000000012-0000000000000000019
│ ├── edits_0000000000000000020-0000000000000000020
│ ├── edits_0000000000000000021-0000000000000000022
│ ├── fsimage_0000000000000000019
│ ├── fsimage_0000000000000000019.md5
│ ├── fsimage_0000000000000000022
│ ├── fsimage_0000000000000000022.md5
│ └── VERSION
└── in_use.lock
上传文件的6条命令位于edits_012-019中,edits_020-020只有一条START_LOG_SEGMENT事务,然后edits_-021-022中是START和END事务,至于为什么有这个过程而不是直接新建一个edits_inprogress_020关系到hdfs运行底层的一些规则,我多次尝试还是没发现啥规律(可能刚好碰上了检查点周期?),但可以确定的是一旦遇到END_LOG_SEGMENT事务会结束一个段,此时会发生保存检查点
在hdfs-site.xml中可以设置与检查点触发点有关属性:
dfs.namenode.checkpoint.period
3600
两个定期检查点之间的秒数
dfs.namenode.checkpoint.txns
1000000
secondarynamenode或检查点节点将创建检查点
每个“dfs.namenode.checkpoint.txns”事务的名称空间
判断“dfs.namenode.checkpoint.period”是否已过期
dfs.namenode.checkpoint.check.period
60
SecondaryNameNode和CheckpointNode将轮询NameNode
每隔'dfs.namenode.checkpoint.check.period'秒查询一次
未存入检查点事务
默认情况下,secondarynamenode每隔一小时创建检查点,此外如果上一个检查点开始编辑日志的大小已经达到了100万个事务,那么及时不到一小时,也会创建检查点,检查频率为每60秒一次
这个过程namesecondary目录发生了更新;secondarynamenode的检查点目录的布局与namenode的是相同的,这种设计的好处是namenode发生故障时,可以从secondarynamenode恢复数据;有两种实现方法:一是将相关存储目录复制到新的namenode中;二是使用-importCheckpoint选项启动namenode守护进程,从而将secondarynamenode用作新的namenode
与第一次开启hdfs过程不同的是此次有30多秒的安全模式

在安全模式中在等待块报告,这也关系到datanode的运行过程
datanode
与namenode不同的是,datanode的存储目录是在初始化阶段自动创建的,并不需要额外的格式化,上传了两个小于128M文件的datanode的关键文件和目录如下图(slave1):
dfs
└── data
├── current
│ ├── BP-163740078-192.168.80.120-1554104956001
│ │ ├── current
│ │ │ ├── dfsUsed
│ │ │ ├── finalized
│ │ │ │ └── subdir0
│ │ │ │ └── subdir0
│ │ │ │ ├── blk_1073741825
│ │ │ │ ├── blk_1073741825_1001.meta
│ │ │ │ ├── blk_1073741826
│ │ │ │ └── blk_1073741826_1002.meta
│ │ │ ├── rbw
│ │ │ └── VERSION
│ │ ├── scanner.cursor
│ │ └── tmp
│ └── VERSION
└── in_use.lock
网页端信息:
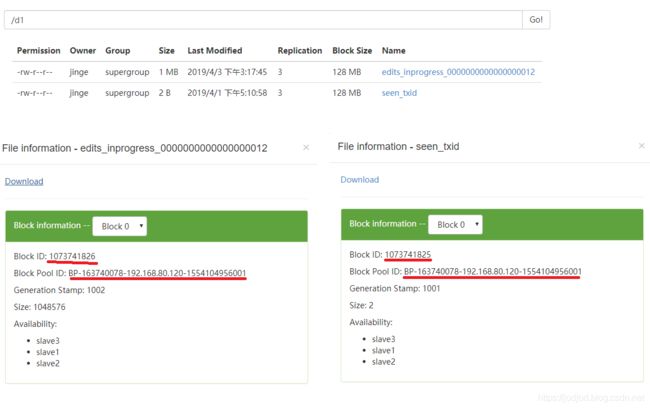
可见其块id,块池id与文件名是对应的,两个文件在同一个块中
HDFS数据块存储在以blk_为前缀的文件中,文件包含了该文件存储的块的原始字节数;每个块有一个相关的带有.meta后缀的元数据文件,元数据文件包括头部(含版本和类型信息)和该块各区段的一系列的校验和
每个块属于一个数据块池,每个块池都有自己的存储目录,目录根据数据块池id形成,与namenode的VERSION文件中的数据块池id相同;同一个datanode上的每个磁盘上的块不会重复,只有不同的块之间才有可能重复
安全模式
以上保存检查点的过程都是在安全模式下进行的
在安全模式下,只能对文件系统进行访问文件,例如显示目录列表等;对于读文件操作来说,只有集群中当前datanode上的块可用时才能够工作;但文件修改操作,如写、删除或重命名均会失败
系统中的数据块的位置并不是由namenode维护的,而是以块列表的形式存储在datanode中(每个datanode存储的块组成的列表),namenode会在内存中保留所有块位置和映射信息。在安全模式下各个datanode会向namenode发送最新的块列表信息,如果namenode认为向其发送更新信息的datanode节点过少(可理解为该datanode宕机),则会启动块复制进程,以将数据块复制到新的datanode上;而这个发送最新块列表可以看做是一次心跳,发送心跳的默认间隔时间为3秒,当前系统中一共有2个块,所以安全模式的时间为30+3*2=36秒
如果满足最小复本条件,namenode默认会在30秒之后推出安全模式。最小复本条件是指在整个文件系统中有99.9%的块满足最小复本级别(默认为1,属性dfs.namenode.replication.min),这也就是为什么刚格式化的集群由于系统中没有任何块,所以namenode不会进入安全模式
安全模式相关属性:
dfs.heartbeat.interval
3
确定datanode心跳间隔(以秒为单位)。
dfs.namenode.replication.min
1
最小的块复制。
dfs.namenode.safemode.threshold-pct
0.999f
指定应该满足的块的百分比
dfs.namenode.replication.min定义的最小复制需求。
小于或等于0的值表示不等待任何特定的值
退出safemode之前的块的百分比。
值大于1将使安全模式永久。
dfs.namenode.safemode.extension
30000
确定安全模式的扩展(以毫秒为单位)
在达到阈值水平之后。