Spark Streaming之:二、基本输入源
Spark Streaming之:二、基本输入源
文章目录
- Spark Streaming之:二、基本输入源
- 一、文本文件输入源(数据实时采集)
- 1. 基本步骤
- 2. Spark-shell操作
- 3. IDEA程序
- 4. spark提交流计算任务
- 二、socket输入源
- 1.使用套接字流作为数据源
- 2.编写程序
- 3.打包上传执行
- 三、队列流输入源
- 四、Kafka输入源
—>Spark知识点总结导航<—
一、文本文件输入源(数据实时采集)
1. 基本步骤
(启动MySQL、hive、spark集群,启动数据监听)
- a. 通过创建输入DStream来定义输入流;
- b. 通过对DStream应用转换操作来定义流计算;
- c. 用StreamingContext.start()来开始接收数据和处理数据;
- d. 通过StreamingContext.awaitTermination()方法来等待处理结束;
- e. 可以通过StreamingContext.stop()来手动结束流计算进程。
2. Spark-shell操作
a. 引包
import org.apache.spark.streaming._

b. 设置间隔时间
val ssc=new StreamingContext(sc,Seconds(20))
![]()
c. 读取文件
val lines=ssc.textFileStream("/home/duck/spark")
![]()
d. 按格式提取数据
val values=lines.flatMap(_.split(" "))
![]()
val words=values.map(x=>(x,1)).reduceByKey(_+_)
![]()
e. 启动并查看结果
words.print()
ssc.start() //启动流计算

ssc.awaitTermination()
ssc.stop() //手动结束
3. IDEA程序
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object stream01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("stream01")
//创建Streaming程序的入口,间隔时间为20秒
val ssc = new StreamingContext(conf,Seconds(20))
//生成的日志文件清晰可读
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
//获取文件数据
val lines:DStream[String] = ssc.textFileStream("/home/duck/spark")
//切割数据
val words:DStream[String] = lines.flatMap(_.split(" "))
//将数据转为k-v形式
val values:DStream[(String,Int)] = words.map(t=>(t,1))
//wordcount汇总
val wordcount:DStream[(String,Int)] = values.reduceByKey(_+_)
wordcount.print()
ssc.start()
ssc.awaitTermination()
//ssc.stop()
}
}
在控制台中没有什么结果显示,只能通过提交任务。
4. spark提交流计算任务
a. 写好程序代码
b. 打包上传
c. 提交spark任务
bin/spark-submit \
--class com.spark.streaming.stream01 \
/home/duck/Lesson-1.0-SNAPSHOT.jar

二、socket输入源
1.使用套接字流作为数据源
先检测有没有安装:
nc -lk 9999
 未安装,需要在线安装:
未安装,需要在线安装:
yum install nc.x86_64
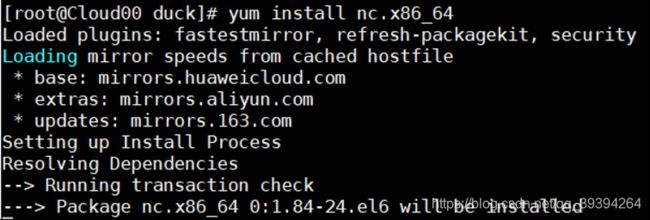 安装完成!
安装完成!

2.编写程序
package com.spark.streaming
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object socket01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("socket01")
val ssc = new StreamingContext(conf,Seconds(20))
val lines:ReceiverInputDStream[String] = ssc.socketTextStream("Cloud00",9999)
val words = lines.flatMap(_.split(" "))
val count = words.map(x=>(x,1)).reduceByKey(_+_)
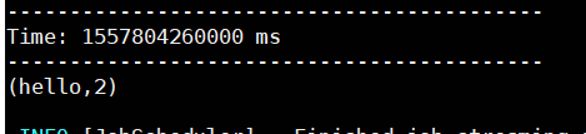
count.print()
ssc.start()
ssc.awaitTermination()
}
}
3.打包上传执行
./bin/spark-submit \
--class com.spark.streaming.socket01 \
/home/duck/Lesson-1.0-SNAPSHOT.jar


三、队列流输入源
package com.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
object QueueStream {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("test")
val ssc = new StreamingContext(conf,Seconds(20))
//创建一个可变队列RDD
val rddQueue = new scala.collection.mutable.SynchronizedQueue[RDD[Int]]()
val queueStream = ssc.queueStream(rddQueue)
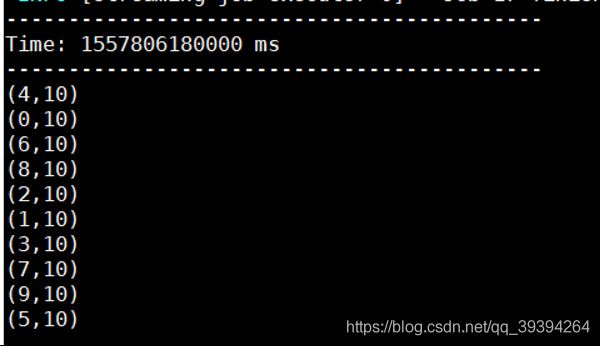
val mappedStream = queueStream.map(r=>(r%10,1))
val reducedStream = mappedStream.reduceByKey(_+_)
reducedStream.print()
ssc.start()
for (i<-1 to 10){
rddQueue += ssc.sparkContext.makeRDD(seq = 1 to 100,numSlices = 2)
Thread.sleep(1000)
}
ssc.awaitTermination()
ssc.stop()
}
}
 ***
***
四、Kafka输入源
- Kafka之一:Kafka简述
- Kafka之二:Kafka集群的安装
- Kafka之三:Kafka集群工作流程
- Kafka之四:Kafka与Streaming集成