Spark-SQL应用解析
文章目录
- 一、概述
- DataFrame
- DataSet
- 二、数据转换
- 1.RDD<->DataFrame
- RDD->DataFrame
- DataFrame->RDD
- 2.RDD<->DataSet
- RDD->DataSet
- DataSet->RDD
- 3.DataFrame<->DataSet
- DataFrame->DataSet
- DataSet->DataFrame
- 三、SparkSQL简单操作
- 四、SQL的执行模式
- DSL模式
- SQL模式
- 五、自定义函数
- 1.udf函数
- 2.udaf函数
- 六、对Hive的集成
- 1.使用内置的Hive
- (1)创建表
- (2)导入数据
- 2.使用外部的Hive
- 七、SparkSql 输入输出
- 1.输入
- <1>高级模式
- <2>低级模式
- 2.输出
- <1>高级模式
- <2>低级模式
一、概述
sparksql是spark的一个模板,可以和RDD进行混合编程、支持标准的数据源、可以集成和替代Hive、可以提供JDBC,ODBC的服务器功能。
SparkSQL里面有两个数据抽象,DataSet和DataFrame
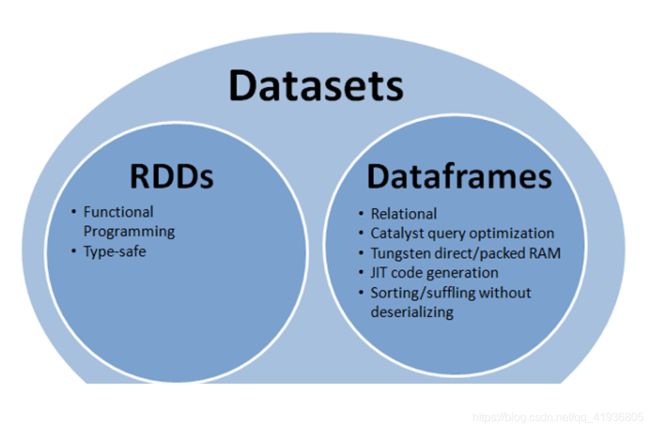
DataFrame
SQL 操作主要涉及到表的操作,表是数据和Schema的组成,所以可以认为DataFrame就是一张表=RDD+Schema

DataFrame的执行效率要比RDD要高,主要表现在定制化内存管理和优化的执行引擎。
DataFrame是一个弱类型的数据对象,缺少数据类型安全检查,运行期检查,类似于java.sql.ResultSet类,只能通过getString这种方式来获取具体数据。
DataSet
DataSet具有DataFrame所有的好处,同时,可以配合case class来实现强类型。具有局部序列化和反序列化功能。
DataFrame只是知道字段,但是不知道字段的类型,所以在执行这些操作的时候是没办法在编译的时候检查是否类型失败的,比如你可以对一个String进行减法操作,在执行的时候才报错,而DataSet不仅仅知道字段,而且知道字段类型,所以有更严格的错误检查。
二、数据转换
1.RDD<->DataFrame
RDD->DataFrame
1.手动转换
scala> val people = sc.textFile("File:///home/centos01/modules/spark-2.1.1-bin-hadoop2.7/examples/src/main/resources/people.txt")
people: org.apache.spark.rdd.RDD[String] = File:///home/centos01/modules/spark-2.1.1-bin-hadoop2.7/examples/src/main/resources/people.txt MapPartitionsRDD[1] at textFile at :24
//先读取本地文件
scala> people.collect
res0: Array[String] = Array(Michael, 29, Andy, 30, Justin, 19)
scala> val peopleFrame = people.map{x=>val para = x.split(",");(para(0),para(1).trim.toInt)}
peopleFrame: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[2] at map at <console>:26
//以map的形式存储,因为文本文件是逗号分隔符,所以按照逗号进行split存储到map
scala> peopleFrame.collect
res1: Array[(String, Int)] = Array((Michael,29), (Andy,30), (Justin,19))
scala> import spark.implicits._
import spark.implicits._
//只要RDD->DataFrame都要用到spark的隐式转换,不然无法用toDF
scala> peopleFrame.toDF("name","age")
res2: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> res2.collect
res3: Array[org.apache.spark.sql.Row] = Array([Michael,29], [Andy,30], [Justin,19])
scala> res2.show
+-------+---+
| name|age|
+-------+---+
|Michael| 29|
| Andy| 30|
| Justin| 19|
+-------+---+
//转换完成
2.反射
scala> var peopleRDD = sc.textFile("File:///home/centos01/modules/spark-2.1.1-bin-hadoop2.7/examples/src/main/resources/people.txt")
peopleRDD: org.apache.spark.rdd.RDD[String] = File:///home/centos01/modules/spark-2.1.1-bin-hadoop2.7/examples/src/main/resources/people.txt MapPartitionsRDD[1] at textFile at :24
scala> peopleRDD.collect
res0: Array[String] = Array(Michael, 29, Andy, 30, Justin, 19)
scala> case class people(name:String,age:Int)
defined class people
scala> peopleRDD.map{x=>val para = x.split(",");people(para(0),para(1).trim.toInt)}.toDF
res1: org.apache.spark.sql.DataFrame = [name: string, age: int]
3.编程
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> val scheam = StructType(StructField("name",StringType)::StructField("age",IntegerType)::Nil)
scheam: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,true), StructField(age,IntegerType,true))
//准备scheam
scala> import org.apache.spark.sql._
import org.apache.spark.sql._
scala> peopleRDD.map{x=>val para = x.split(",");Row(para(0),para(1).trim.toInt)}
res3: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[3] at map at <console>:37
//准备row类型的数据
scala> spark.createDataFrame(res3,scheam)
res5: org.apache.spark.sql.DataFrame = [name: string, age: int]
//生成DataFrame
scala> res5.show
+-------+---+
| name|age|
+-------+---+
|Michael| 29|
| Andy| 30|
| Justin| 19|
+-------+---+
DataFrame->RDD
scala> import res2.sparkSession.implicits._
import res2.sparkSession.implicits._
//由刚才创建的DataFrame引入隐式转换
scala> res2.rdd
res5: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[12] at rdd at <console>:37
//直接.rdd进行rdd的转换操作
scala> res5.map(_.getString(0)).collect
res6: Array[String] = Array(Michael, Andy, Justin)
scala> res5.collect
res7: Array[org.apache.spark.sql.Row] = Array([Michael,29], [Andy,30], [Justin,19])
scala> res5.show
<console>:39: error: value show is not a member of org.apache.spark.rdd.RDD[org.apache.spark.sql.Row]
res5.show
2.RDD<->DataSet
RDD->DataSet
scala> var rdd = sc.textFile("File:///home/centos01/modules/spark-2.1.1-bin-hadoop2.7/examples/src/main/resources/people.txt")
rdd: org.apache.spark.rdd.RDD[String] = File:///home/centos01/modules/spark-2.1.1-bin-hadoop2.7/examples/src/main/resources/people.txt MapPartitionsRDD[15] at textFile at :36
//倒本地文件
scala> case class People(name:String,age:Int)
defined class People
建立一个类,以便show表的时候rowKey可以指定
scala> val peopleSet = rdd.map{x=>val para = x.split(",");People(para(0),para(1).trim.toInt)}
peopleSet: org.apache.spark.rdd.RDD[People] = MapPartitionsRDD[20] at map at <console>:40
//以map的形式存储,因为文本文件是逗号分隔符,所以按照逗号进行split存储到map
scala> peopleSet.toDS
res12: org.apache.spark.sql.Dataset[People] = [name: string, age: int]
//以map形式转换后直接.toDS完成转换
scala> res12.show
+-------+---+
| name|age|
+-------+---+
|Michael| 29|
| Andy| 30|
| Justin| 19|
+-------+---+
DataSet->RDD
本质就是用DataSet.rdd直接进行转换
scala> res12.rdd
res14: org.apache.spark.rdd.RDD[People] = MapPartitionsRDD[25] at rdd at <console>:45
scala> res14.show
<console>:47: error: value show is not a member of org.apache.spark.rdd.RDD[People]
res14.show
^
scala> res14.collect
res16: Array[People] = Array(People(Michael,29), People(Andy,30), People(Justin,19))
3.DataFrame<->DataSet
DataFrame->DataSet
和DataSet转DataFrame略有不同在需要借助case Class来确认rowKey
scala> case class People(name:String,age:Int)
defined class People
scala> res18.as[People]
res19: org.apache.spark.sql.Dataset[People] = [name: string, age: int]
scala> res19.show
+-------+---+
| name|age|
+-------+---+
|Michael| 29|
| Andy| 30|
| Justin| 19|
+-------+---+
DataSet->DataFrame
scala> res12
res17: org.apache.spark.sql.Dataset[People] = [name: string, age: int]
scala> res17.toDF
res18: org.apache.spark.sql.DataFrame = [name: string, age: int]
三、SparkSQL简单操作
读取文件: 这里是从本地文件进行读取,也可以从hdfs进行读取,只需要把Path填好就行hdfs://localhost:8020/path
scala> val example = spark.read.json("File:///home/centos01/modules/spark-2.1.1-bin-hadoop2.7/examples/src/main/resources/employees.json")
example: org.apache.spark.sql.DataFrame = [name: string, salary: bigint]
展现表:
1.可以使用直接show的方法展示
scala> example.show
+-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
2.也可以使用sql语句去show
scala> example.createOrReplaceTempView("employee")
scala> spark.sql("Select * from employee").show
+-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
3.在idea上
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object sql_Hello extends App {
val sparkConf = new SparkConf().setAppName("sparksql").setMaster("local[*]")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val sc = spark.sparkContext
val example = spark.read.json("")
example.show()
example.select("name").show()
example.createOrReplaceTempView("employee")
spark.sql("select * from employee").show()
spark.stop()
}
四、SQL的执行模式
DSL模式
scala> res5.filter($"age">25).show
+-------+---+
| name|age|
+-------+---+
|Michael| 29|
| Andy| 30|
+-------+---+
SQL模式
创建一张表:
//Session内可访问,一个SparkSession结束后,表自动删除
scala> res5.createOrReplaceTempView("people")
scala> spark.sql("Select * from people")
res11: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> res11.show
+-------+---+
| name|age|
+-------+---+
|Michael| 29|
| Andy| 30|
| Justin| 19|
+-------+---+
//应用级别内可访问,一个SparkContext结束后,表自动删除(使用表名需要加上前缀"global_temp")
scala> res5.createGlobalTempView("p1")
scala> spark.sql("Select * from global_temp.p1").show
+-------+---+
| name|age|
+-------+---+
|Michael| 29|
| Andy| 30|
| Justin| 19|
+-------+---+
执行sql:
spark.sql("")即可
五、自定义函数
1.udf函数
通过spark.udf.register(“name”,func)来注册自定义的函数,func为函数体
scala> spark.udf.register("add",(x:String)=>"A:"+x)
res17: org.apache.spark.sql.expressions.UserDefinedFunction = UserDefinedFunction(<function1>,StringType,Some(List(StringType)))
scala> spark.sql("select add(name) from people").show
+-------------+
|UDF:add(name)|
+-------------+
| A:Michael|
| A:Andy|
| A:Justin|
+-------------+
2.udaf函数
<1>弱类型UDAF函数
package sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
/**
* {"name":"Michael", "salary":3000}
* {"name":"Andy", "salary":4500}
* {"name":"Justin", "salary":3500}
* {"name":"Berta", "salary":4000}
* 求平均工资
*/
//自定义UDAF函数需要继承UserDefinedAggregateFunction
class AverageSal extends UserDefinedAggregateFunction{
//提供用于聚合的Schema
override def inputSchema: StructType = StructType(StructField("salary",LongType)::Nil)
//提供给小聚合与返回值相关的参数,是每一个分区的共享值
override def bufferSchema: StructType = StructType(StructField("sum",LongType)::StructField("count",LongType)::Nil)
//UDAF的输出类型
override def dataType: DataType = DoubleType
//如果有相同的输入,那么是否有相同的输出
override def deterministic: Boolean = true
//将bufferSchema注入的参数进行初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
// 对应bufferSchema的第一个传参sum,和第二个传参count
buffer(0)=0L
buffer(1)=0L
}
//更新在小聚合中的数据,聚合每一条数据需要调用此方法
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if(!input.isNullAt(0)){
// 获取这一行中的工资,然后把工资加入sum中
buffer(0) = buffer.getLong(0)+input.getLong(0)
// 将工资的个数+1
buffer(1) = buffer.getLong(1)+1
}
}
//合并小聚合的数据,完成大聚合
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
// 合并总的工资
buffer1(0) = buffer1.getLong(0)+buffer2.getLong(0)
// 合并的总的工资的个数
buffer1(1) = buffer1.getLong(1)+buffer2.getLong(1)
}
//计算最后输入的值
override def evaluate(buffer: Row): Any = {
// 令总工资/总的工资个数
buffer.getLong(0).toDouble/buffer.getLong(1)
}
}
object AverageSal {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("Eva").setMaster("local[*]")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val employee = spark.read.json("path")
employee.createOrReplaceTempView("employee")
spark.udf.register("average",new AverageSal)
spark.sql("select average(salary) from employee").show()
spark.stop()
}
}
<2>强类型UDAF函数
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Encoder, Encoders, SparkSession}
case class Employee(name:String,salary:Long)
case class Aver(var sum:Long,var count:Int)
//[IN,BUF,OUT]形似弱类型开窗函数
class Average extends Aggregator[Employee,Aver,Double]{
// 初始化方法=>初始化每一个分区中的直接影响计算结果的共享变量
override def zero: Aver = Aver(0L,0)
// 每一个分区中的每一条数据聚合的时候需要调用该方法
override def reduce(b: Aver, a: Employee): Aver = {
b.sum=b.sum+a.salary
b.count=b.count+1
b
}
// 将每一个分区的输出合并形成最后的数据
override def merge(b1: Aver, b2: Aver): Aver = {
b1.sum=b1.sum+b2.sum
b1.count=b1.count+b2.count
b1
}
// 给出计算结果
override def finish(reduction: Aver): Double = {
reduction.sum.toDouble/reduction.count
}
// 主要用于对共享变量进行编码
override def bufferEncoder: Encoder[Aver] = {
Encoders.product
}
// 将输出进行编码
override def outputEncoder: Encoder[Double] = {
Encoders.scalaDouble
}
}
object Average{
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("spark01").setMaster("local[*]")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
// 此时employee为一个弱类型的DataFrame
val employee = spark.read.json("G:\\Users\\Administrator\\eclipse-workspace\\scala_project\\src\\main\\scala\\sparksql\\employee").as[Employee]
// 注册表
val aver = new Average().toColumn.name("average")
employee.select(aver).show()
spark.stop()
}
}
六、对Hive的集成
1.使用内置的Hive
(1)创建表
scala> spark.sql("CREATE TABLE if NOT EXISTS src(key Int,value String)")
2019-01-11 10:09:39,669 WARN [main] metastore.HiveMetaStore: Location: file:/home/centos01/modules/spark-2.1.1-bin-hadoop2.7/spark-warehouse/src specified for non-external table:src
res1: org.apache.spark.sql.DataFrame = []
scala> spark.sql("show tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
| default| src| false|
+--------+---------+-----------+
(2)导入数据
如果发现master节点出现了metastore_db,删除,然后可以直接在bin/spark-shell的时候直接–conf spark.sql.warehouse.dir=hdfs://path用一个hdfs的数据仓库目录来防止Not Exists File类似错误,也可以scp -r本地的文件到其他节点。
但是当第一次bin/spark-shell之后,指定完path,第二次就不用再指定了,直接会默认。
scala> spark.sql("LOAD DATA LOCAL inpath '/home/centos01/modules/spark-2.1.1-bin-hadoop2.7/examples/src/main/resources/kv1.txt' into table src")
2019-01-11 10:25:08,392 ERROR [main] hdfs.KeyProviderCache: Could not find uri with key [dfs.encryption.key.provider.uri] to create a keyProvider !!
res3: org.apache.spark.sql.DataFrame = []
scala> spark.sql("SELECT * FROM src").show
+---+-------+
|key| value|
+---+-------+
|238|val_238|
| 86| val_86|
|311|val_311|
| 27| val_27|
|165|val_165|
|409|val_409|
|255|val_255|
|278|val_278|
| 98| val_98|
|484|val_484|
|265|val_265|
|193|val_193|
|401|val_401|
|150|val_150|
|273|val_273|
|224|val_224|
|369|val_369|
| 66| val_66|
|128|val_128|
|213|val_213|
+---+-------+
only showing top 20 rows
在bin/spark-sql中直接写sql语句就行,而且可以展示全部数据,不像spark-shell只能显示一部分。
如果感觉spark-sql日志太多,可以这样配置你的log4j.properties:
2.使用外部的Hive
1.连接外部的hive,首先要启动本地的hive。
2.在hive中创建测试表
3.设定一个软链接将hive-site.xml的快捷方式安放到spark的conf目录下
[centos01@linux01 spark-2.1.1-bin-hadoop2.7]$ ln -s /home/centos01/modules/apache-hive-1.2.2-bin/conf/hive-site.xml ./conf/
4.启动spark-shell或者spark-sql
5.此时会发现sparksql已经接管了hive
七、SparkSql 输入输出
1.输入
<1>高级模式
spark.read.json(path)
spark.read.jdbc(path)
spark.read.csv(path)
spark.read.parquet(path)默认格式
spark.read.orc(path)
spark.read.json(path)
spark.read.table(path)
spark.read.text(path)
spark.read.textFile(path)
除了textFile是DataSet其他都是DataFrame属性,使用的时候要转成RDD然后进行自己的操作
<2>低级模式
spark.read.fomat(“json”).load(path)如果不指定format的格式,默认为parquet
2.输出
<1>高级模式
dataFrame.write.json(path)
dataFrame.write.jdbc(path)
dataFrame.write.csv(path)
dataFrame.write.parquet(path)默认格式
dataFrame.write.orc(path)
dataFrame.write.json(path)
dataFrame.write.table(path)
dataFrame.write.text(path)
<2>低级模式
dataFrame.write.format(“jdbc”).参数.mode(savemode).save
/**
* Specifies the behavior when data or table already exists. Options include:
* - `overwrite`: overwrite the existing data.
* - `append`: append the data.
* - `ignore`: ignore the operation (i.e. no-op).
* - `error`: default option, throw an exception at runtime.
*
* @since 1.4.0
*/