Spark/Scala/SparkSQL问题记录:使用Scala语言遍历DateFrame/DataSet数据集里的每一行、每一列
在贴代码之前先介绍一下DataFrame与DataSet,以下介绍内容来自以下博客:https://www.cnblogs.com/seaspring/p/5831677.html
DataFrame
DataFrame是一个分布式集合,其中数据逻辑存储结构为有名字的列。它概念上等价于关系数据库中的表,一个列名对应很多列值,但底层做了更多的优化。DataFrame可以从很多数据源构建,比如:已经存在的RDD、结构化文件(json文件、csv文件等)、外部数据库、Hive表。
DataFrame的前身是SchemaRDD,从Spark 1.3.0开始SchemaRDD更名为DataFrame。与SchemaRDD的主要区别是:DataFrame不再直接继承自RDD,而是自己实现了RDD的绝大多数功能。你仍旧可以在DataFrame上调用.rdd方法将其转换为一个RDD。RDD可看作是分布式的对象的集合,Spark并不知道对象的详细模式信息,DataFrame可看作是分布式的Row对象的集合,其提供了由列组成的详细模式信息,使得Spark SQL可以进行某些形式的执行优化。DataFrame和普通的RDD的逻辑框架区别如下所示:
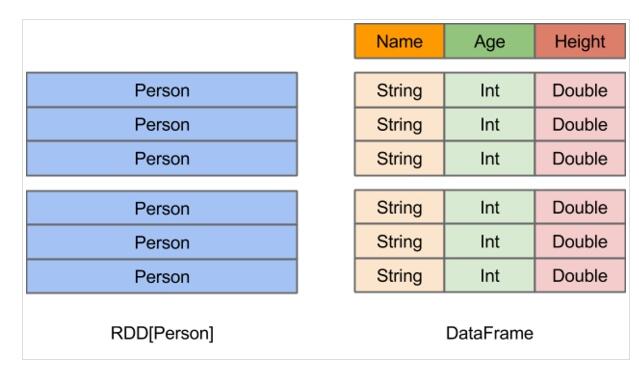
DataFrame不仅比RDD有更加丰富的算子,更重要的是它可以进行执行计划优化(得益于Catalyst SQL解析器),另外Tungsten项目给DataFrame的执行效率带来了很大提升(不过Tungsten优化也可能在后续开发中加入到RDD API中)。
但是在有些情况下RDD可以表达的逻辑用DataFrame无法表达,所以后续提出了Dataset API,Dataset结合了RDD和DataFrame的好处。
Dataset
Dataset是Spark 1.6新添加的一个实验性接口,其目的是想结合RDD的好处(强类型(这意味着可以在编译时进行类型安全检查)、可以使用强大的lambda函数)和Spark SQL的优化执行引擎的好处。可以从JVM对象构造出Dataset,然后使用类似于RDD的函数式转换算子(map/flatMap/filter等)对其进行操作。
Dataset通过Encoder实现了自定义的序列化格式,使得某些操作可以在无需解序列化的情况下直接进行。另外Dataset还进行了包括Tungsten优化在内的很多性能方面的优化。
实际上Dataset是包含了DataFrame的功能的,这样二者就出现了很大的冗余,故Spark 2.0将二者统一:保留Dataset API,把DataFrame表示为Dataset[Row],即Dataset的子集。
API进化
Spark在迅速的发展,从原始的RDD API,再到DataFrame API,再到Dataset的出现,速度可谓惊人,执行性能上也有了很大提升。
我们在使用API时,应该优先选择DataFrame & Dataset,因为它的性能很好,而且以后的优化它都可以享受到,但是为了兼容早期版本的程序,RDD API也会一直保留着。后续Spark上层的库将全部会用 DataFrame & Dataset,比如MLlib、Streaming、Graphx等。
①使用DataSet的foreach方法进行遍历
DataFrame是DataSet的一个子集,以下遍历的代码也是基于DataSet的API进行遍历的
// 先定义循环遍历里面的处理函数
// 输入参数类型为Row
def circularProcess(line : Row) : Unit = {
// 打印行里面的值,此处是获取第一列的值
println(line.get(0))
}
val df : DataFrame = (这里是获取DataFrame内容代码,获取方式有多种,见以上提到的内容)
// 调用DataSet的(foreach(f: T => Unit): Unit)方法进行遍历
// 将上面定义的处理函数作为参数传入foreach方法
df.foreach(circularProcess : Row => Unit)②利用DataSet的collect方法将DataFrame变成数组再用for循环进行遍历
第①种方法有个不太方便的点,就是遍历处理函数不能传其他参数,只能有Row类型的一个输入参数。而转换成数组再for循环则可以直接使用同一个函数里面的参数,不用再传递
正常DataFrame调用show方法是以表格的形式展示数据

DataFrame调用collect方法后是以[ [..,..,..] , [..,..,..] , [..,..,..] ...... ]的形式存储数据,外层数组是每一行数据(Row),里层数组是一行中每一列(Column)的数据,因此调用collect方法生成的数据其实就是二维数组,即数组里面的数据元素也是数组,因此遍历方式就是使用二维数据遍历方式

代码如下
var array = df.collect
for(i <- 0 to array.length-1){
for(j <- 0 to array(i).length-1){
println(array(i)(j))
}
}代码运行结果如下所示
