1.相对于传统主从模式的优势
传统的主从模式,需要手工指定集群中的Master。
如果Master发生故障,一般都是人工介入,指定新的Master。
这个过程对于应用一般不是透明的,往往伴随着应用重新修改配置文件,重启应用服务器等。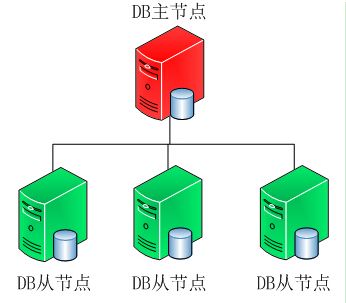
而MongoDB副本集,集群中的任何节点都可能成为Master节点。
一旦Master节点故障,则会在其余节点中选举出一个新的Master节点。
并引导剩余节点连接到新的Master节点。这个过程对于应用是透明的。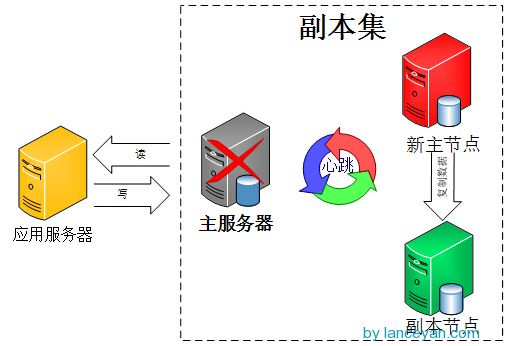
2. Bully选举算法
Bully算法是一种协调者(主节点)竞选算法,主要思想是集群的每个成员都可以声明它是主节点并通知其他节点。
别的节点可以选择接受这个声称或是拒绝并进入主节点竞争。被其他所有节点接受的节点才能成为主节点。
节点按照一些属性来判断谁应该胜出。这个属性可以是一个静态ID,也可以是更新的度量像最近一次事务ID(最新的节点会胜出)
选举过程大致如下:
1.得到每个服务器节点的最后操作时间戳。每个mongodb都有oplog机制会记录本机的操作,方便和主服务器进行对比数据是否同步还可以用于错误恢复。
2.如果集群中大部分服务器down机了,保留活着的节点都为 secondary状态并停止,不选举了。
3.如果集群中选举出来的主节点或者所有从节点最后一次同步时间看起来很旧了,停止选举等待人来操作。
4.如果上面都没有问题就选择最后操作时间戳最新(保证数据是最新的)的服务器节点作为主节点。
选举的触发条件:
1.初始化一个副本集时。
2.副本集和主节点断开连接,可能是网络问题。
3.主节点挂掉。
4.人为介入,比如修改节点优先级等
5.选举还有个前提条件,参与选举的节点数量必须大于副本集总节点数量的一半,如果已经小于一半了所有节点保持只读状态。
3 .搭建副本集集群
每个虚拟机都使用如下的配置文件启动实例:
./mongod --dbpath=/data0/mongodbtest/replset/data/ --logpath=/data0/mongodbtest/replset/log/mongodb.log --port 27017 --replSet repset --maxConns=1000 --logappend --fork
介绍一下mongod启动涉及到的参数 --dbpath 数据文件路径 --logpath 日志文件路径 --port 端口号,默认是27017.我这里使用的也是这个端口号. --replSet 复制集的名字,一个replica sets中的每个节点的这个参 数都要用一个复制集名字,这里是mvbox. --maxConns 最大连接数 --fork 后台运行 --logappend 日志文件循环使用,如果日志文件已满,那么新日志覆盖最久日志。
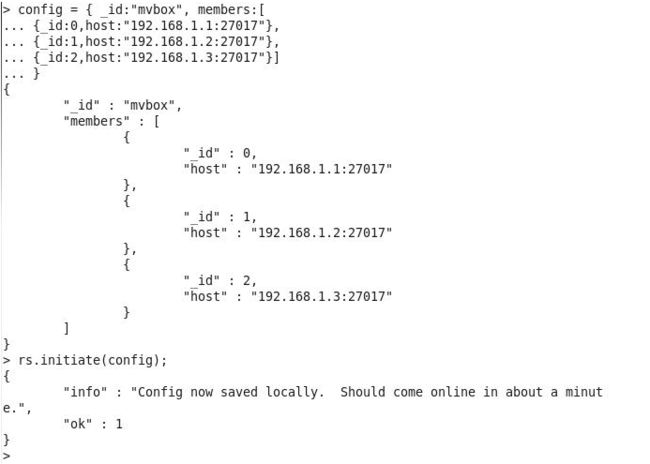
然后在任意一台虚拟机登陆mongo,输入如下设置
三个副本集组成的集群
config = { _id:"mvbox", members:[ {_id:0,host:"192.168.1.1:27017"}, {_id:1,host:"192.168.1.2:27017"}, {_id:2,host:"192.168.1.3:27017"}] } rs.initiate(config);
带有延迟复制的集群(设置优先级可以指定主辅副本集)
config = { _id:"repset", members:[
{_id:0,host:"192.168.4.135:27017",priority:2},
{_id:1,host:"192.168.4.136:27017",priority:0,slaveDelay:3600},
{_id:2,host:"192.168.4.138:27017",priority:10}]
}
rs.initiate(config);
初始化集群时,设置仲裁者的配置如下
config = { _id:"mvbox", members:[
{_id:0,host:"192.168.1.1:27017"},
{_id:1,host:"192.168.1.2:27017",arbiterOnly:true},
{_id:2,host:"192.168.1.3:27017"}]
}
rs.initiate(config);
注意:mvbox为集群名
可以看到副本集已经生效
可以使用rs.status()查看集群状态,或者rs.isMaster()

4. 更改节点优先级
修改节点的优先级可以触发重新选举,这样可以人工指定主节点。
使用如下命令,在主节点登录,将192.168.1.3提升为Master。
rs.conf(); cfg=rs.conf(); cfg.members[0].priority=1 cfg.members[1].priority=1 cfg.members[2].priority=10 rs.reconfig(cfg);
需要注意的是,修改节点优先级需要登录Master节点运行。否则报错。
再次查看集群状态,可以看到192.168.1.3已经作为Master运行
5 .节点类型
MongoDB的节点类型有主节点(Master),副本节点(Slave或者称为Secondary),仲裁节点,Secondary-Only节点,Hidden节点,Delayed节点和Non-Voting节点。
仲裁节点不存储数据,只是负责故障转移的群体投票,这样就少了数据复制的压力。
Secondary-Only:不能成为primary节点,只能作为secondary副本节点,防止一些性能不高的节点成为主节点。
Hidden:这类节点是不能够被客户端制定IP引用,也不能被设置为主节点,但是可以投票,一般用于备份数据。
Delayed:可以指定一个时间延迟从primary节点同步数据。主要用于备份数据,如果实时同步,误删除数据马上同步到从节点。所以延迟复制主要用于避免用户错误。
Non-Voting:没有选举权的secondary节点,纯粹的备份数据节点。
6 .设置隐藏节点(Hidden)
隐藏节点可以在选举中投票,但是不能被客户端引用,也不能成为主节点。也就是说这个节点不能用于读写分离的场景。
将192.168.1.3设置为隐藏节点。
注意,只有优先级为0的成员才能设置为隐藏节点。
如果设置优先级不为0的节点为隐藏节点,则报错如下
使用如下命令设置隐藏节点
cfg=rs.conf(); cfg.members[0].priority=10 cfg.members[1].priority=1 cfg.members[2].priority=0 cfg.members[2].hidden=1 rs.reconfig(cfg);
设置完成之后,使用rs.status()查看该节点还是SECONDARY状态。
但是通过rs.isMaster()和rs.conf()可以看到这个节点的变化。
rs.isMaster()的hosts中192.168.1.3节点已经不可见
并且rs.conf()显示该节点状态为hidden

7 .设置仲裁节点
仲裁节点不存储数据,只是用于投票。所以仲裁节点对于服务器负载很低。
节点一旦以仲裁者的身份加入集群,他就只能是仲裁者,无法将仲裁者配置为非仲裁者,反之也是一样。
另外一个集群最多只能使用一个仲裁者,额外的仲裁者拖累选举新Master节点的速度,同时也不能提供更好的数据安全性。
初始化集群时,设置仲裁者的配置如下
config = { _id:"mvbox", members:[ {_id:0,host:"192.168.1.1:27017"}, {_id:1,host:"192.168.1.2:27017",arbiterOnly:true}, {_id:2,host:"192.168.1.3:27017"}] }
使用仲裁者主要是因为MongoDB副本集需要奇数成员,而又没有足够服务器的情况。在服务器充足的情况下,不应该使用仲裁者节点。
8 .设置延迟复制节点(延迟节点)
MongoDB官方没有增量备份方案,只有一个导出的工具mongodump。
他不能像数据库一样,通过binlog或者归档日志将数据推到事故发生的前一刻。
假设每天凌晨2点使用mongodump备份,而下午5点发生事故,数据库损毁,则凌晨2点到下午5点的数据全部都会丢失。
虽然副本集可以一定程度避免这个问题,但是默认情况下不能避免人为的失误。
比如没有指定筛选条件删除了全部的数据。副本节点会应用这个命令,删除所有副本节点的数据。
在这个场景下,可以使用延迟节点,它会延迟应用复制。
如果主节点发生了人为的失误,而这个操作因为延迟的原因,还没有应用在延迟节点。
这个时候,修改延迟节点的优先级为最高级,使他成为新的Master服务器。
延迟节点的优先级必须为0.这个和hidden节点是一样的。
设置192.168.1.2为延迟节点
cfg=rs.conf(); cfg.members[1].priority=0 cfg.members[1].slaveDelay=3600 rs.reconfig(cfg);
slaveDelay的单位是秒
在192.168.1.1主节点删除一个集合所有数据,模拟人为失误。
db.users.remove({});
在192.168.1.3查看,发现数据已经全部丢失。
db.users.find();
而在192.168.1.2延迟节点,可以看到因为延迟复制的缘故,数据还在。
这个时候千万不要提升延迟节点的优先级。因为这样他会立即应用原主节点的所有操作,并成为新的主节点。这样误操作就同步到了延迟节点。
首先,关闭副本集中其他的成员,除了延迟节点。
删除其他成员数据目录中的所有数据。确保每个其他成员的数据目录都是空的(除了延迟节点)
重启其他成员,他们会自动从延迟节点中恢复数据(且并不改变之前的节点配置)。
9 .设置Secondary-Only节点
Priority为0的节点永远不能成为主节点,所以设置Secondary-only节点只需要将其priority设置为0.
10 .设置Non-Voting节点
假设设置192.168.1.1不能投票,则使用如下命令
cfg=rs.conf(); cfg.members[0].votes=0; rs.reconfig(cfg);
11 .副本集成员状态
副本集成员状态指的是rs.status()的stateStr字段
STARTUP:刚加入到复制集中,配置还未加载 STARTUP2:配置已加载完,初始化状态 RECOVERING:正在恢复,不适用读 ARBITER: 仲裁者 DOWN:节点不可到达 UNKNOWN:未获取其他节点状态而不知是什么状态,一般发生在只有两个成员的架构,脑裂 REMOVED:移除复制集 ROLLBACK:数据回滚,在回滚结束时,转移到RECOVERING或SECONDARY状态 FATAL:出错。查看日志grep “replSet FATAL”找出错原因,重新做同步 PRIMARY:主节点 SECONDARY:备份节点
12. 读写分离
如果Master节点读写压力过大,可以考虑读写分离的方案。
不过需要考虑一种场景,就是主服务器的写入压力非常的大,所以副本节点复制的写入压力同样很大。
这时副本节点如果读取压力也很大的话,根据MongoDB库级别读写锁的机制,
很可能复制写入程序拿不到写锁,从而导致副本节点与主节点有较大延迟。
如果进行读写分离,首先需要在副本节点声明其为slave,
db.getMongo().setSlaveOk();
其中的ReadRreference有几种设置:
primary:默认参数,只从主节点上进行读取操作;
primaryPreferred:大部分从主节点上读取数据,只有主节点不可用时从secondary节点读取数据。
secondary:只从secondary节点上进行读取操作,存在的问题是secondary节点的数据会比primary节点数据“旧”。
secondaryPreferred:优先从secondary节点进行读取操作,secondary节点不可用时从主节点读取数据;
nearest:不管是主节点、secondary节点,从网络延迟最低的节点上读取数据。
MongoDB客户端配置,可以提出来做成spring注入,设置最大连接数什么的。
MongoClientOptions options = MongoClientOptions.builder().maxWaitTime(1000 * 60 * 2) .connectionsPerHost(500).build(); mongoClient = new MongoClient(Arrays.asList(new ServerAddress("10.205.68.57", 8700), new ServerAddress("10.205.68.15", 8700), new ServerAddress("10.205.69.13", 8700)), options); mongoClient.setReadPreference(ReadPreference.secondaryPreferred());