DStream的转换操作和输出、累加器等:
转换
DStream上的原语分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window相关的原语。
| Transformation |
Meaning |
| map(func) |
将源DStream中的每个元素通过一个函数func从而得到新的DStreams。 |
| flatMap(func) |
和map类似,但是每个输入的项可以被映射为0或更多项。 |
| filter(func) |
选择源DStream中函数func判为true的记录作为新DStreams |
| repartition(numPartitions) |
通过创建更多或者更少的partition来改变此DStream的并行级别。 |
| union(otherStream) |
联合源DStreams和其他DStreams来得到新DStream |
| count() |
统计源DStreams中每个RDD所含元素的个数得到单元素RDD的新DStreams。 |
| reduce(func) |
通过函数func(两个参数一个输出)来整合源DStreams中每个RDD元素得到单元素RDD的DStreams。这个函数需要关联从而可以被并行计算。 |
| countByValue() |
对于DStreams中元素类型为K调用此函数,得到包含(K,Long)对的新DStream,其中Long值表明相应的K在源DStream中每个RDD出现的频率。 |
| reduceByKey(func, [numTasks]) |
对(K,V)对的DStream调用此函数,返回同样(K,V)对的新DStream,但是新DStream中的对应V为使用reduce函数整合而来。Note:默认情况下,这个操作使用Spark默认数量的并行任务(本地模式为2,集群模式中的数量取决于配置参数spark.default.parallelism)。你也可以传入可选的参数numTaska来设置不同数量的任务。 |
| join(otherStream, [numTasks]) |
两DStream分别为(K,V)和(K,W)对,返回(K,(V,W))对的新DStream。 |
| cogroup(otherStream, [numTasks]) |
两DStream分别为(K,V)和(K,W)对,返回(K,(Seq[V],Seq[W])对新DStreams |
| transform(func) |
将RDD到RDD映射的函数func作用于源DStream中每个RDD上得到新DStream。这个可用于在DStream的RDD上做任意操作。 |
| updateStateByKey(func) |
得到”状态”DStream,其中每个key状态的更新是通过将给定函数用于此key的上一个状态和新值而得到。这个可用于保存每个key值的任意状态数据。 |
DStream 的转化操作可以分为无状态(stateless)和有状态(stateful)两种。
在无状态转化操作中,每个批次的处理不依赖于之前批次的数据。常见的 RDD 转化操作,例如 map()、filter()、reduceByKey() 等,都是无状态转化操作。
相对地,有状态转化操作需要使用之前批次的数据或者是中间结果来计算当前批次的数据。有状态转化操作包括基于滑动窗口的转化操作和追踪状态变化的转化操作。
无状态转化
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。部分无状态转化操作列在了下表中。注意,针对键值对的 DStream 转化操作(比如reduceByKey())要添加import StreamingContext._ 才能在Scala中使用。
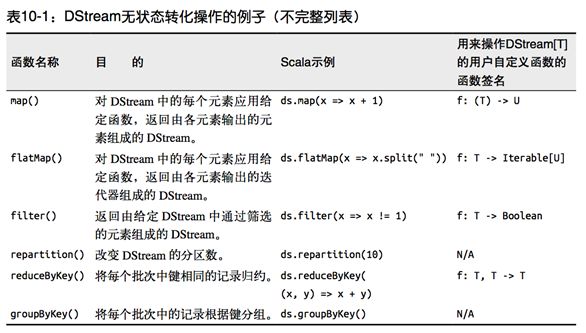
尽管这些函数看起来像作用在整个流上一样,但事实上每个 DStream 在内部是由许多 RDD(批次)组成,且无状态转化操作是分别应用到每个 RDD 上的。例如, reduceByKey() 会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
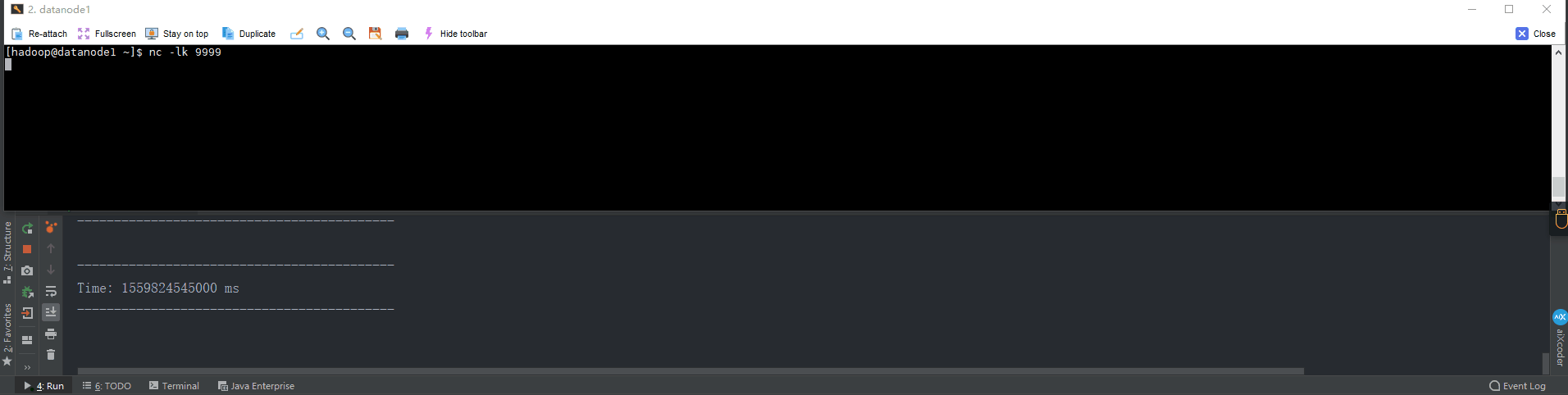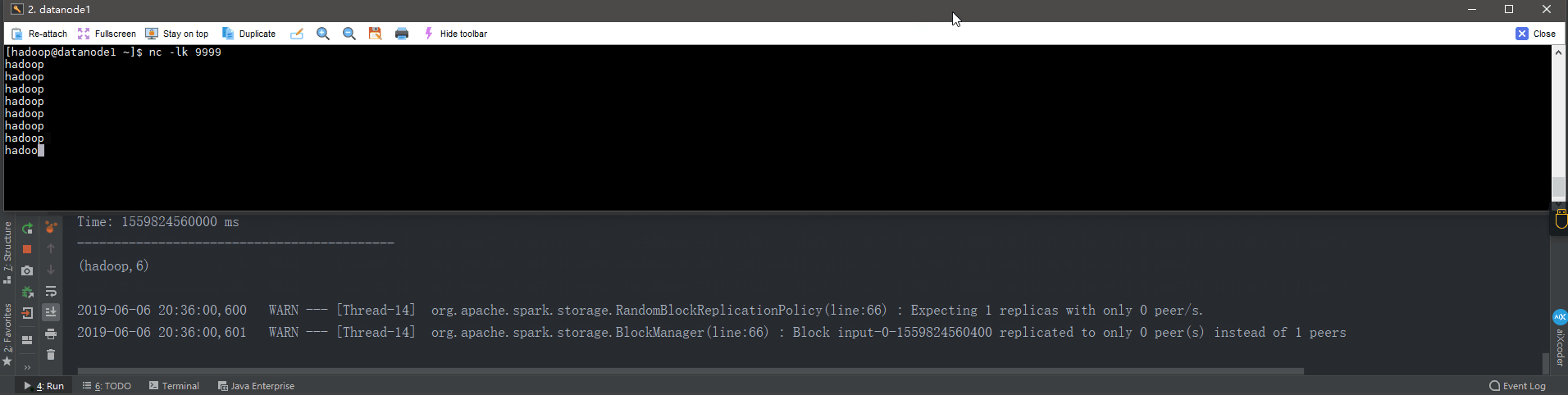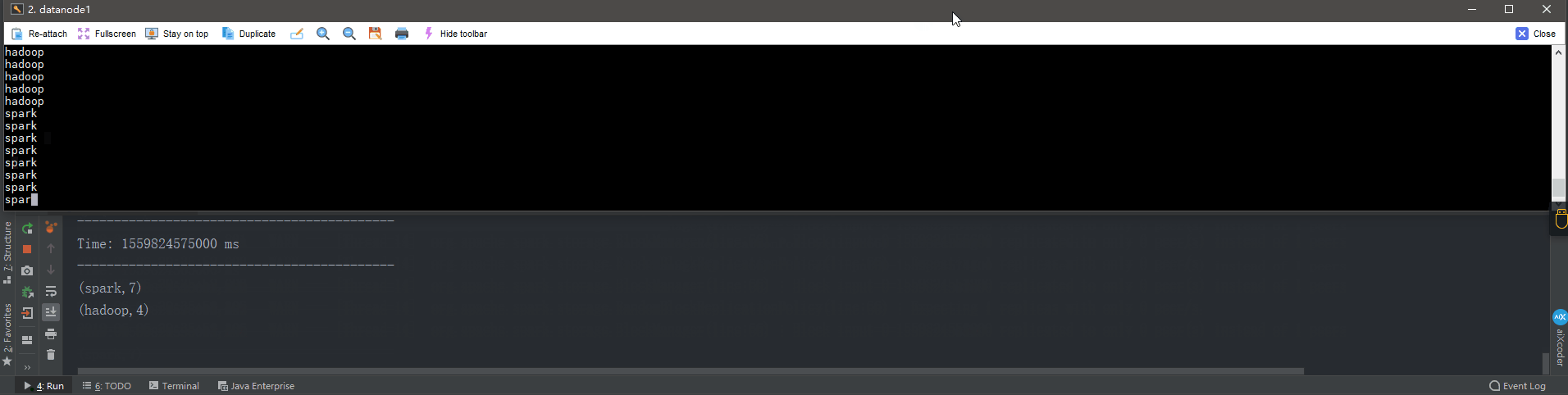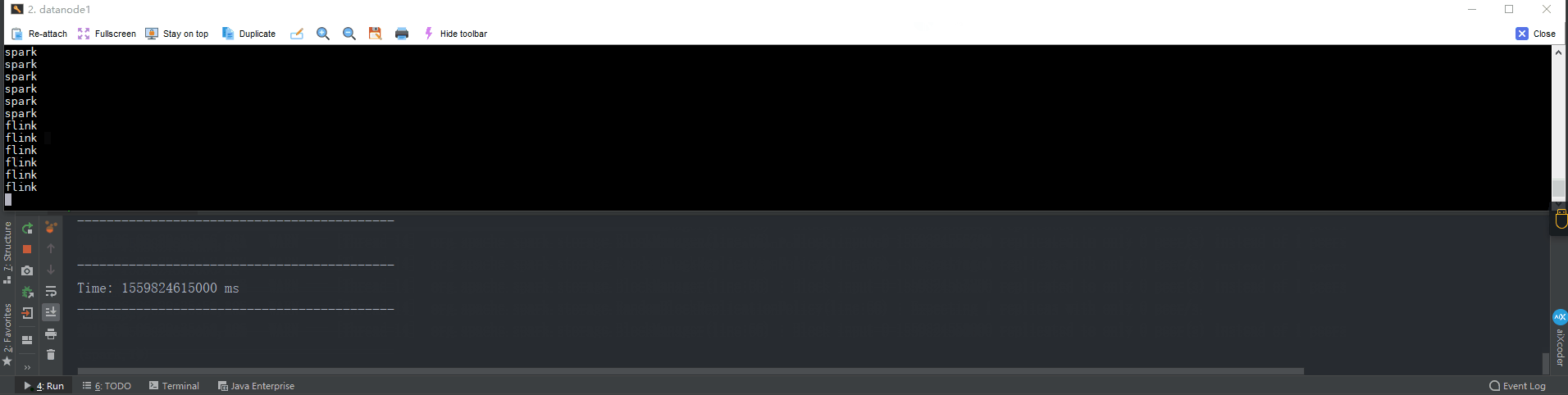
举个例子,在之前的wordcount程序中,我们只会统计1秒内接收到的数据的单词个数,而不会累加。
无状态转化操作也能在多个 DStream 间整合数据,不过也是在各个时间区间内。例如,键 值对 DStream 拥有和 RDD 一样的与连接相关的转化操作,也就是 cogroup()、join()、 leftOuterJoin() 等。我们可以在 DStream 上使用这些操作,这样就对每个批次分别执行了对应的 RDD 操作。
我们还可以像在常规的 Spark 中一样使用 DStream 的 union() 操作将它和另一个 DStream 的内容合并起来,也可以使用 StreamingContext.union() 来合并多个流。
有状态转化
UpdateStateByKey原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加wordcount)。针对这种情况,updateStateByKey() 为我们提供了对一个状态变量的访问,用于键值对形式的 DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件 更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
updateStateByKey() 的结果会是一个新的 DStream,其内部的 RDD 序列是由每个时间区间对应的(键,状态)对组成的。
updateStateByKey操作使得我们可以在用新信息进行更新时保持任意的状态。
1
2
3
4
5
|
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner())
}
|
状态存储在CheckPoint中,类似于一个HashMap,key就是KV结构的Key,updateFunc中的seq[V]是Rdd中所有Value的集合,第一个Option[s]是上一次的状态,第二个Option[S]是新产生的状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StateFulWordCount extends App {
val sparkConf = new SparkConf().setAppName("Stateful WordCount").setMaster("local[*]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setCheckpointDir("./checkpoint")
val line = ssc.socketTextStream("datanode1", 9999)
val words = line.flatMap(_.split(" "))
val word2Count = words.map((_, 1))
val state = word2Count.updateStateByKey[Int] { (values: Seq[Int], state: Option[Int]) =>
state match {
case None => Some(values.sum)
case Some(pre) => Some(values.sum + pre)
}
}
state.print()
ssc.start()
ssc.awaitTermination()
}
|
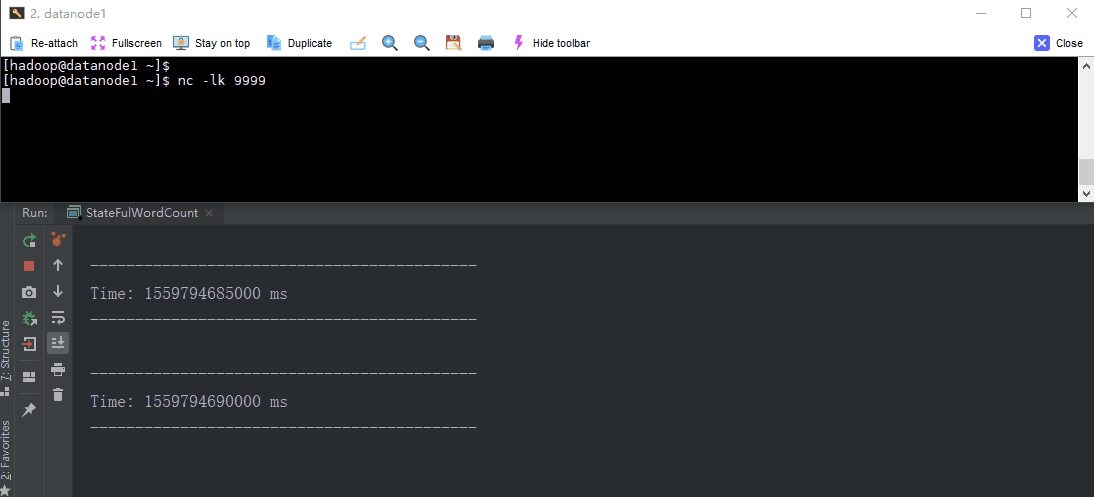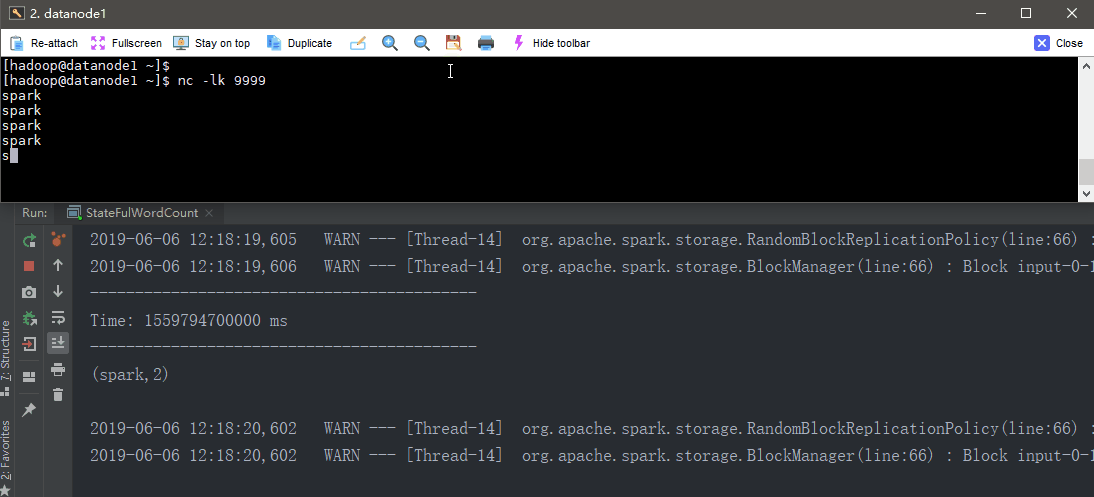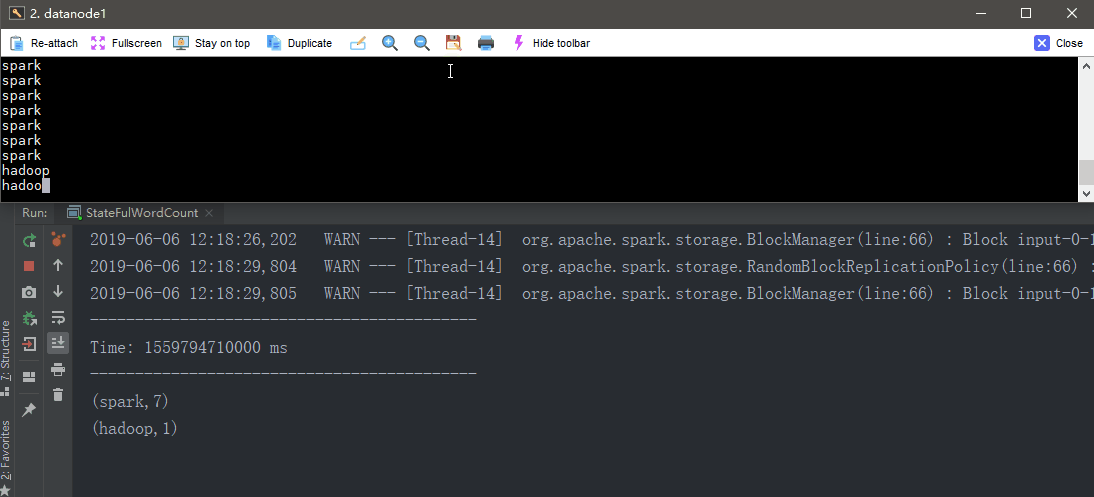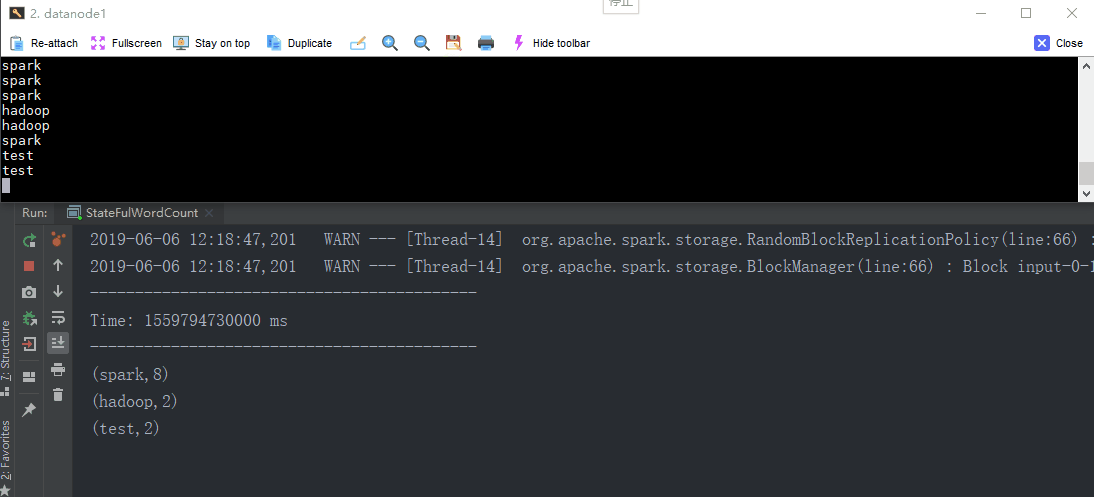
Window Operations
Window Operations 以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming的允许状态。
基于窗口的操作会在一个比 StreamingContext 的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长,两者都必须是 StreamContext 的批次间隔的整数倍。窗口时长控制每次计算最近的多少个批次的数据,其实就是最近的 windowDuration/batchInterval 个批次。如果有一个以 10 秒为批次间隔的源 DStream,要创建一个最近 30 秒的时间窗口(即最近 3 个批次),就应当把 windowDuration 设为 30 秒。而滑动步长的默认值与批次间隔相等,用来控制对新的 DStream 进行计算的间隔。如果源 DStream 批次间隔为 10 秒,并且我们只希望每两个批次计算一次窗口结果, 就应该把滑动步长设置为 20 秒。
假设,你想拓展前例从而每隔十秒对持续30秒的数据生成word count。为做到这个,我们需要在持续30秒数据的(word,1)对DStream上应用reduceByKey。使用操作reduceByKeyAndWindow.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object PairDstreamFunctions extends App {
val sparkConf = new SparkConf().setAppName("stateful").setMaster("local[*]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setCheckpointDir("./checkpoint")
val lines = ssc.socketTextStream("datanode1", 9999)
val words = lines.flatMap(_.split(" "))
val word2Count = words.map((_, 1))
val state = word2Count.reduceByKeyAndWindow((a: Int, b: Int) => a + b, Seconds(15), Seconds(5))
state.print()
ssc.start()
ssc.awaitTermination()
}
|
DStreams输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。与 RDD 中的惰性求值类似,如果一个 DStream 及其派生出的 DStream 都没有被执行输出操作,那么这些 DStream 就都不会被求值。如果 StreamingContext 中没有设定输出操作,整个 context 就都不会启动。
| Output Operation |
Meaning |
| print() |
在运行流程序的驱动结点上打印DStream中每一批次数据的最开始10个元素。这用于开发和调试。在Python API中,同样的操作叫pprint()。 |
| saveAsTextFiles(prefix, [suffix]) |
以text文件形式存储这个DStream的内容。每一批次的存储文件名基于参数中的prefix和suffix。”prefix-Time_IN_MS[.suffix]”. |
| saveAsObjectFiles(prefix, [suffix]) |
以Java对象序列化的方式将Stream中的数据保存为 SequenceFiles . 每一批次的存储文件名基于参数中的为”prefix-TIME_IN_MS[.suffix]”. Python中目前不可用。 |
| saveAsHadoopFiles(prefix, [suffix]) |
将Stream中的数据保存为 Hadoop files. 每一批次的存储文件名基于参数中的为”prefix-TIME_IN_MS[.suffix]”. Python API Python中目前不可用。 |
| foreachRDD(func) |
这是最通用的输出操作,即将函数func用于产生于stream的每一个RDD。其中参数传入的函数func应该实现将每一个RDD中数据推送到外部系统,如将RDD存入文件或者通过网络将其写入数据库。注意:函数func在运行流应用的驱动中被执行,同时其中一般函数RDD操作从而强制其对于流RDD的运算。 |
通用的输出操作 foreachRDD(),它用来对 DStream 中的 RDD 运行任意计算。这和transform() 有些类似,都可以让我们访问任意 RDD。在 foreachRDD() 中,可以重用我们在 Spark 中实现的所有行动操作。比如,常见的用例之一是把数据写到诸如 MySQL 的外部数据库中。
需要注意的:
连接不能写在driver层面
如果写在foreach则每个RDD都创建,得不偿失
增加foreachPartition,在分区创建
可以考虑使用连接池优化
我们写一个Mysql连接池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
import java.sql.Connection;
import java.sql.DriverManager;
import java.util.LinkedList;
public class ConnectionPool {
private static LinkedList<Connection> connectionQueue;
static {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public synchronized static Connection getConnection() {
try {
if (connectionQueue == null) {
connectionQueue = new LinkedList<Connection>();
for (int i = 0; i < 5; i++) {
Connection conn = DriverManager.getConnection(
"jdbc:mysql://192.168.1.101:3306/sparkstreaming",
"root",
"123456");
connectionQueue.push(conn);
}
}
} catch (Exception e) {
e.printStackTrace();
}
return connectionQueue.poll();
}
public static void returnConnection(Connection conn) {
connectionQueue.push(conn);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
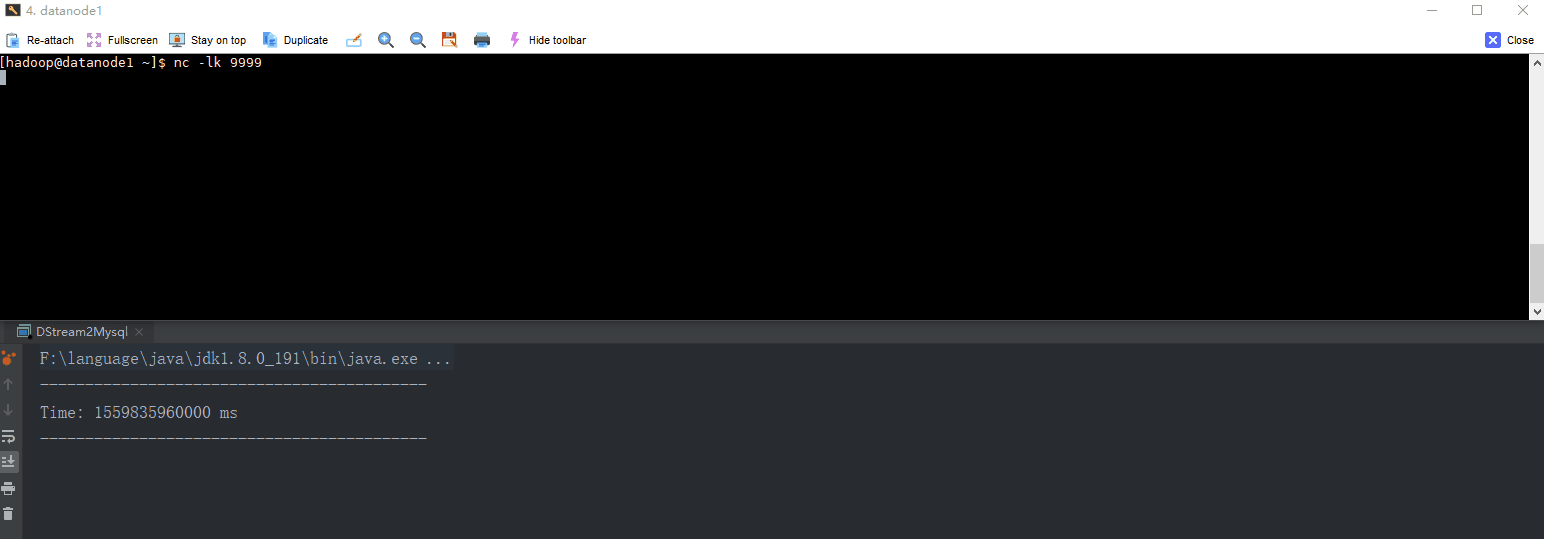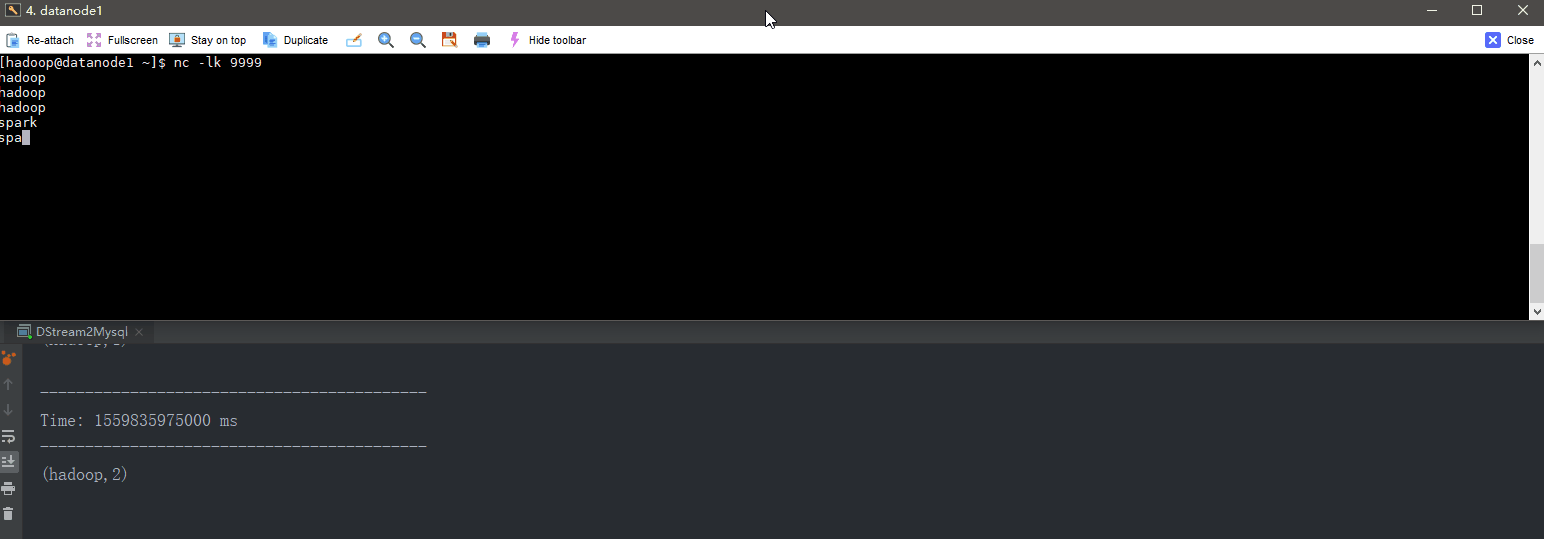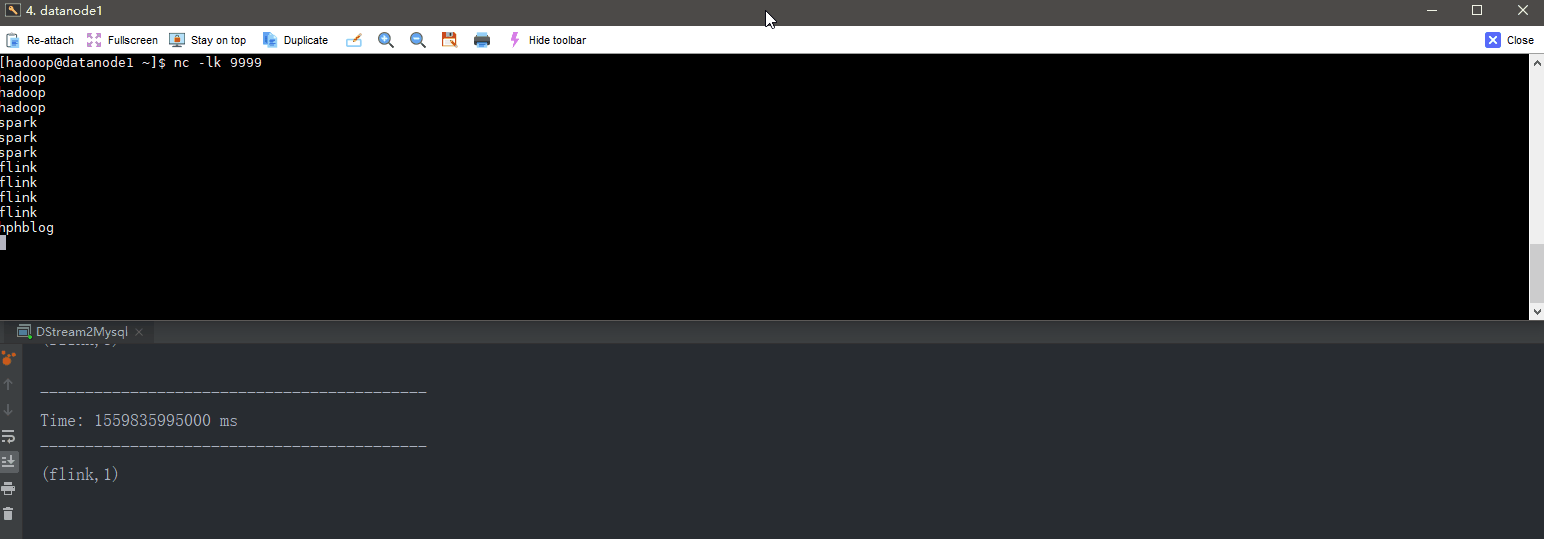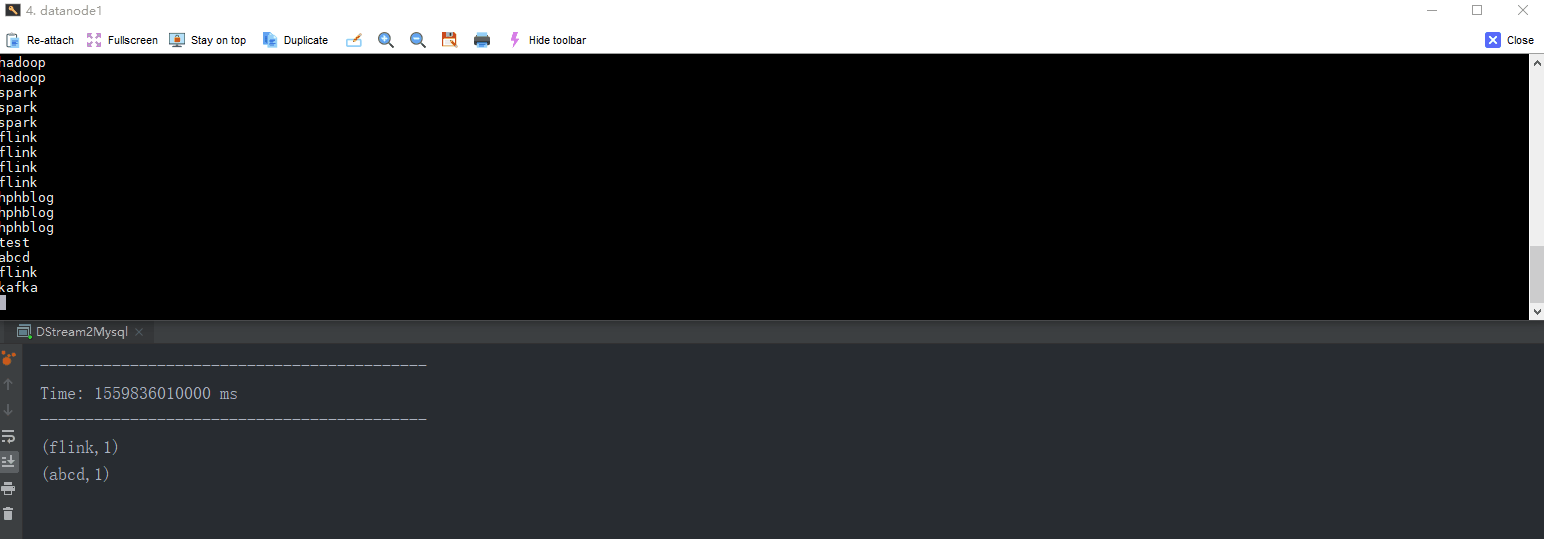
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DStream2Mysql extends App {
val sparkConf = new SparkConf().setAppName("stateful").setMaster("local[*]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val lines = ssc.socketTextStream("datanode1", 9999)
val words = lines.flatMap(_.split(" "))
val word2Count = words.map((_, 1)).reduceByKey(_ + _)
word2Count.print()
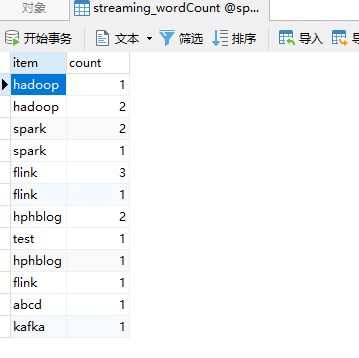
word2Count.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords => {
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => {
val sql = "insert into streaming_wordCount(item,count) values('" + record._1 + "'," + record._2 + ")"
val stmt = connection.createStatement();
stmt.executeUpdate(sql);
})
ConnectionPool.returnConnection(connection)
}
}
}
ssc.start()
ssc.awaitTermination()
}
|
累加器广播变量
累加器(Accumulators)和广播变量(Broadcast variables)不能从Spark Streaming的检查点中恢复。如果你启用检查并也使用了累加器和广播变量,那么你必须创建累加器和广播变量的延迟单实例从而在驱动因失效重启后他们可以被重新实例化。如下例述:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
import org.apache.spark.SparkContext
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.util.LongAccumulator
object WordBlacklist {
@volatile private var instance: Broadcast[Seq[String]] = null
def getInstance(sc: SparkContext): Broadcast[Seq[String]] = {
if (instance == null) {
synchronized {
if (instance == null) {
val wordBlacklist = Seq("flink", "spark", "hadoop")
instance = sc.broadcast(wordBlacklist)
}
}
}
instance
}
}
object DroppedWordsCounter {
@volatile private var instance: LongAccumulator = null
def getInstance(sc: SparkContext): LongAccumulator = {
if (instance == null) {
synchronized {
if (instance == null) {
instance = sc.longAccumulator("WordsInBlacklistCounter")
}
}
}
instance
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext, Time}
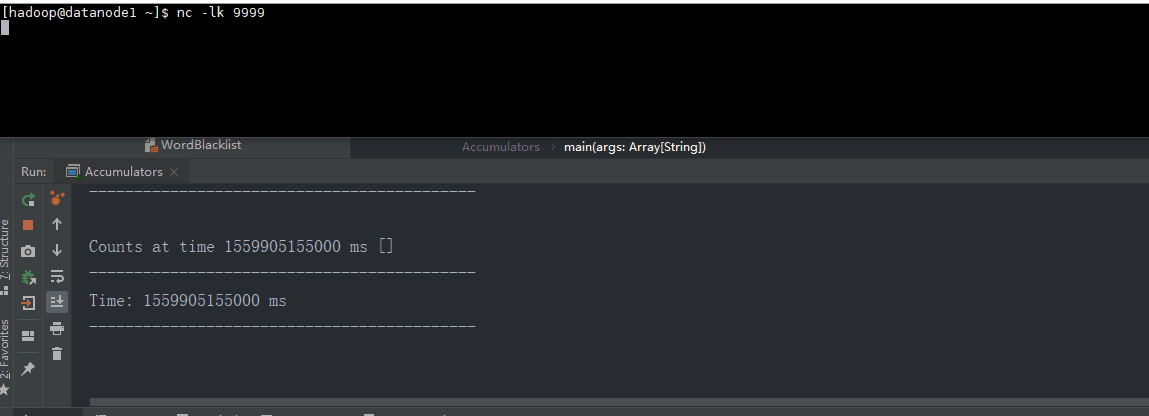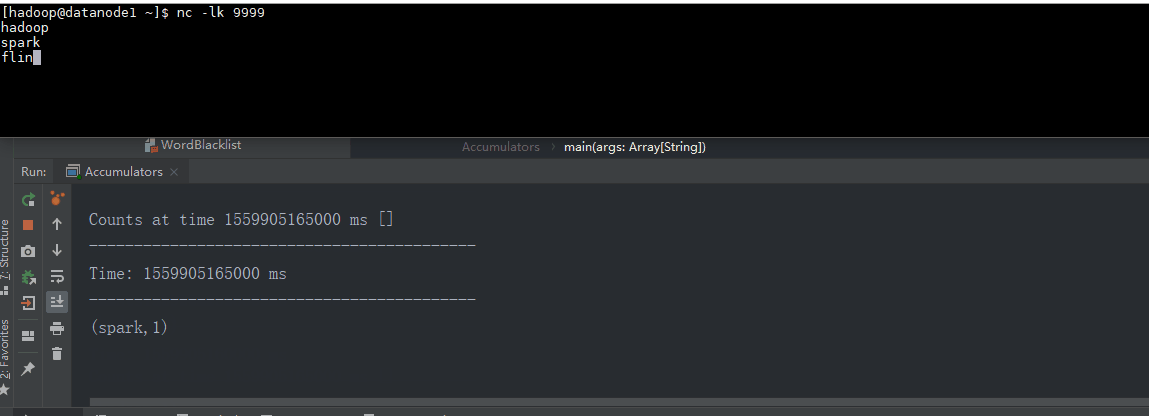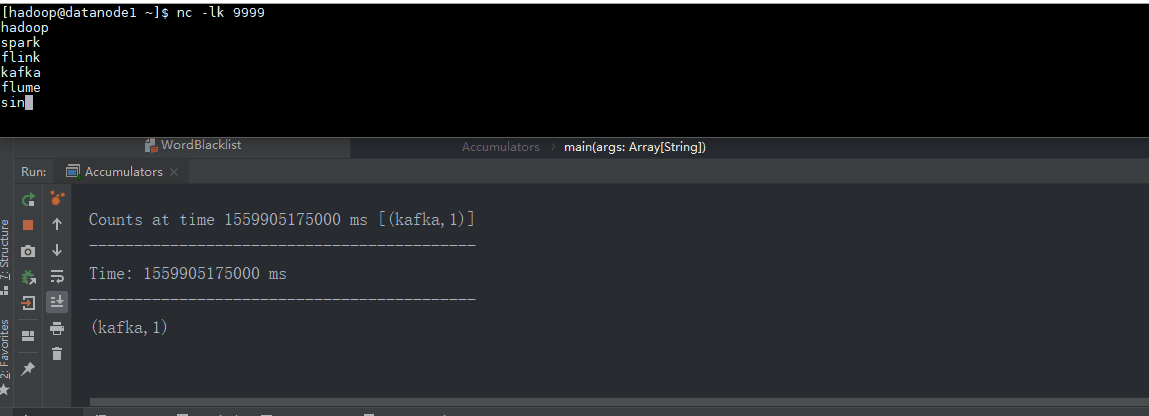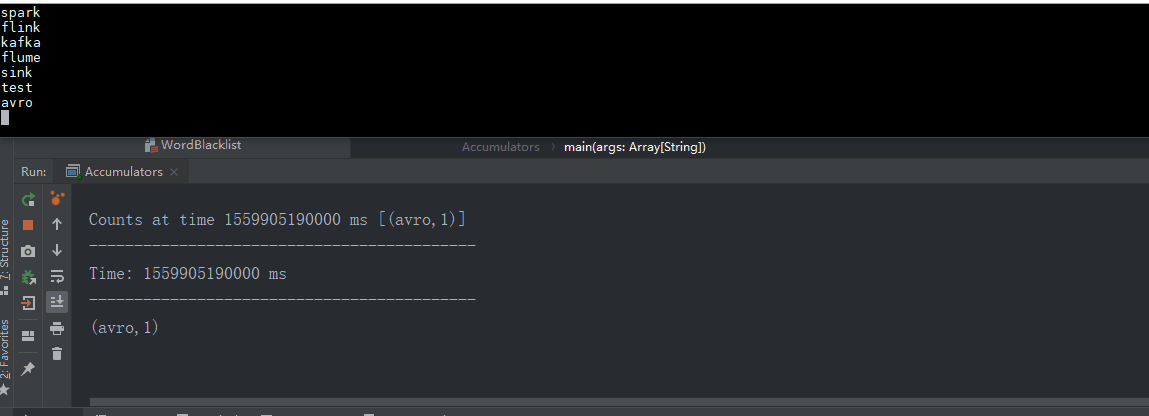
object Accumulators {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("Streaming_AccumulatorAndBroadcast").setMaster("local[*]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val lines = ssc.socketTextStream("datanode1", 9999)
val words = lines.flatMap(_.split(","))
val wordCounts = words.map((_, 1)).reduceByKey(_ + _)
wordCounts.foreachRDD { (rdd: RDD[(String, Int)], time: Time) =>
val blacklist = WordBlacklist.getInstance(rdd.sparkContext)
val droppedWordsCounter = DroppedWordsCounter.getInstance(rdd.sparkContext)
val counts = rdd.filter { case (word, count) =>
if (blacklist.value.contains(word)) {
droppedWordsCounter.add(count)
false
} else {
true
}
}.collect().mkString("[", ", ", "]")
val output = "Counts at time " + time + " " + counts
println(output)
}
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
|
DataFrame ans SQL Operations
你可以很容易地在流数据上使用DataFrames和SQL。你必须使用SparkContext来创建StreamingContext要用的SQLContext。此外,这一过程可以在驱动失效后重启。我们通过创建一个实例化的SQLContext单实例来实现这个工作。如下例所示。我们对前例word count进行修改从而使用DataFrames和SQL来产生word counts。每个RDD被转换为DataFrame,以临时表格配置并用SQL进行查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Minutes, Seconds, StreamingContext}
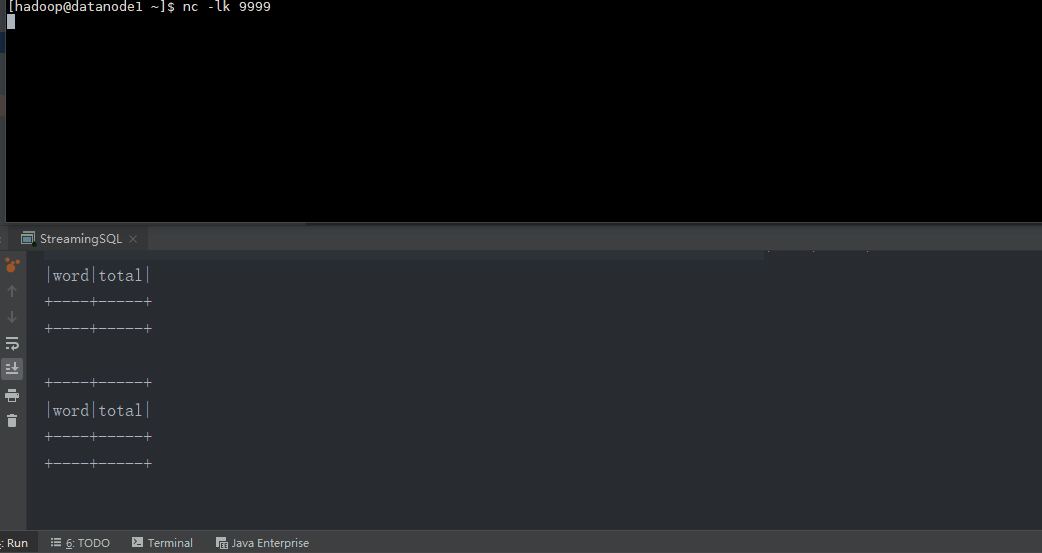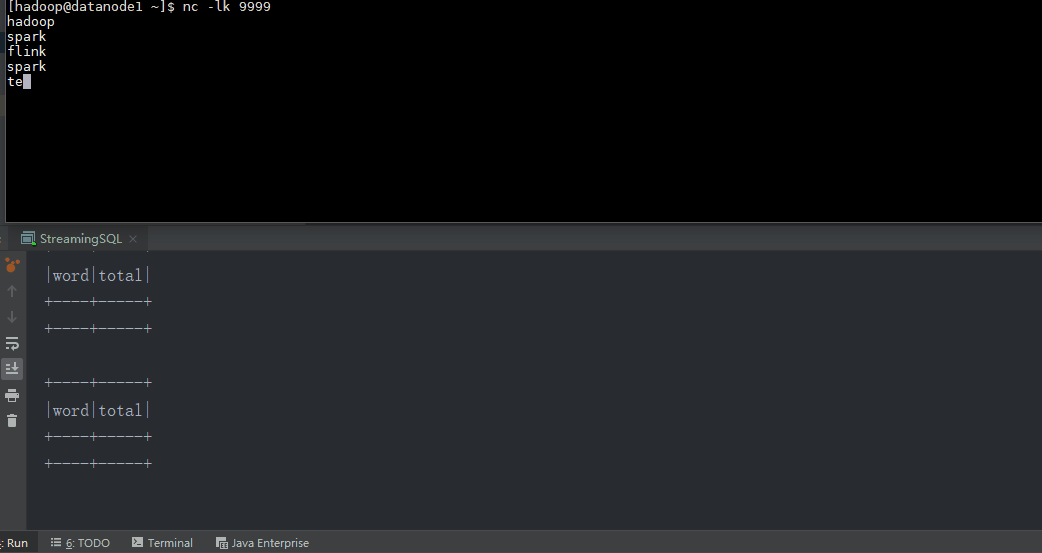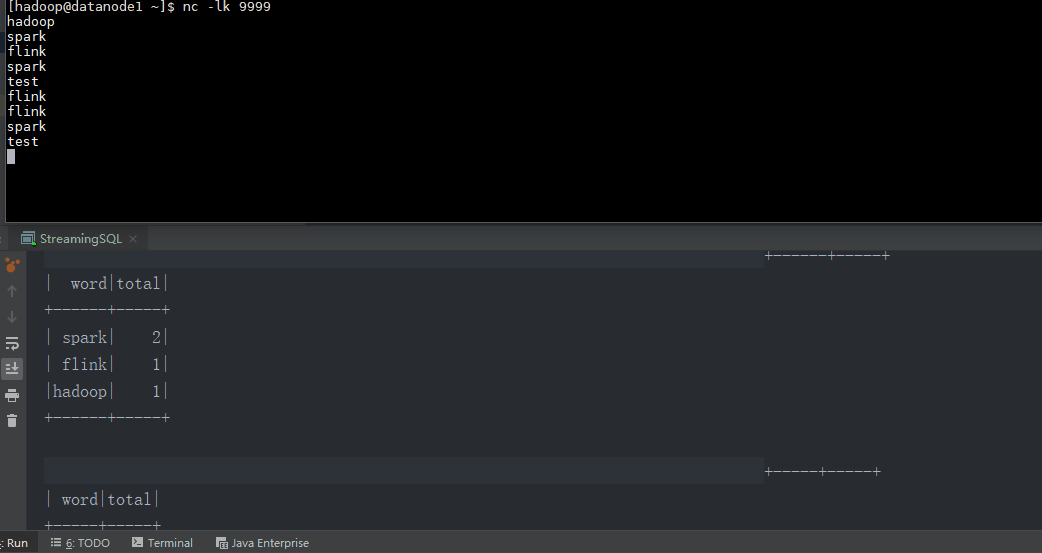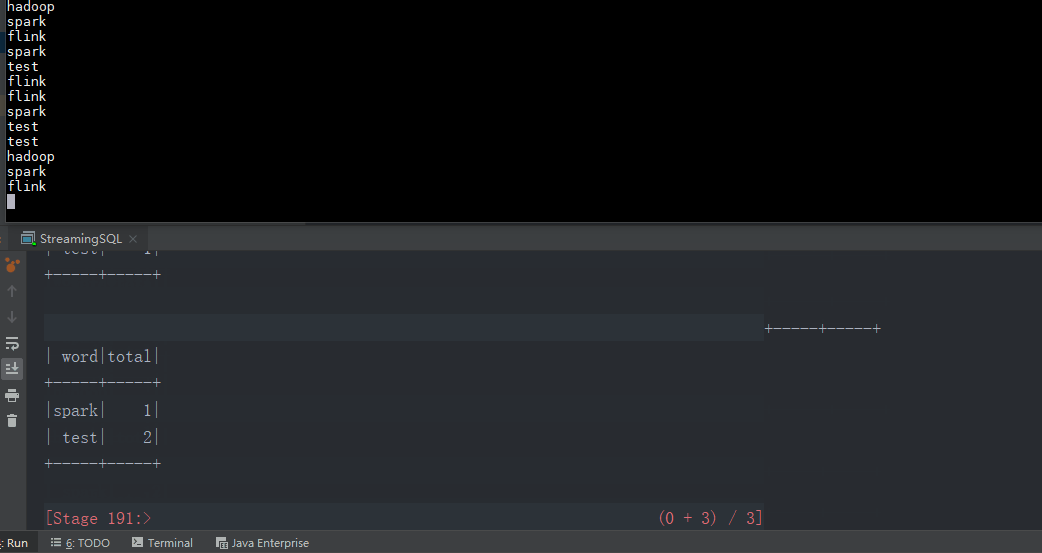
object StreamingSQL {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkStreaming SQL").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(5))
val linesDStream = ssc.socketTextStream("datanode1", 9999)
linesDStream.foreachRDD { rdd =>
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
val wordsDataFrame = rdd.toDF("word")
wordsDataFrame.createOrReplaceTempView("words")
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}
ssc.start()
ssc.awaitTermination()
}
}
|
Caching / Persistence
DStreams允许开发者将流数据保存在内存中。也就是说,在DStream上使用persist()方法将会自动把DStreams中的每个RDD保存在内存中。当DStream中的数据要被多次计算时,这个非常有用(如在同样数据上的多次操作)。对于像reduceByWindow和reduceByKeyAndWindow以及基于状态的(updateStateByKey)这种操作,保存是隐含默认的。因此,即使开发者没有调用persist(),由基于窗操作产生的DStreams会自动保存在内存中。