使用ggplot2进行数据可视化:散点图篇
使用ggplot2进行数据可视化:散点图篇
The simple graph has brought more information to the data analyst’s mind than any other device. —John Tukey
在数据分析中,进行数据可视化是一个重要的步骤。在前期对数据进行初步探索时,数据可视化会让我们对数据有一个初步的了解;而在后期进行分析和交流时,数据可视化可以为别人提供更加有效、易读的信息。
在R语言中,有这两个绘图系统:传统绘图系统和Grid绘图系统,此外还有两个基于Grid绘图系统的主流拓展包:lattice和ggplot2。在这里主要介绍的是ggplot2包在数据可视化中的运用。ggplot2提供了全面的、基于语法的、连贯一致的图形生成系统,允许用户创建新颖的、有创造性的数据可视化图形。虽然ggplot2的学习曲线陡峭,但是只要掌握其语法规则,能够在很短的时间内生成达到出版水平的图形。所以,ggplot2是R数据可视化中重要的扩展包。
使用散点图观察两个连续性变量的关系
有时候,我们想要知道两个连续性变量是否存在某种关系,如线性、非线性、正相关、负相关等等,我们通常绘制散点图初步观察这种关系是否存在。
使用的示例数据集
在这里,我们主要是用的数据集是“mpg”。该数据集包含了1999-2008年部分车型以及其燃料消耗等数据。该数据集是ggplot2包一个示例数据集,我们可以使用查看该数据集前几行:
library(ggplot2)
data(mpg)
head(mpg)
# A tibble: 6 x 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compact
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compact
3 audi a4 2.0 2008 4 manual(m6) f 20 31 p compact
4 audi a4 2.0 2008 4 auto(av) f 21 30 p compact
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compact
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compact 此外,可以使用?mpg在Rstudio上查看详细的解释。
散点图的可视化
在这里,我们想要知道的是,发动机排量(displ)和燃油效率(hwy)之间存在什么关系。
- displ:发动机的排放量,单位升;
- hwy:highway miles per gallon,每加仑汽油行驶的距离,单位米/加仑。
根据平时的经验来看,发动机排量越小,每加仑汽油行驶的距离就越长,即,燃油效率就越高。 那么在这个数据集中,是怎样的一种情况呢?在散点图中,我们可以观察到他们之间的关系。使用ggpolot2进行散点图的绘制代码如下:
library(ggplot2)
ggplot(mpg,mapping = aes(x=displ,y=hwy))+
geom_point()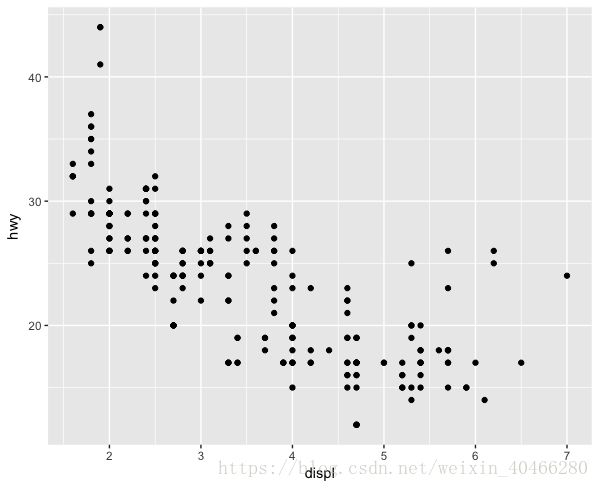
我们可以从上图看到,随着发动机排量的升高,每加仑汽油行驶的距离就越短,发动机排量和燃油效率存在着线性的关系。对于上述的代码,ggplot2到底是如何工作的?
在ggplot2中,我们是首先需要告诉函数使用哪一个数据集,然后给他规定横轴和纵轴分别表示哪些变量。在上面的代码中,我们在ggplot()函数中规定了数据集以及横纵坐标所代表的变量。然而单单使用ggplot()函数仅仅只能生成一个横纵坐标轴(下图)。所以我们还需要告诉系统,我们想要画的是什么类型的图,这个由geom_point()函数来告诉系统,我们想画的是散点图。geom_point()这种函数称为几何函数,在ggplot2中,这样的几何函数有很多,如条形图 :geom_bar(),箱线图:goem_boxplot(),直方图:geom_histogram()等等。
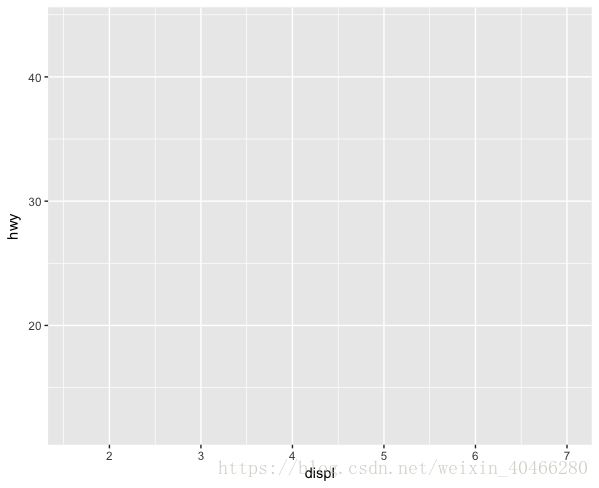
我们在使用ggolot(mpg,mapping = aes(x=displ,y=hwy))时,我们已经将横轴和纵轴的变量设为了全局变量。全局变量意味着后续的图形全部是在这个横纵坐标下绘制的,比如,我们想添加一条光滑在这个图形的基础上添加一条光滑的曲线:
ggplot(mpg,mapping = aes(x=displ,y=hwy))+
geom_point()+
geom_smooth()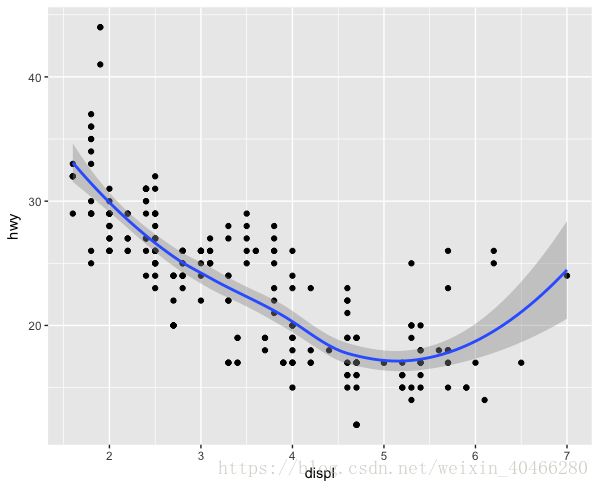
除了这种方法外,我们还可以在几何函数下为每一个图形设置其横轴及纵轴,当这样设置时,意味着设置的横轴与纵轴的变量仅仅适用于这个几何函数。下面的代码表示使用displ和hwy变量绘制散点图,使用displ和cty变量绘制光滑曲线:
ggplot(mpg)+
geom_point(mapping = aes(x=displ,y=hwy))+
geom_smooth(mapping = aes(x=displ,y=cty))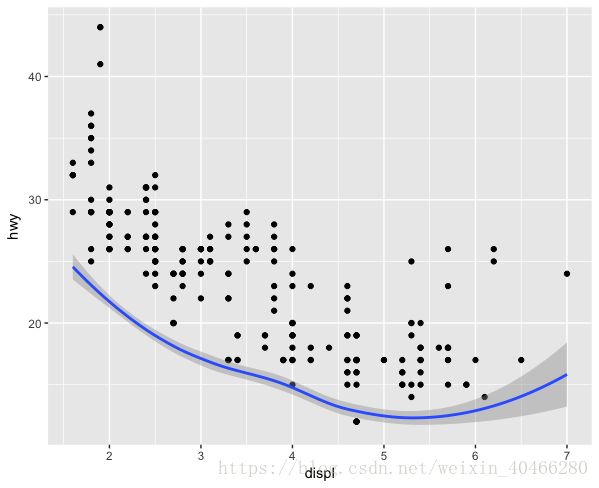
虽然纵轴显示的是hwy,但是光滑曲线并不是hwy为纵轴进行绘制的。
分组
重新审视图一的散点图,我们发现有一些异常值,出乎我们的意料:这些车在大排量下居然也有着较好的燃油效率。这些异常值的是否与其他的因素有关,和什么因素有关?这些在总体的数据中我们无法观察到不同。所以我们需要对这些数据进行分组。在这个数据集中,我们注意到车辆有着不同的类型,因此,我们选择对其车型进行分组,看看不同组别的汽车有什么不同。
在ggplot2中,可以很简便的看到各个分组的情况:
ggplot(mpg,mapping = aes(x=displ,y=hwy,colour = class))+
geom_point()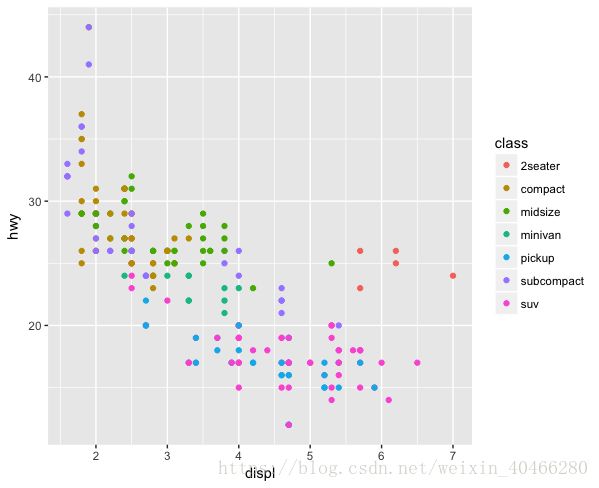
需要注意的是,ggplot2中,分组的函数必须放在aes()中,否则这会出现错误。
分组之后,我们发现异常值基本都属于一种车型:2seater。这种车型是一种跑车,拥有者大排量的发动机和较轻的车身,所以使其在同样的排量下,能够拥有着更好的燃油效率。
在ggplot2中,不仅仅可以使用颜色进行分组,还可以使用形状(shape)、透明度(alpha)、大小(size)进行分组。当然,在某些情况下,某种分组的效果不一定合适。在ggplot2中,一次只能使用最多六种形状(shape),所以在用形状进行分组的时候,会遇到下面的情况:
ggplot(mpg,mapping = aes(x=displ,y=hwy,shape = class))+
geom_point()
Warning messages:
1: The shape palette can deal with a maximum of 6 discrete values
because more than 6 becomes difficult to discriminate; you have
7. Consider specifying shapes manually if you must have them.
2: Removed 62 rows containing missing values (geom_point). 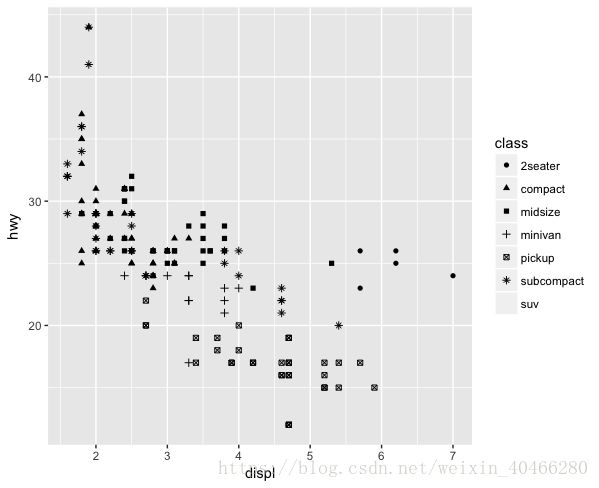
这时候,Suv不再显示。
选择子集
有时候,我们不想看所有的数据,只想看看SUV这一个车型不同排量和燃油效率的关系。那么应该如何进行绘图呢?
ggplot(data = mpg,mapping = aes(x=displ,y=hwy))+
geom_point(data = filter(mpg,class == "suv"))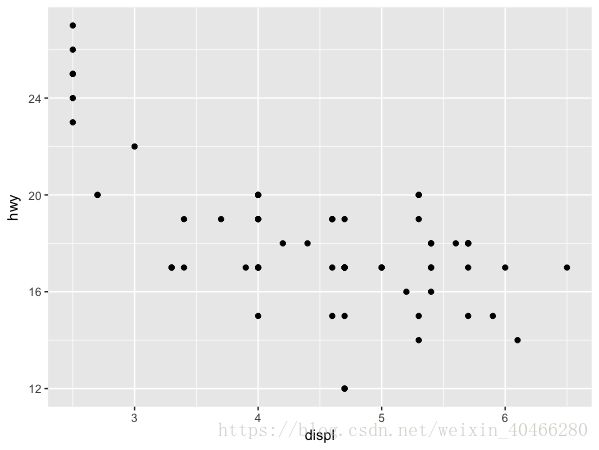
备注:在使用filter()函数时,需要载入dplyr包,不然会报错。
除了这种单一的提取出不同子集的方法外,我们还可以使用分面(Facets)将所有的子集绘制出来。
ggplot(data = mpg,mapping = aes(x=displ,y=hwy))+
geom_point()+
facet_wrap(~class,nrow = 2)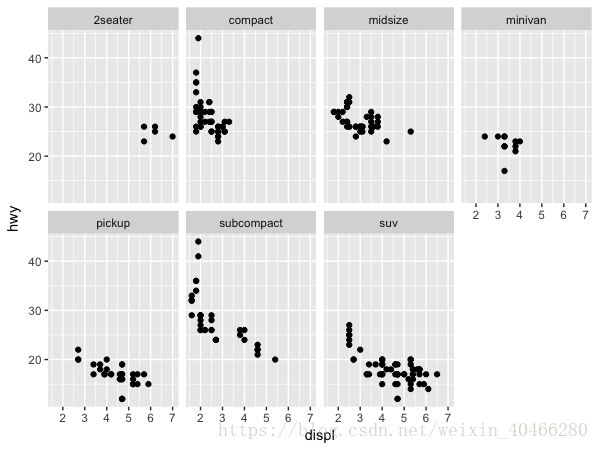
使用的函数facet_warp()需要添加一个公式型的参数,这是R中的一种数据结构形式,而不是指数学上的等式。这种表达方法在进行回归分析的时候经常会被使用。
这部分,我们查看了如何在ggplot2中初步探索两个变量之间的关系,如何绘制散点图,并且添加光滑曲线,如何用不同的形式表达不同的子集,如何绘制其中的一个子集,如何使用分面在一个图形中绘制不同的子集。接下来,我们将要探讨的是条形图在ggplot2中应该如何绘制。