Spark:实时数据微批处理(5.Spark Streaming及项目实战)
文章目录
- 1.Spark Streaming 概述
- 1.1 Spark Streaming是什么?
- 1.2 Spark Streaming特点
- 1.3 SparkStreaming 架构
- 2.DStream 创建案例实操
- 2.1 wordcount 案例
- 2.2 RDD 队列案例
- 2.3 自定义数据源案例
- 2.4 Kafka 数据源案例
- 2.4.1 Kafka 0-8 Receive模式
- 2.4.2 Kafka 0-8 Direct模式
- 2.4.3 Kafka 0-10 Direct模式
- 3.DStream 转换案例实操
- 3.1 无状态转换操作
- 3.1.1 transform操作案例
- 3.2 有状态的转换
- 3.2.1 updateStateByKey操作案例
- 3.2.2 window 操作案例
- 4.DStream 输出
- 4.1 案例1:saveAsTextFiles
- 4.2 案例2:写入到mysql
- 4.3 案例3:rdd转df写入到mysql
- 4.4 persist()方法
- 5.Spark Streaming 项目实战
- 5.1 准备数据
- 5.1.1 数据生成方式
- 5.1.2 数据生成模块
- 5.2 编写代码生成模拟数据
- 5.2.1 工具类: RandomNumUtil
- 5.2.2 工具类: RandomOptions
- 5.2.3 样例类: CityInfo
- 5.2.4 生成模拟数据: MockRealTime
- 5.3 从Kafka 读取数据
- 5.3.1 bean 类 AdsInfo
- 5.3.2 工具类 MyKafkaUtil
- 5.4 需求1:每天每地区热门广告 Top3
- 5.4.1 封装常用代码到特质APP
- 5.4.2 编写AreaAdsTopApp类实现需求
- 5.5 需求2:最近 1 小时广告点击量实时统计
1.Spark Streaming 概述
1.1 Spark Streaming是什么?
- 用于流式数据的处理,实时处理
- 数据可以来源于多种数据源: Kafka, Flume, Kinesis, 或者 TCP 套接字,被处理的数据可以发布到 FS, 数据库或者在线dashboards
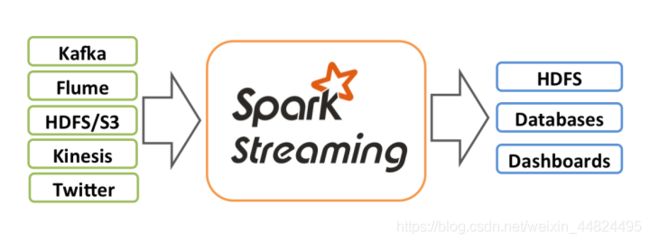
- 数据采集是逐条进行的,数据处理是批处理
1.2 Spark Streaming特点
-
易用
通过高阶函数来构建应用

-
容错

-
易整合到 Spark 体系中

-
缺点
Spark Streaming 是一种“微量批处理”架构, 和其他基于“一次处理一条记录”架构的系统相比, 它的延迟会相对高一些.
1.3 SparkStreaming 架构
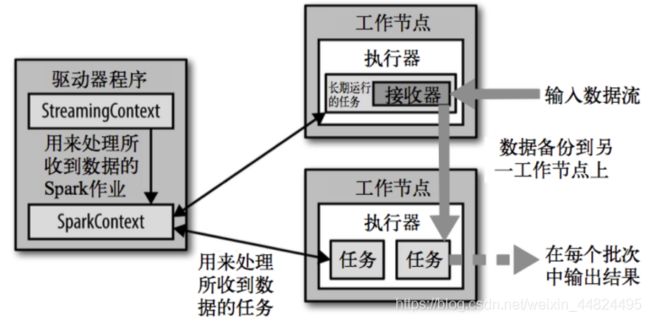 背压机制
背压机制
Spark 1.5以前版本,用户如果要限制 Receiver 的数据接收速率,可以通过设置 静态配制参数spark.streaming.receiver.maxRate 的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5版本开始 Spark Streaming 可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即Spark Streaming Backpressure): 根据 JobScheduler 反馈作业的执行信息来动态调整 Receiver 数据接收率。
通过属性 spark.streaming.backpressure.enabled 来控制是否启用backpressure机制,默认值false,即不启用。
2.DStream 创建案例实操
2.1 wordcount 案例
- 需求
使用 netcat 工具向 9999 端口不断的发送数据,通过 Spark Streaming 读取端口数据并统计不同单词出现的次数
安装netcat工具:sudo yum -y install nc
- 添加依赖
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>2.1.1version>
dependency>
dependencies>
- 编写代码
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author jaffe
* @Date 2020/05/16 10:23
*/
object WordCount {
def main(args: Array[String]): Unit = {
//1 SparkContext的初始化需要一个SparkConf对象,SparkConf包含了Spark集群配置的各种参数
val conf = new SparkConf().setMaster("local[2]").setAppName("WordCount")
//2 创建SparkStreaming的入口对象: StreamingContext 参数2: 表示事件间隔 内部会创建 SparkContext
val ssc = new StreamingContext(conf, Seconds(3))
//3 从数据源读取数据,得到DStream (RDD,Dataset,DataFram)
//3.1 从socket读取数据
val sourceStram: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop103", 9999)
//4 对DStream 做转换操作,得到目标数据
val resultStream = sourceStram
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
//5 显示并启动流
resultStream.print(100)
ssc.start()
//6 阻止程序退出,等待计算结束(要么手动退出,要么出现异常)才退出主程序
ssc.awaitTermination()
}
}
- 测试
- hadoop103 上启动 netcat,输入数据 bbbb a a a b b
nc -lk 9999
- 执行代码,查看输出结果

- 注意点
- 一旦StreamingContext已经启动, 则不能再添加添加新的 streaming computations
- 一旦一个StreamingContext已经停止(StreamingContext.stop()), 他也不能再重启
- 在一个 JVM 内, 同一时间只能启动一个StreamingContext
- stop() 的方式停止StreamingContext, 也会把SparkContext停掉. 如果仅仅想停止StreamingContext, 则应该这样: stop(false)
- 一个SparkContext可以重用去创建多个StreamingContext, 前提是以前的StreamingContext已经停掉,并且SparkContext没有被停掉
2.2 RDD 队列案例
-
用法及说明
测试过程中,可以通过使用ssc.queueStream(queueOfRDDs)来创建DStream,每一个推送到这个队列中的RDD,都会作为一个DStream处理 -
案例实操
需求:循环创建几个 RDD,将 RDD 放入队列。通过 Spark Streaming创建 Dstream,计算 WordCount
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
/**
* @Author jaffe
* @Date 2020/05/16 11:20
*/
object RDDQueue {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("RDDQueue")
val ssc = new StreamingContext(conf, Seconds(3))
// 创建一个可变队列
val queue = mutable.Queue[RDD[Int]]()
val stream = ssc.queueStream(queue)
val result = stream.reduce(_ + _)
result.print
ssc.start()
while (true) {
println(queue.size)
// 无限循环的方式向队列中添加 RDD
val rdd = ssc.sparkContext.parallelize(1 to 100)
queue.enqueue(rdd)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
}
2.3 自定义数据源案例
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.receiver.Receiver
/**
* @Author jaffe
* @Date 2020/05/16 14:03
*/
object MyReceiverDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MyReceiverDemo")
val ssc = new StreamingContext(conf, Seconds(3))
val stream = ssc.receiverStream(new MyReceiver("hadoop103", 10000))
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
stream.print
ssc.start()
ssc.awaitTermination()
}
}
class MyReceiver(host: String, port: Int) extends Receiver[String](storageLevel = StorageLevel.MEMORY_ONLY) {
var socket: Socket = _
var reader: BufferedReader = _
/*
接收器启动的时候调用该方法onStart. This function must initialize all resources (threads, buffers, etc.) necessary for receiving data.
这个函数内部必须初始化一些读取数据必须的资源
该方法不能阻塞, 所以 读取数据要在一个新的线程中进行.
*/
override def onStart(): Unit = {
// 定义runInThread方法,方法里启动一个新的线程来接收数据
runInThread {
try {
//从socket读数据
socket = new Socket(host, port)
reader =
new BufferedReader(new InputStreamReader(socket.getInputStream, "utf-8"))
var line = reader.readLine()
// 表示读到了数据循环发送给spark
while (line != null) {
store(line) // 发送给spark
line = reader.readLine() // 如果没有数据, 这里会阻塞, 等待数据的输入
}
} catch {
case e => println(e.getMessage)
} finally {
restart("重启接收器") // 先回调onStop, 再回调 onStart
}
}
}
/**
* 用来释放资源
*/
override def onStop(): Unit = {
if (reader != null) reader.close()
if (socket != null) socket.close()
}
// 把传入的代码运行在子线程
def runInThread(op: => Unit) = {
new Thread() {
override def run() = op
}.start()
}
}
2.4 Kafka 数据源案例
三个语义:
- 至多一次(高效, 数据丢失)
- 正好一次(最理想. 额外的很多工作, 效率最低)
- 至少一次(保证数据不丢失, 数据重复)
2.4.1 Kafka 0-8 Receive模式
ReceiverAPI:
需要一个专门的Executor去接收数据,然后发送给其他的Executor做计算。存在的问题,接收数据的Executor和计算的Executor速度会有所不同,特别在接收数据的Executor速度大于计算的Executor速度,会导致计算数据的节点内存溢出。
1.导依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-8_2.11artifactId>
<version>2.1.1version>
dependency>
2. 编写代码
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author jaffe
* @Date 2020/05/16 15:25
*/
object ReceiverAPI {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("ReceiverAPI")
val ssc = new StreamingContext(conf, Seconds(3))
// (k, v) k默认是 null, v 才是真正的数据
// key的用处: 决定数据的分区. 如果key null, 轮询的分区
val sourceStream = KafkaUtils.createStream(
ssc,
"hadoop102:2181,hadoop103:2181,hadoop104:2181/mykafka",
"jaffe",
Map("spark1128" -> 1) //1个分区来消费topic:spark1128
)
sourceStream
.map(_._2)
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.print
ssc.start()
ssc.awaitTermination()
}
}
3.启动zookeeper,kafka生产者生产数据
bin/kafka-console-producer.sh --broker-list hadoop103:9092 --topic spark1128
2.4.2 Kafka 0-8 Direct模式
DirectAPI:
是由计算的Executor来主动消费Kafka的数据,速度由自身控制
1.导依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-8_2.11artifactId>
<version>2.1.1version>
dependency>
案例1:自动维护offset
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka.KafkaUtils
/**
* @Author jaffe
* @Date 2020/05/16 16:27
*/
object DirectAPI {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("DirectAPI")
val ssc = new StreamingContext(conf, Seconds(3))
val param = Map[String, String](
"bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
"group.id" -> "jaffe"
)
val stream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc,
param,
Set("spark1128"))
stream
.map(_._2)
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.print
ssc.start()
ssc.awaitTermination()
}
}
案例2:Kafka消费->严格一次(checkpoint)
import kafka.serializer.StringDecoder
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Author jaffe
* @Date 2020/05/16 22:56
*/
object ReceiverAPI2 {
def createSSC():StreamingContext ={
println("create-----")
val conf = new SparkConf().setAppName("ReceiverAPI2").setMaster("local[2]")
val ssc = new StreamingContext(conf,Seconds(3))
ssc.checkpoint("./ck1")
val param = Map[String,String](
"bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
"group.id" -> "jaffe"
)
val stream = KafkaUtils
.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc,
param,
Set("spark1128")
)
stream
.map(_._2)
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.print
ssc
}
def main(args: Array[String]): Unit = {
val ssc = StreamingContext.getActiveOrCreate("./ck1",createSSC)
ssc.start()
ssc.awaitTermination()
}
}
2.4.3 Kafka 0-10 Direct模式
1.导依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.1.1</version>
</dependency>
2.代码
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.{KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author jaffe
* @Date 2020/05/18 09:17
*/
object DirectAPI2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("DirectAPI2")
val ssc = new StreamingContext(conf, Seconds(3))
val topic = Array("spark1128")
val kafkaParams: Map[String, Object] = Map[String, Object](
"bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
"key.deserializer" -> classOf[StringDeserializer], // key的反序列化器
"value.deserializer" -> classOf[StringDeserializer], // value的反序列化器
"group.id" -> "jaffe",
"auto.offset.reset" -> "latest", // 每次从最新的位置开始读
"enable.auto.commit" -> (true: java.lang.Boolean) // 自动提交kafka的offset
)
val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc,
locationStrategy = LocationStrategies.PreferConsistent, // 平均分布
Subscribe[String, String](topic, kafkaParams)
)
stream.map(_.value()).print()
ssc.start()
ssc.awaitTermination()
}
}
3.DStream 转换案例实操
3.1 无状态转换操作
无状态转化仅仅针对当前批次, 批次与批次之间没有关系。
针对聚合算子: 用的和RDD一样的算子都是无状态的算子
把简单的RDD转化操作应用到每个批次上,也就是转化DStream中的每一个RDD。部分无状态转化操作列在了下表中:

3.1.1 transform操作案例
流是由RDD组成
transform 可以得到每个批次内的那个RDD
作用:流的算子不够丰富, 没有RDD多. 可以通过这个方法, 得到RDD,然后操作RDD
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author jaffe
* @Date 2020/05/18 10:12
*/
object TramsformDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("TramsformDemo")
val ssc = new StreamingContext(conf, Seconds(3))
val lineStream = ssc.socketTextStream("hadoop103", 9999)
// 把对流的操作, 转换成对RDD操作.
val result = lineStream.transform(rdd => {
rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
})
result.print
ssc.start()
ssc.awaitTermination()
}
}
3.2 有状态的转换
保留上一批次的状态接着新批次计算
- 需要
checkPoint updateStateByKey((seq, opt) => )- 窗口操作
reduceByKeyAndWindow...- 直接给流加窗口
.window(, )
3.2.1 updateStateByKey操作案例
updateStateByKey作用:用来替换无状态的聚合函数.
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author jaffe
* @Date 2020/05/18 10:50
*/
object StateDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("StateDemo")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("./ck2")
val lineStream = ssc.socketTextStream("hadoop103", 9999)
// 把对流的操作, 转换成对RDD操作.
val result = lineStream
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.updateStateByKey((Seq: Seq[Int], opt: Option[Int]) => {
Some(Seq.sum + opt.getOrElse(0))
})
result.print
ssc.start()
ssc.awaitTermination()
}
}
3.2.2 window 操作案例
窗口操作需要 2 个参数:
1.窗口长度 – 窗口的持久时间(执行一次持续多少个时间单位)
2.滑动步长 – 窗口操作被执行的间隔(每多少个时间单位执行一次)
案例1:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author jaffe
* @Date 2020/05/18 17:12
*/
object WindowDemo1 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WindowDemo1")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("./ck2")
val lineStream = ssc.socketTextStream("hadoop103", 9999)
// 把对流的操作, 转换成对RDD操作.
val result = lineStream.flatMap(_.split(" "))
.map((_, 1))
// 窗口长度是: 9 滑动步长: 6(没有设置slideDuration参数就是默认步长3,默认和批次时间一样)
//.reduceByKeyAndWindow(_ + _, Seconds(9), slideDuration = Seconds(6))
// now是新进入的批次的聚合结果, pre离开的批次的聚合结果
.reduceByKeyAndWindow(_ + _, (now, pre) => now - pre, Seconds(9), filterFunc = _._2 > 0)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
案例2:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author jaffe
* @Date 2020/05/18 17:46
*/
object WindowDemo2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WindowDemo2")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("./ck2")
// 直接给DStream分配窗口, 将来所有的操作, 都是基于窗口
val lineStream = ssc.socketTextStream("hadoop103", 9999)
.window(Seconds(9))
// 把对流的操作, 转换成对RDD操作.
val result = lineStream
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
4.DStream 输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作 (例如把结果推入外部数据库或输出到屏幕上)。
与RDD中的惰性求值类似,如果一个DStream及其派生出的DStream都没有被执行输出操作,那么这些DStream就都不会被求值。如果StreamingContext中没有设定输出操作,整个context就都不会启动。
注意:
1.连接不能写在driver层面(序列化);
2.如果写在foreach则每个RDD中的每一条数据都创建,得不偿失;
增加foreachPartition,在分区创建(获取)
4.1 案例1:saveAsTextFiles
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author jaffe
* @Date 2020/05/18 13:58
*/
object OutputDemo1 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("OutputDemo1")
val ssc = new StreamingContext(conf, Seconds(3))
val lineStream = ssc.socketTextStream("hadoop103", 9999)
lineStream.saveAsTextFiles("word", "log")
ssc.start()
ssc.awaitTermination()
}
}
4.2 案例2:写入到mysql
conn.prepareStatement(sql):需提前创建表
import java.sql.DriverManager
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.ReceiverInputDStream
/**
* @Author jaffe
* @Date 2020/05/18 19:25
*/
object ForeachRDDDemo1 {
val driver = "com.mysql.jdbc.Driver"
val url = "jdbc:mysql://hadoop103:3306/test"
val user = "root"
val pw = "123456"
val sql = "insert into word values(?, ?)"
/*
聚合的时候, 使用状态,
写的时候, 如果数据存在, 则去更新
*/
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("ForeachRDDDemo1")
val ssc = new StreamingContext(conf, Seconds(3))
val lineStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop103", 9999)
val wordCountStream = lineStream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
// 把wordCount数据写入到mysql中
wordCountStream.foreachRDD(rdd => {
// 也是把流的操作转换成操作RDD.
// 向外部存储写入数据
// 在驱动中
rdd.foreachPartition(it => {
// 建立到mysql的连接
Class.forName(driver)
val conn = DriverManager.getConnection(url, user, pw)
// 写数据
it.foreach {
case (word, count) =>
val ps = conn.prepareStatement(sql)
ps.setString(1, word)
ps.setInt(2, count)
ps.execute()
// 关闭连接
ps.close()
}
// 关闭连接
conn.close()
})
})
ssc.start()
ssc.awaitTermination()
}
}
/*
transform: 转换算子
foreachRDD: 行动
*/
4.3 案例3:rdd转df写入到mysql
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Author jaffe
* @Date 2020/05/18 19:25
*/
object ForeachRDDDemo2 {
val driver = "com.mysql.jdbc.Driver"
val url = "jdbc:mysql://hadoop103:3306/test"
val user = "root"
val pw = "123456"
/*
聚合的时候, 使用状态,
写的时候, 如果数据存在, 则去更新
*/
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("ForeachRDDDemo2")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("./ck3")
val lineStream = ssc.socketTextStream("hadoop103", 9999)
val wordCountStream = lineStream.flatMap(_.split(" "))
.map((_, 1))
.updateStateByKey((seq: Seq[Int], opt: Option[Int]) => {
Some(seq.sum + opt.getOrElse(0))
})
// 把wordCount数据写入到mysql中
val spark = SparkSession.builder()
.config(ssc.sparkContext.getConf)
.getOrCreate()
import spark.implicits._
wordCountStream.foreachRDD(rdd => {
// 使用spark-sql来写
// 1. 先创建sparkSession
// 2. 把rdd转成df
val df = rdd.toDF("word", "count")
df.write.mode("overwrite").format("jdbc")
.option("url", url)
.option("user", user)
.option("password", pw)
.option("dbtable", "word")
.save()
})
ssc.start()
ssc.awaitTermination()
}
}
4.4 persist()方法
在DStream 上使用 persist()方法将会自动把DStreams中的每个RDD保存在内存中。
5.Spark Streaming 项目实战
5.1 准备数据
本实战项目使用 Structured Streaming 来实时的分析处理用户对广告点击的行为数据
5.1.1 数据生成方式
使用代码的方式持续的生成数据, 然后写入到 kafka 中.
然后Structured Streaming 负责从 kafka 消费数据, 并对数据根据需求进行分析.
5.1.2 数据生成模块
模拟出来的数据格式:
时间戳,地区,城市,用户 id,广告 id
1566035129449,华南,深圳,101,2
-
步骤1: 开启集群
启动 zookeeper 和 Kafka -
步骤2: 创建 Topic
在 kafka 中创建topic: ads_log -
步骤3: 产生循环不断的数据到指定的 topic
创建模块spark-realtime模块 -
步骤 4: 确认 kafka 中数据是否生成成功
5.2 编写代码生成模拟数据
5.2.1 工具类: RandomNumUtil
用于生成随机数
import java.util.Random
import scala.collection.mutable
/**
* @Author jaffe
* @Date 2020/05/18 23:42
*/
//随机生成整数的工具类
object RandomNumUtil {
val random = new Random()
/**
* 返回一个随机的整数 [from, to]
*
* @param from
* @param to
* @return
*/
def randomInt(from: Int, to: Int): Int = {
if (from > to) throw new IllegalArgumentException(s"from = $from 应该小于 to = $to")
// [0, to - from) + from [form, to -from + from ]
random.nextInt(to - from + 1) + from
}
/**
* 随机的Long [from, to]
*
* @param from
* @param to
* @return
*/
def randomLong(from: Long, to: Long): Long = {
if (from > to) throw new IllegalArgumentException(s"from = $from 应该小于 to = $to")
random.nextLong().abs % (to - from + 1) + from
}
/**
* 生成一系列的随机值
*
* @param from
* @param to
* @param count
* @param canRepeat 是否允许随机数重复
*/
def randomMultiInt(from: Int, to: Int, count: Int, canRepeat: Boolean = true): List[Int] = {
if (canRepeat) {
(1 to count).map(_ => randomInt(from, to)).toList
} else {
val set: mutable.Set[Int] = mutable.Set[Int]()
while (set.size < count) {
set += randomInt(from, to)
}
set.toList
}
}
}
5.2.2 工具类: RandomOptions
用于生成带有比重的随机选项
import scala.collection.mutable.ListBuffer
/**
* @Author jaffe
* @Date 2020/05/18 23:43
*/
/**
* 根据提供的值和比重, 来创建RandomOptions对象.
* 然后可以通过getRandomOption来获取一个随机的预定义的值
*/
object RandomOptions {
def apply[T](opts: (T, Int)*): RandomOptions[T] = {
val randomOptions = new RandomOptions[T]()
randomOptions.totalWeight = (0 /: opts) (_ + _._2) // 计算出来总的比重
opts.foreach {
case (value, weight) => randomOptions.options ++= (1 to weight).map(_ => value)
}
randomOptions
}
def main(args: Array[String]): Unit = {
// 测试
val opts = RandomOptions(("张三", 10), ("李四", 30), ("ww", 20))
println(opts.getRandomOption())
println(opts.getRandomOption())
println(opts.getRandomOption())
println(opts.getRandomOption())
println(opts.getRandomOption())
println(opts.getRandomOption())
println(opts.getRandomOption())
}
}
// 工程师 10 程序猿 10 老师 20
class RandomOptions[T] {
var totalWeight: Int = _
var options = ListBuffer[T]()
/**
* 获取随机的 Option 的值
*
* @return
*/
def getRandomOption() = {
options(RandomNumUtil.randomInt(0, totalWeight - 1))
}
}
5.2.3 样例类: CityInfo
/**
* @Author jaffe
* @Date 2020/05/18 23:42
*/
/**
* 城市表
*
* @param city_id 城市 id
* @param city_name 城市名
* @param area 城市区域
*/
case class CityInfo(city_id: Long,
city_name: String,
area: String)
5.2.4 生成模拟数据: MockRealTime
import java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import scala.collection.mutable.ArrayBuffer
/**
* @Author jaffe
* @Date 2020/05/18 23:43
*/
/**
* 生成实时的模拟数据
*/
object MockRealtime {
/*
数据格式:
timestamp area city userid adid
某个时间点 某个地区 某个城市 某个用户 某个广告
*/
def mockRealTimeData(): ArrayBuffer[String] = {
// 存储模拟的实时数据
val array = ArrayBuffer[String]()
// 城市信息
val randomOpts = RandomOptions(
(CityInfo(1, "北京", "华北"), 30),
(CityInfo(2, "上海", "华东"), 30),
(CityInfo(3, "广州", "华南"), 10),
(CityInfo(4, "深圳", "华南"), 20),
(CityInfo(5, "杭州", "华中"), 10))
// 生产50条记录
(1 to 50).foreach {
i => {
val timestamp = System.currentTimeMillis()
val cityInfo = randomOpts.getRandomOption()
val area = cityInfo.area
val city = cityInfo.city_name
val userid = RandomNumUtil.randomInt(101, 105)
val adid = RandomNumUtil.randomInt(1, 5)
// 1566035129449,华南,深圳,101,2
array += s"$timestamp,$area,$city,$userid,$adid"
Thread.sleep(10)
}
}
array
}
def createKafkaProducer: KafkaProducer[String, String] = {
val props: Properties = new Properties
// Kafka服务端的主机名和端口号
props.put("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092")
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
new KafkaProducer[String, String](props)
}
def main(args: Array[String]): Unit = {
val topic = "ads_log1128"
val producer: KafkaProducer[String, String] = createKafkaProducer
while (true) {
mockRealTimeData().foreach {
msg => {
// 发送到kafka
println(msg)
producer.send(new ProducerRecord(topic, msg))
Thread.sleep(100)
}
}
Thread.sleep(1000)
}
}
}
5.3 从Kafka 读取数据
编写RealTimeApp, 从 kafka 读取数据
5.3.1 bean 类 AdsInfo
用来封装从 Kafka 读取到广告点击信息
import java.text.SimpleDateFormat
import java.util.Date
/**
* @Author jaffe
* @Date 2020/05/19 00:33
*/
// 1589787737517,华南,深圳,104,4
case class AdsInfo(ts: Long,
area: String,
city: String,
userId: String,
adsId: String,
var dayString: String = null, // 2019-12-18
var hmString: String = null) { // 11:20
val date = new Date(ts)
dayString = new SimpleDateFormat("yyyy-MM-dd").format(date)
hmString = new SimpleDateFormat("HH:mm").format(date)
}
5.3.2 工具类 MyKafkaUtil
import kafka.serializer.StringDecoder
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.kafka.KafkaUtils
/**
* @Author jaffe
* @Date 2020/05/19 00:33
*/
object MyKafkaUtil {
val params = Map[String, String](
"bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
"group.id" -> "jaffe"
)
def getKafkaStream(ssc: StreamingContext, topic: String, otherTopics: String*) = {
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc,
params,
(otherTopics :+ topic).toSet
).map(_._2)
}
}
5.4 需求1:每天每地区热门广告 Top3
5.4.1 封装常用代码到特质APP
import com.jaffe.spark.streaming.project.bean.AdsInfo
import com.jaffe.spark.streaming.project.util.MyKafkaUtil
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Author jaffe
* Date 2020/5/19 9:11
*/
trait App {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("AreaAdsTopApp")
val ssc: StreamingContext = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("./ck1")
val adsInfoStream = MyKafkaUtil
.getKafkaStream(ssc, "ads_log1128")
.map(log => {
val splits: Array[String] = log.split(",")
AdsInfo(splits(0).toLong, splits(1), splits(2), splits(3), splits(4))
})
//不同的业务处理方法不一样
doSomething(ssc, adsInfoStream)
ssc.start()
ssc.awaitTermination()
}
def doSomething(ssc: StreamingContext, stream: DStream[AdsInfo]):Unit
}
5.4.2 编写AreaAdsTopApp类实现需求
import com.jaffe.spark.streaming.project.bean.AdsInfo
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author jaffe
* @Date 2020/05/19 00:32
*/
object AreaAdsTopApp extends App {
// 需求分析:
/*
DStream[(day, area, ads), 1] updateStateByKey
DStream[(day, area, ads), count]
分组, top 3
DStream[(day, area), (ads, count)]
DStream[(day, area), it[(ads, count)]]
排序取30
*/
override def doSomething(ssc: StreamingContext, adsInfoStream: DStream[AdsInfo]): Unit = {
adsInfoStream
.map(info => ((info.dayString, info.area, info.adsId), 1))
.updateStateByKey((seq: Seq[Int], opt: Option[Int]) => {
Some(seq.sum + opt.getOrElse(0))
})
.map {
case ((day, area, ads), count) =>
((day, area), (ads, count))
}
.groupByKey()
.mapValues(it => {
it.toList.sortBy(-_._2).take(3)
})
.print
}
}
/*
每天每地区热门广告 Top3
DStream[(day, area, ads), 1] updateStateByKey
DStream[(day, area, ads), count]
分组, top 3
DStream[(day, area), (ads, count)]
DStream[(day, area), it[(ads, count)]]
排序取30
*/
5.5 需求2:最近 1 小时广告点击量实时统计
统计各广告最近 1 小时内的点击量趋势:各广告最近 1 小时内各分钟的点击量
import java.sql.DriverManager
import com.jaffe.spark.streaming.project.bean.AdsInfo
import org.apache.spark.streaming.{Minutes, Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
import org.json4s.jackson.Serialization
/**
* @Author jaffe
* @Date 2020/05/19 11:08
*/
object LastHourApp extends App {
val driver = "com.mysql.jdbc.Driver"
val url = "jdbc:mysql://hadoop103:3306/test"
val user = "root"
val pw = "123456"
override def doSomething(ssc: StreamingContext, adsInfoStream: DStream[AdsInfo]): Unit = {
// 只完成具体的业务
adsInfoStream
.window(Minutes(60), Seconds(6)) // 以后所有的操作都是基于窗口的
.map(info => ((info.adsId, info.hmString), 1))
.reduceByKey(_ + _)
.map {
case ((ads, hm), count) => (ads, (hm, count))
}
// 把每个广告的每分钟点击量放在一起
.groupByKey()
.foreachRDD(rdd => {
// 如果主键(广告id)存在就更新, 不存在就插入
val sql = "insert into word values(?,?) on duplicate key update hm_count=?"
rdd.foreachPartition((it: Iterator[(String, Iterable[(String, Int)])]) => {
// 每个广告写一行
// adsId 作为主键 保证不重复 1
//hmCount 存储分钟点击量的json字符串 '{"09:25": 75, "09:26": 86, "09:27": 76}'
Class.forName(driver)
val conn = DriverManager.getConnection(url, user, pw)
it.foreach {
case (adsId, it) =>
// 1. 先把Iterable转成json字符串 json4s(json for scala)
import org.json4s.DefaultFormats
val hmCountString = Serialization.write(it.toMap)(DefaultFormats)
val ps = conn.prepareStatement(sql)
ps.setInt(1, adsId.toInt)
ps.setString(2, hmCountString)
ps.setString(3, hmCountString)
ps.execute()
ps.close()
}
conn.close()
})
})
}
}
如何保证数据不丢失,手动维护offset,保存在Mysql
1)创建ssc, StreamingContext
2)kafka配置
3)查询Mysql中的offset
4)创建数据流,Direct
5)清洗,转换,处理
6)手动保存offset到mysql中
7)启动ssc