数仓案例
1.业务场景
业务场景我们使用数仓的经典的销售订单源系统,业务逻辑很简单,有两个基本信息表产品表和客户表,产品表记录产品名称、编号和分类,客户表记录客户编号,客户名称以及其他基本信息,一个业务表订单表,记录哪个客户购买了什么产品,以及花费多少。
2.多维数据模型及建模过程
维度模型通常以一种被称为星型模式的方式构建,一般使用下面的过程构建维度模型:
选择业务流程
声明粒度
确认维度
确认事实
2.1.选择业务流程
确认哪些业务处理流程是数据仓库应该覆盖的,是维度方法的基础。因此,建模的第一个步骤是描述需要建模的业务流程。例如,需要了解和分析一个零售店的销售情况,那么与该零售店销售相关的所有业务流程都是需要关注的。为了描述业务流程,可以简单地使用纯文本将相关内容记录下来,或者使用“业务流程建模标
注”(BPMN)方法,也可以使用统一建模语言(UML)或其他类似的方法。
2.2.声明粒度
确定了业务流程后,下一步是声明维度模型的粒度。这里的粒度用于确定事实中表示的是什么,例如,一个零售店的顾客在购物小票上的一个购买条目。在选择维度和事实前必须声明粒度,因为每个候选维度或事实必须与定义的粒度保持一致。在一个事实所对应的所有维度设计中强制实行粒度一致性是保证数据仓库应用性能和易用性的关键。从给定的业务流程获取数据时,原始粒度是最低级别的粒度。建议从原始粒度数据开始设计,因为原始记录能够满足无法预期的用户查询。汇总后的数据粒度对优化查询性能很重要,但这样的粒度往往不能满足对细节数据的查询需求。不同的事实可以有不同的粒度,但同一事实中不要混用多种不同的粒度。维度模型建立完成之后,还有可能因为获取了新的信息,而回到这步修改粒度级别。
2.3.确认维度
设计过程的第三步是确认模型的维度。维度的粒度必须和第二步所声明的粒度一致。维度表是事实表的基础,也说明了事实表的数据是从哪里采集来的。典型的维度都是名词,如日期、商店、库存等。维度表存储了某一维度的所有相关数据,例如,日期维度应该包括年、季度、月、周、日等数据。
2.4.确认事实
确认维度后,下一步也是维度模型四步设计法的最后一步,就是确认事实。这一步识别数字化的度量,构成事实表的记录。它是和系统的业务用户密切相关的,因为用户正是通过对事实表的访问获取数据仓库存储的数据。大部分事实表的度量都是数字类型的,可累加,可计算,如成本、数量、金额等。
3.Data Vault模型及建模过程
Data Vault是面向细节的,可追踪历史的,一组有连接关系的规范化的表的集合。这些表可以支持一个或多个业务功能。它是一种综合了第三范式(3NF)和星型模型
优点的建模方法。其设计理念是要满足企业对灵活性、可扩展性、一致性和对需求的适应性要求,是一种专为企业级数据仓库量身定制的建模方式。它的建模步骤如下:
3.1.设计中心表
首先要确定企业数据仓库要涵盖的业务范围;其次要将业务范围划分为若干原子业务实体,比如客户、产品等;然后,从各个业务实体中抽象出能够唯一标识该实体的业务主键,该业务主键要在整个业务的生命周期内不会发生变化;最后,由该业务主键生成中心表。
3.2.设计链接表
链接表体现了中心表之间的业务关联。设计链接表,首先要熟悉各个中心表代表的业务实体之间的业务关系,可能是两个或者多个中心表之间的关系。根据业务需求,这种关系可以是1对1、1对多,或者多对多的。然后,从相互之间有业务关系的中心表中,提取出代表各自业务实体的中心表主键,这些主键将被加入到链接表中,组合构成该链接表的主键。同样出于技术的原因,需要增加代理键。
在生成链接表的同时,要注意如果中心表之间有业务交易数据的话,就需要在链接表中保存交易数据,有两种方法,一是采用加权链接表,二是给链接表加上附属表来处理交易数据。
3.3.设计附属表
附属表包含了各个业务实体与业务关联的详细的上下文描述信息。设计附属表,首先要收集各个业务实体在提取业务主键后的其他信息,比如客户住址、产品价格等;由于同一业务实体的各个描述信息不具有稳定性,会经常发生变化,所以,在必要的时候,需要将变化频率不同的信息分隔开来,为一个中心表建立几个附属表,然后提取出该中心表的主键,作为描述该中心表的附属表的主键。当业务实体之间存在交易数据的时候,需要为没有加权的链接表设计附属表,也可以根据交易数据的不同变化情况设计多个附属表。
3. 4.设计必要的PIT表
Point—In—Time表是由附属表派生而来的。如果一个中心表或者链接表设计有多个附属表的话,而为了访问数据方便,就有用到PIT表的可能。PIT表的主键也是由其所归属的中心表提取而来,该中心表有几个附属表,PIT表就至少应该有几个字段来存放各个附属表的变化对比时间。
建立Data Vault模型时应该参照如下的原则:
(1)关于中心表的原则
中心表的主键不能够直接“伸入”到其他中心表里面。就是说,不存在父子关系的中心表。各个中心表之间的关系是平等的,这也正是Data Vault模型灵活性与扩展性
之所在。
中心表之间必须通过链接表相关联,通过链接表可以连接两个以上的中心表。
必须至少有两个中心表才能产生一个有意义的链接表。
中心表的主键总是“伸出去”的(到链接表或者附属表)。
(2)关于链接表的原则
链接表可以跟其他链接表相连。
中心表和链接表都可以使用代理键。
业务主键从来不会改变,就是说中心表的主键也即链接表的外键不会改变。
(3)关于附属表的原则
附属表必须是连接到中心表或者链接表上才会有确定的含义。
附属表总是包含装载时间和失效时间,从而包含历史数据,并且没有重复的数据。
由于数据信息的类型或者变化频率快慢的差别,描述信息的数据可能会被分隔到多个附属表中去。
4. 部署实施
4.1 准备环境
4.2 业务库
源系统是mysql库,数据模型如下

建表语句如下:
注:为了生成数据,我们可以写一个脚本来执行:createdb_source.sql
/*==============================================================*/
/* DBMS name: MySQL 5.0 */
/* Created on: 2019/12/05 19:09:10 */
/*==============================================================*/
CREATE DATABASE IF NOT EXISTS sales_source DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
USE sales_source;
DROP TABLE IF EXISTS customer;
DROP TABLE IF EXISTS product;
DROP TABLE IF EXISTS sales_order;
/*==============================================================*/
/* Table: customer */
/*==============================================================*/
CREATE TABLE customer
(
customer_number INT(11) NOT NULL AUTO_INCREMENT,
customer_name VARCHAR(128) NOT NULL,
customer_street_address VARCHAR(256) NOT NULL,
customer_zip_code INT(11) NOT NULL,
customer_city VARCHAR(32) NOT NULL,
customer_state VARCHAR(32) NOT NULL,
PRIMARY KEY (customer_number)
);
/*==============================================================*/
/* Table: product */
/*==============================================================*/
CREATE TABLE product
(
product_code INT(11) NOT NULL AUTO_INCREMENT,
product_name VARCHAR(128) NOT NULL,
product_category VARCHAR(256) NOT NULL,
PRIMARY KEY (product_code)
);
/*==============================================================*/
/* Table: sales_order */
/*==============================================================*/
CREATE TABLE sales_order
(
order_number INT(11) NOT NULL AUTO_INCREMENT,
customer_number INT(11) NOT NULL,
product_code INT(11) NOT NULL,
order_date DATETIME NOT NULL,
entry_date DATETIME NOT NULL,
order_amount DECIMAL(18,2) NOT NULL,
PRIMARY KEY (order_number)
);
/*==============================================================*/
/* insert data */
/*==============================================================*/
INSERT INTO customer
( customer_name
, customer_street_address
, customer_zip_code
, customer_city
, customer_state
)
VALUES
('Big Customers', '7500 Louise Dr.', '17050',
'Mechanicsburg', 'PA')
, ( 'Small Stores', '2500 Woodland St.', '17055',
'Pittsburgh', 'PA')
, ('Medium Retailers', '1111 Ritter Rd.', '17055',
'Pittsburgh', 'PA'
)
, ('Good Companies', '9500 Scott St.', '17050',
'Mechanicsburg', 'PA')
, ('Wonderful Shops', '3333 Rossmoyne Rd.', '17050',
'Mechanicsburg', 'PA')
, ('Loyal Clients', '7070 Ritter Rd.', '17055',
'Pittsburgh', 'PA')
INSERT INTO product(product_name,product_category) VALUES
('Hard Disk','Storage'),
('Floppy Drive','Storage'),
('lcd panel','monitor')
DROP PROCEDURE IF EXISTS usp_generate_order_data;
DELIMITER //
CREATE PROCEDURE usp_generate_order_data()
BEGIN
DROP TABLE IF EXISTS tmp_sales_order;
CREATE TABLE tmp_sales_order AS SELECT * FROM sales_order WHERE 1=0;
SET @start_date := UNIX_TIMESTAMP('2018-1-1');
SET @end_date := UNIX_TIMESTAMP('2018-11-23');
SET @i := 1;
WHILE @i<=100000 DO
SET @customer_number := FLOOR(1+RAND()*6);
SET @product_code := FLOOR(1+RAND()* 3);
SET @order_date := FROM_UNIXTIME(@start_date+RAND()*(@end_date-@start_date));
SET @amount := FLOOR(1000+RAND()*9000);
INSERT INTO tmp_sales_order VALUES (@i,@customer_number,@product_code,@order_date,@order_date,@amount);
SET @i := @i +1;
END WHILE;
TRUNCATE TABLE sales_order;
INSERT INTO sales_order
SELECT NULL,customer_number,product_code,order_date,entry_date,order_amount
FROM tmp_sales_order;
COMMIT;
DROP TABLE tmp_sales_order;
END //
CALL usp_generate_order_data();
查看一下生成的数据:
数据没问题,可以进行下一步。
4.3 数据仓库
数仓是建立在hive上,有两层(ODS层rds库)和DW层(tds库),存储格式日期维度textfile,其他orc。
4.4 模型搭建
星型模式是维度模型最简单的形式,也是比较常用的模型,我们的案例采用星型模型。所谓星型模型就是以一个事实表为中心,周围围绕多个维度表。对维度表做进一步规范化后形成的模型叫雪花模型,含有很多维度表的星型模型有时被称为蜈蚣模型,蜈蚣模型的维表往往只有很少的几个属性,这样可以简化维度表的维护,但同时查询数据的时候会有很多的表连接,严重时会使模型难以使用,因此要尽量避免这种模型。
星型模型将业务分为事实和维度。
事实是业务数据的度量值,比如销售额、销售数量等,它记录了特定事件的量化指标,一般是度量值和指向维表的外键组成。事实表的粒度级别通常会设计的比较低,事实表有三种类型:
事务事实表:最低粒度级别的事实表,记录原始的操作型事件.
快照事实表:记录给定时间点的事实,如月底账户余额
累积事实表:记录给定事件点的聚合事实,如当月的销售金额.
维度是对事实数据属性的描述,如日期,省份,地区等,维度表的数据量通常不大,常用的维度表有:
时间维度表,每个数据仓库都需要一个时间维度表。
地理维度表:描述位置信息的数据,如国家,省份,城市,区县,邮编等
产品维度表:描述产品及其属性
人员维度表:描述人员相关信息,部门员工表等
范围维度表:描述分段数据的信息等,比如信用等级
代理键:一般事实表和维表都有主键,单仍会设置一个代理键,所谓代理键说白了及时业务无关的自增主键,因为维表的主键有可能会产生变化,即变化维.
星型模型是非规范化的,不受关系数据库的范式规则的约束,当所有的维度进行规范化后也叫做”雪花化”,就是雪花模型了,具体的做法是将低基数(维表中的行数少,比如性别)的属性从维度表中移除并形成单独的维表,维表就具有了层次关系(父子),减少了维表数据的冗余,因此大数据量下雪花比星型节省空间,但是相对的查询要关联的表多,因此也就变的复杂.有些设计底层使用雪花模型,上层用表连接简历视图模拟星型模型,这种方式通过对维度的规范化节省了空间,同时又对用户屏蔽了查询的复杂性,但是视图对于查询效率的提升相对于联合查询来说并没有得到提升,对开发效率有提升,性能有损失.
1.选择业务流程
维度方法的基础是首先确认哪些业务处理流程是数据库需要覆盖的,因此建模的第一个步骤是描述需要建模的业务流程,描述业务流程,可以简单的使用文本记录下俩或者使用MPMN(业务流程建模标注)的方法,也可以使用UML等.
我们的案例业务很明确就是:销售订单
2.粒度,
粒度用于确定事实表中表示的是什么,在选择
事实表存储最细粒度的事务记录,每小时更新增量,凌晨2两点更新昨天全量
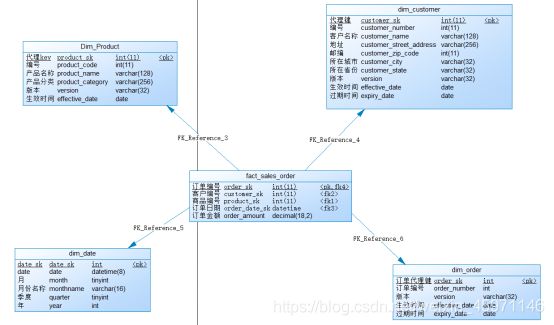
3.确认维度:
产品、客户以及日期,日期维度用于业务集成,每个数据仓库都应该有一个日期维度,日期维度数据一旦生成就不会改变,因此不需要版本号、生效日期和过期日期,一般情况下直接生成10年或者20年的数据,初始化的数据远高于数据仓库的有效时长即可。
在有变化的维度表上增加版本号、生效日期、过期日期,能看到维度的历史变化,当维度属性发生变化的时候,根据不同的策略,生成一条新的维度记录或者更改原记录。渐变维 slow changing dimensions SCD
代理键是维度表的主键,一般加sk表示即surrogate key,是每行记录的唯一标识,由系统生成的主键,不是应用数据,没有业务含义.
4.确认事实:
订单是唯一事实,订单金额是唯一度量,按天分区。
5.建立物理模型
5 建库、装载数据
5.1 创建ods层
5.1.1 创建ods层表
- sales_order
CREATE DATABASE IF NOT EXISTS `sales_ods`;
USE `sales_ods`;
DROP TABLE IF EXISTS `sales_order`;
CREATE TABLE IF NOT EXISTS `sales_order` (
`order_number` int,
`customer_number` int,
`product_code` int,
`order_date` timestamp,
`entry_date` timestamp,
`order_amount` decimal(18,2)
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
;
- customer
DROP TABLE IF EXISTS `customer`;
CREATE TABLE `customer` (
`customer_number` int,
`customer_name` string,
`customer_street_address` string,
`customer_zip_code` int,
`customer_city` string,
`customer_state` string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
;
- product
DROP TABLE IF EXISTS `product`;
CREATE TABLE `product` (
`product_code` int,
`product_name` string,
`product_category` string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
;
5.1.2 数据迁移
- 全量导入数据
sqoop import \
--connect jdbc:mysql://192.168.49.101:3306/sales_source \
--username root \
--password 123456 \
--table customer \
--hive-overwrite \
--hive-import \
--hive-table sales_ods.customer \
--m 1 \
--split-by id \
;
sqoop import \
--connect jdbc:mysql://192.168.49.101:3306/sales_source \
--username root \
--password 123456 \
--table product \
--hive-overwrite \
--hive-import \
--hive-table sales_ods.product \
--m 1 \
--split-by id \
;
sqoop import \
--connect jdbc:mysql://192.168.49.101:3306/sales_source \
--username root \
--password 123456 \
--table sales_order \
--hive-overwrite \
--hive-import \
--hive-table sales_ods.sales_order \
--m 1 \
--split-by id \
;
tip:
java.lang.ClassNotFoundException:json.NSJSONObject
说明缺少了json-2009.jar包,将它拷贝到sqoop的lib目录中
java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
tip:
这个问题式因为我们sqoop所在的服务器没有hive的库,所以找不到hive的类的资源,导入hive-common-xxxx.jar
java.lang.NoClassDefFoundError: org/apache/hadoop/hive/shims/ShimLoader
tip:
导入:hive-exec-1.1.0-cdh5.5.6.jar
- 增量导入
1. 增量导入方式1:
sqoop import \
--connect jdbc:mysql://192.168.49.101:3306/sales_source \
--username root \
--password 123456 \
--table sales_order \
--hive-database sales_ods \
--hive-import \
--hive-table sales_order \
--where "order_number>132070" \
--split-by order_number \
--num-mappers 2
5.1.3 sqoop job
--create 创建sqoop的作业
--delete 删除sqoop的作业
--exec 运行sqoop的作业
--list 查询所有的sqoop中已经保存了的作业
--show 查询指定作业的详情
- 使用job进行增量导入
1. 创建sqoop的job
sqoop job --create incremental_sales_order -- import \
--connect jdbc:mysql://192.168.49.101:3306/sales_source \
--username root \
--password 123456 \
--table sales_order \
--hive-database sales_ods \
--hive-import \
--hive-table sales_order \
--where "order_number>132070" \
--split-by order_number \
--num-mappers 2
2. 查询所有的sqoop中的job
sqoop job --list
3. 运行sqoop的job
sqoop job --exec incremental_sales_order
5.2 构建dw层
5.2.1 创建维度表
- dim_product
CREATE DATABASE IF NOT EXISTS sales_dim;
USE `sales_dim`;
DROP TABLE IF EXISTS `sales_dim.dim_product`;
CREATE TABLE IF NOT EXISTS `sales_dim.dim_product` (
`product_sk` int,
`product_code` int,
`product_name` string,
`product_category` string,
`version` int,
`effective_date` timestamp,
`expire_date` timestamp
)
CLUSTERED BY (product_sk) INTO 8 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
STORED AS ORC TBLPROPERTIES("transactional"="true")
;
- dim_customer
DROP TABLE IF EXISTS `sales_dim.dim_customer`;
CREATE TABLE IF NOT EXISTS `dim_customer` (
`customer_sk` int,
`customer_number` int,
`customer_name` string,
`customer_street_address` string,
`customer_zip_code` int,
`customer_city` string,
`customer_state` string,
`version` int,
`effective_date` timestamp,
`expire_date` timestamp
)
CLUSTERED BY (customer_sk) INTO 8 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
STORED AS ORC TBLPROPERTIES("transactional"="true")
;
- dim_date
DROP TABLE IF EXISTS `sales_dim.dim_date`;
CREATE TABLE IF NOT EXISTS `dim_date` (
`date_sk` int,
`date` string,
`month` tinyint,
`monthname` string,
`quarter` tinyint,
`year` int
)
CLUSTERED BY (date_sk) INTO 8 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
;
- dim_order
DROP TABLE IF EXISTS `dim_order`;
CREATE TABLE IF NOT EXISTS `dim_order` (
`order_sk` int,
`order_number` int,
`version` int,
`effective_date` timestamp,
`expire_date` timestamp
)
CLUSTERED BY (order_sk) INTO 8 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
STORED AS ORC TBLPROPERTIES("transactional"="true")
;
5.2.2 导入维度数据
- dim_product
from (
select
row_number() over(order by product_code),
product_code,
product_name,
product_category,
1,
timestamp(date('2019-12-04','yyyy-MM-dd')),
timestamp(date('9999-12-04','yyyy-MM-dd'))
from
sales_ods.product
) tmp
insert into sales_dim.dim_product
select *
;
- dim_customer
from (
select
row_number() over(order by order_number),
order_number,
1,
timestamp(date('2019-12-04','yyyy-MM-dd')),
timestamp(date('9999-12-04','yyyy-MM-dd'))
from
sales_ods.sales_order
) tmp
insert into sales_dim.dim_order
select *
;
- dim_order
from (
select
row_number() over(order by customer_number),
customer_number,
customer_name,
customer_street_address,
customer_zip_code,
customer_city,
customer_state,
1,
timestamp(date('2019-12-04','yyyy-MM-dd')),
timestamp(date('9999-12-04','yyyy-MM-dd'))
from
sales_ods.customer
) tmp
insert into sales_dim.dim_customer
select *
;
- dim_date
1. 运行init_dim_date.sh
#!/bin/bash
date1="$1"
date2="$2"
tempdate=`date -d "$date1" +%F`
tempdateSec=`date -d "$date2" +%s`
enddateSec=`date -d "$date2" +$s`
min=1
#max=`expr \( $enddateSec - $tempdateSec \) / \( 24 \* 60 \* 60 \) + 1`
max=14611
#cat /datas >./dim_date.csv
while [ $min -le $max ]
do
month=`date -d "$tempdate" +%m`
month_name=`date -d "$tempdate" +%B`
quarter=`echo $month | awk '{print int(($0-1)/3 +1) }'`
year=`date -d "$tempdate" +%Y`
echo ${min}","${tempdate}","${month}","${month_name}","${quarter}","${year} >> ./dim_date.csv
tempdate=`date -d "+$min day $date1" +%F`
tempdateSec=`date -d "+min day $date1" +%s`
min=`expr $min + 1`
done
2. dim_date.csv
load data local inpath '/home/dim_date.csv' into table dim_date;
5.3 创建事实表
CREATE DATABASE IF NOT EXISTS `sales_dw`;
USE `sales_dw`;
DROP TABLE IF EXISTS `fact_sales_order`;
CREATE TABLE IF NOT EXISTS `fact_sales_order` (
order_sk int,
customer_sk int,
product_sk int,
order_date_sk int,
order_amount decimal(18,2)
)
PARTITIONED By(year string, month string)
CLUSTERED BY (order_sk) INTO 8 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
STORED AS ORC TBLPROPERTIES("transactional"="true")
;
导入数据到事实表
set hive.exec.dynamic.partition.mode=strict;
from (
select
so.order_amount order_amount,
do.order_sk order_sk,
dc.customer_sk customer_sk,
dp.product_sk product_sk,
dd.date_sk order_date_sk,
dd.month month
from
sales_ods.sales_order so
left join
sales_dim.dim_order do
on
so.order_number = do.order_number
left join
sales_dim.dim_customer dc
on
so.customer_number = dc.customer_number
left join
sales_dim.dim_product dp
on
so.product_code = dp.product_code
left join
sales_dim.dim_date dd
on
from_unixtime(unix_timestamp(so.order_date), 'yyyy-MM-dd') = dd.date
) tmp
insert overwrite table sales_dw.fact_sales_order
PARTITION(year='2019', month)
select
order_sk,
customer_sk,
product_sk,
order_date_sk,
order_amount,
month
;
**tip:
静态分区:手动指定分区名
动态分区:自动的设置分区(非严格模式)**
5.4 构建dm层数据
某天、某客户、某产品、当天订单个数、当天订单金额、近两天订单个数、近两天订单金额
CREATE DATABASE IF NOT EXISTS `sales_dm`;
USE `sales_dm`;
DROP TABLE IF EXISTS `sales_order`;
CREATE TABLE IF NOT EXISTS `sales_order` (
date string,
customer_number int,
customer_name string,
product_code int,
product_name string,
one_order_cnt int,
one_order_amount decimal(18,2),
two_order_cnt int,
two_order_amount decimal(18,2)
)
PARTITIONED By(order_date string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
STORED AS TEXTFILE
;
from(
select
dd.date date,
dc.customer_number customer_number,
dc.customer_name customer_name,
dp.product_code product_code,
dp.product_name product_name,
sum(case when datediff('2019-12-05', current_date()) = 0 then 1 else 0 end) one_order_cnt,
sum(case when datediff('2019-12-05', current_date()) = 0 then fso.order_amount else 0 end) one_order_amount,
sum(case when datediff('2019-12-05', current_date()) in (-1, 0) then 1 else 0 end) two_order_cnt,
sum(case when datediff('2019-12-05', current_date()) in (-1, 0) then fso.order_amount else 0 end) two_order_amount
from
sales_dw.fact_sales_order fso
left join
sales_dim.dim_date dd
on
fso.order_date_sk = dd.date_sk
left join
sales_dim.dim_customer dc
on
fso.customer_sk = dc.customer_sk
left join
sales_dim.dim_product dp
on
fso.product_sk = dp.product_sk
group by
date,
customer_number,
customer_name,
product_code,
product_name
) tmp
insert overwrite table sales_order
PARTITION(order_date='2019-12-05')
select *
;
5.5 将dm层的数据迁移到mysql
5.5.1 必须现在mysql中建表
CREATE DATABASE IF NOT EXISTS `sales_order_cnt`;
USE sales_order_cnt;
CREATE TABLE IF NOT EXISTS `sales_order` (
date varchar(10),
customer_number int,
customer_name varchar(32),
product_code int,
product_name varchar(32),
one_order_cnt int,
one_order_amount decimal(18,2),
two_order_cnt int,
two_order_amount decimal(18,2)
)
;
5.5.2 sqoop进行增量导出
sqoop export \
--connect jdbc:mysql://192.168.49.101:3306/sales_order_cnt \
--username root \
--password 123456 \
--export-dir /home/apps/hive-1.1.0-cdh5.7.6/warehouse/sales_dm.db/sales_order/order_date=2019-12-05 \
--table sales_order \
--input-fields-terminated-by '\001' \
--update-key date \
--update-mode allowinsert \
--num-mappers 2
5.5.3 问题总结

WARN mapreduce.Counters: Group FileSystemCounters is deprecated. Use org.apache.hadoop.mapreduce.FileSystemCounter instead
**tip:
1. 第一个mysql数据库编码格式不是utf-8导致乱码
2. 第二原因hive建立dm层的表不是TEXTFILE**
**排错:去查看8088的yarn中的日志信息**