Linux基础(2)
Shell

Shell是系统的用户界面,提供了用户与内核进行交互操作的一种接口(命令解释器) 。
协调用户与系统的一致性和在用户与系统之间进行交互的作用。
它接收用户输入的命令并把它送入内核去执行。
命令执行过程
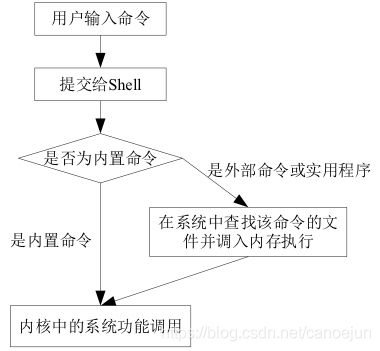
内置命令:出于效率的考虑,将一些常用命令的解释程序构造在Shell内部
外置命令:存放在/bin、/sbin目录下的命令
查找外置命令时的路径遵循:(1)用户给出的路径 (2)PATH环境变量给出的路径
利用 type 进行区分命令类型
元字符
具有特殊的意义字符,称为 Shell 元字符(shell metacharacters)。
若不以特殊方式(使用转义字符)指明,Shell并不会把它们当做普通文字符使用。

通配符
*:匹配任何字符和任何数目的字符
?:匹配单一数目的任何字符
[ ]:匹配[ ]之内的任意一个字符
[! ]:匹配除了[! ]之外的任意一个字符,!表示非的意思
“*”能匹配文件或目录名中的“.”。
“*”不能匹配首字符是“.”的文件或目录名。
ls *.c
列出当前目录下的所有C语言源文件。
ls /home/*/*.c
列出/home目录下所有子目录中的所有C语言源文件。
ls n*.conf
列出当前目录下的所有以字母n开始的conf文件。
ls test?.dat
列出当前目录下的以test开始的,随后一个字符是任意的.dat文件。
ls [abc]*
列出当前目录下的首字符是a或b或c的所有文件。
ls [\!abc]*
列出当前目录下的首字符不是a或b或c的所有文件。
ls [a-zA-Z]*
列出当前目录下的首字符是字母的所有文件
文件
红色:压缩文件
绿色:可执行文件
蓝色:目录
黑色:普通文件
浅蓝色文件:软连接文件(就是有->标识的文件)
黑色底显示橘色的:字符设备
黑色底显示黄色的:块设备
普通文件 ( - )
目录 ( d )
符号链接 ( l )
字符设备文件 ( c )
块设备文件 ( b )
套接字 ( s )
命名管道 ( p )
- 在Linux环境下,只要是可执行的文件并具有可执行属性它就能执行,不管其文件名后缀是什么。但是对一些数据文件一般也遵循一些文件名后缀规则。
- Linux 不会区别对待这些普通文件,只有处理这些文件的应用程序才会根据文件的内容赋予相应的含义。
- 从上面了解到普通文件占据了Linux系统中大多数,其中包含了各种类型:图片、压缩文件、shell脚本、python文件等等,Linux系统下的文件后缀名并不表明文件是否可执行,后缀用户标识应用程序类型,但是与可执行性无关,可执行与否取决于文件权限ugo
软硬链接
ln 源文件名 硬链文件名
ln -s 源文件名 软链接文件名
硬连接文件使不止一个dentry可以引用到同一个文件。这种链接关系由 ln 命令行来建立。
硬链接并不是一种特殊类型的文件,只是因为在文件系统中允许不止一个项指向同一个文件(不能建立指向文件夹的硬连接 链接和被链接文件须位于同一个文件系统内)
ls -al第二列是引用计数是dentry,表示硬连接数
链接文件和被链接文件可以位于不同文件系统 可以建立指向目录的软链接
ln [参数] <被链接的文件> <链接文件名>
-s : 创建符号链接,而非硬链接。
-f : 强行创建链接,不论其是否存在。
-i : 覆盖原有文件之前先询问用户。

设备文件
设备文件存放在/dev目录下
/dev/sd* SCSISAS、PATASATA、USB硬盘设备,如sda1表示第1块硬盘的第1个分区: sdb2 表示第2块硬盘的第2个分区
/dev/srO 光驱设备
/dev/console 系统控制台
/dev/tty* 本地终端设备
/dev/pts/* 伪终端设备
/dev/ppp* PPP设备。PPP (Point-to-Point) 协议设备,用于传统的拨号上网
/dev/lp* 表示并口设备,如lp0表示第1个并口设备; lpl 表示第2个并口设备
/dev/null 空设备。可将其视为“黑洞",所有写入它的内容都会丢失,通常用于屏蔽命令行输出
/dev/zero 零设备。可以产生连续不断的进制的零流,通常用于创建指定长度的空文件
man hier
/:文件系统结构的初始位置,称为根
/bin :存放基本命令程序(任何用户都可以调用)
/boot:存放系统启动时所读取的文件,包括系统核心文件
/dev:存放设备文件接口,如打印机,硬盘等外围设备
/etc:存放与系统设置和管理相关的文件,如账号密码等
。。。。。。
/home:存放用户专属目录(用户主目录)
/lib:共享等函数库文件和内核模块存放目录
/misc:空目录,供管理员存放公共杂物
/proc:存放系统核心和执行程序之间的信息,例如系统进程的实时信息
/opt:第三方软件的存放目录
/sbin:与/bin类似,存放用于系统引号和管理命令,通常供root使用
/tmp:临时目录,供任何用户存放临时文件
/media:媒体设备存放目录
/mnt:临时挂载目录。
/srv:系统对外提供的服务
/usr:包含许多子目录,存放系统命令和程序等信息
/bin
/sbin
/man
。。。。。。
/var:经常变动的文件,日志,临时文件,电子邮件等
ls 列表显示当前目录下的文件和目录
ls -a 列表显示当前目录下的文件和目录(包括隐含文件和目录)
ls -l 以长格式列表显示结果
ls -R 递归地显示当前目录及其子目录下的文件和目录
ls -dl /usr/share/ 仅显示/usr/share/目录本身,而非/usr/share/ 目录中的内容
ls -lt 按最后修改时间顺序,以长格式列出当前目录下的文件
mkdir -p /srv/www/{abc,bcd}/htdocs 创建/srv/www/abc/htdocs和/srv/www/bcd/htdocs目录
file/stat 查看文件类型或文件属性信息
# touch命令
touch (若文件不存在,系统会建立一个文件默认情况下将文件的时间记录改为当前间)
-a : 只更改访问时间。
-m : 只更改修改时间。
-t : 使用[[CC]YY]MMDDhhmm[.ss]格式的时间而非当前时间。
-r <参考文件或目录> : 使用指定文件的时间属性而非当前时间。
# 文件的时间戳
ls -lc filename 列出文件的 ctime (最后状态更改时间)
ls -lu filename 列出文件的 atime(最后访问时间)
ls -l filename 列出文件的 mtime (最后修改时间)
stat filename 一次性看到文件的三种时间属性
新创建一个文件touch file时ctime、atime、mtime是相同的;当用vi 向文件里写入信息后,肯定是先访问file 所以atime改变,文件内容改变了所有ctime和mtime也改变;当用chmod 命令时 ctime会改变。
cat、less、more等只访问文件,不修改文件的操作,只会修改atime的值。
chmod、chown修改文件权限、所有者,所属组的操作,会修改atime和ctime的值。
vi 等修改文件内容的操作,会修改atime、ctime、mtime的值。
# cp命令
-a 等价于 –dpR
-R,-r 递归地复制目录及目录内的所有项目
-p 在复制文件过程中保留文件属性,包括属主、组、权限与时间戳
-d 当复制符号链接的源文件时,目标文件也将创建符号链接且指向源文件所链接的原始文件
-f 强制复制,不管目标是否存在
-i 交互式复制,覆盖文件前需要确认
-u 只有当源文件的状态改变时间(ctime)比目标文件更新时或目标尚不存在时才进行复制
打包与解压
在这里插入图片描述
tar
-c:创建新的打包文件。
-t:列出打包文件的内容,查看已经打包了哪些文件。
-x:从打包文件中释放文件。
-f:指定打包文件名。
-v:详细列出 tar 处理的文件信息。
-z:用 gzip 来压缩/解压缩打包文件。
-j:用 bzip2 来压缩/解压缩打包文件。
-J:用 xz 来压缩/解压缩打包文件。
tar -options 目标文件 源文件夹
命令别名
alias [alias_name='original_command']
- original_command命令中包含空格或其他的特殊字符串必须使用引号。
- 在定义别名时,等号两边不允许有空格。
- 不带任何参数的alias命令显示当前已定义的所有别名。
- 可以使用 unalias alias_name 命令取消某个别名的定义。
- 如果用户需要别名的定义在每次登录时均有效,应该将其写入用户自家目录下的.bashrc文件中。
- 若系统中有一个命令,同时又定义了一个与之同名的别名(例如,系统中有grep命令,且又定义了grep的别名),则别名将优先于系统中原有的命令的执行。
- 要想临时使用系统中的命令而非别名,应该在命令前添加“\”字符,例如,$ \grep命令将运行系统中原来的grep命令而不是grep别名,它不在输出中显示颜色。
正则表达式
...x..x..x
^d
^the
sh$
^....$
^$
\.
^.2
\*\.pas
t.*\.sh$
t*\.sh$
.a.*
[ ]中都是单个字符匹配
[0123456789]
[0-9]
[a-zA-Z0-9\-]
[^0-9]
[^abc]
^[^1]
[Gg]reen
[a-z][a-z]*
^\.[0-9][0-9]
grep
grep 用正则表达式搜索文本,把匹配的行打印出来
- grep 使用 Basic regular expression (BRE) 书写匹配模式,等效于 grep -G
- egrep 使用 Extended regular expression (ERE) 书写匹配模式,等效于 grep -E
- fgrep 不使用任何正则表达式书写匹配模式(以固定字符串对待),执行快速搜索,等效于 grep -F
grep [options] PATTERN [FILE...]
PATTERN: 可以是普通字符串 可以是正则表达式,通常用单引号将RE括起来
FILE: 可以是用空格间隔的多个文件,也可是使用Shell的通配符在多个文件中查找PATTERN,省略时表示在标准输入中查找。
-c 只显示匹配行的次数
-i 搜索时不区分大小写
-n 输出匹配行的行号
-v 输出不匹配的行(反向选择)
-r 对目录(子目录)的所有文件递归地进行
-l 列出匹配PATTERN的文件名
--color=auto 对匹配内容高亮显示
-A NUM 同时输出匹配行的后 NUM 行
-B NUM 同时输出匹配行的前 NUM 行
-C NUM 同时输出匹配行的前、后各 NUM 行
$ grep mystr myfile 在文件 myfile 中查找包含字符串 mystr的行
$ grep '^[a-zA-Z]' myfile 显示 myfile 中第一个字符为字母的所有行
$ grep -v '^#' myfile。 在文件 myfile 中查找首字符不是 # 的行(即过滤掉注释行)
$ egrep -v ‘^#|^$|^;’ /etc/samba/smb.conf 过滤掉/etc/samba/smb.conf的注释行和空行
# grep -lr root /etc/* 列出/etc目录(包括子目录)下所有文件内容中包含字符串“root”的文件名
$ grep \\$ myfile 在文件 myfile 中查找包含字符 $(在RE中具有特殊含义) 的行
$ grep '\$' myfile
$ fgrep '$' myfile
$ fgrep $ myfile
文本显示
cat /etc/passwd 滚屏显示文件/etc/passwd的内容
cat -n /etc/passwd 滚屏显示文件/etc/passwd的内容,并显示行号
more /etc/passwd 分屏显示文件/etc/passwd的内容(注意空格键、回车键和q的使用)
more +10 /etc/passwd 从第10行分屏显示文件/etc/passwd的内容
less /etc/passwd 分屏显示文件/etc/passwd的内容(注意空格键、回车键、PgDn键、PgUp键和q的使用)
head -4 myalllist 显示文件myalllist前4行的内容
tail -4 myalllist 显示文件myalllist后4行的内容
tail +10 myalllist 显示文件myalllist从10行开始到文件尾的内容
tail -f /var/log/messages 跟踪显示不断增长的文件结尾内容(通常用于显示日志文件)
wc 统计文本
sort 以行为单位对文本文件排序
uniq 删除文本文件中连续的重复的行
diff 比较两个文本文件的差异
diff3 比较三个文本文件的差异
patch 为文本文件打补丁
aspell 为文本文件做拼写检查(西文)
$ wc file
$ wc -l file # 统计行数
$ wc -w file # 统计字数
$ wc -c file # 统计字符数
$ wc -L file # 统计最长一行的长度
# cut命令
-d:指定字段的分隔符,默认的字段分隔符为“TAB”;
-f:显示指定字段的内容;
-b:仅显示行中指定字节范围的内容;
-c:仅显示行中指定字符范围的内容;
-n:与“-b”选项连用,不分割多字节字符;
-s:不打印不包含分割符的行
--complement:显示指定字段以外的字段
--out-delimiter=<字段分隔符>:指定输出内容的字段分割符;默认输出内容的分隔符是输入的分隔符,但使用该参数指定后,可以修改输出内容的分隔符
# sort命令
-r 逆向排序
-f 忽略字母的大小写
-n 根据字符串的数值进行排序
-u 对相同的行只输出一行
-t c 选项使用c做为列的间隔符
-b 忽略前导的空格
-i 只考虑可打印字符
-k N 以第N列进行排序(默认以空格或制表符作为列的间隔符)
-r 颠倒比较结果
sed
sed 以按顺序逐行的方式工作,过程为:
- 从输入读取一行数据存入临时缓冲区,此缓冲区称为模式空间(pattern space)
- 按指定的 sed 编辑命令处理缓冲区中的内容
- 把模式空间的内容送往屏幕并将这行内容从模式空间中删除
- 读取下面一行。
- 重复过程1
-r:使用扩展正则表达式进行模式匹配
-i:直接对输入文件进行sed的命令操作
-n: 安静模式,并非所有stdin信息都输出到屏幕上,只有经过sed处理那一行列出(--quiet)
-e:sed执行指令
-f:将sed动作写到文档内,-f filename可以执行文档内的sed指令
-r:不需要转义
-h:帮助,--help
=:打印匹配行的行号
-V: --version
- 可以指定多个编辑命令,每个编辑命令前都要使用 -e 参数,sed 将对这些编辑命令依次进行处理。若只有一个编辑命令时,-e 可以省略。
- 每个sed的编辑命令cmdX均应使用单引号括起来。
- input-file:sed 处理的文件列表,若省略,sed 将从标准输入中读取输入,也可以从输入重定向或管道获得输入。
-e 执行的范围动作
x x为行号
x,y 表示行号从x到y
/pattern/ 查询包含模式的行
/pattern/, /pattern/ 查询包含两个模式的行
/pattern/,x 在给定行号上查询包含模式的行
x,/pattern/ 通过行号和模式查询匹配的行
x,y! 查询不包含指定行号x和y的行
(…)或者\(..\) 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers
& 保存要查找的串用在替换串中引用,如s/love/&/,love这成love
\< 匹配单词的开始,锚点词首,如:/匹配单词的结束,锚点词尾,如/love>/匹配包含以love结尾的单词的行
\:单词锚点
x{m} 或者 x\{m\} 重复字符x,m次,如:/0{5}/匹配包含5个0的行
x{m,} 或者x\{m,\}重复字符x,至少m次,如:/0{5,}/匹配至少有5个0的行
x{m,n} 或者x\{m,n\}重复字符x,至少m次,不多于n次,如:/0{5,10}/匹配5~10个0的行
sed '/omc/,10d' yum.log 删除yum.log包含"omc"的行到第十行的内容
sed '1,4i hahaha' yum.log 在文件yum.log第一行和第四行的每行下面添加hahaha
sed '/hhh/,/omc/d' yum.log 删除包含"hhh"的行到包含"omc"的行之间的行
(…)或者\(..\) 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers
& 保存要查找的串用在替换串中引用,如s/love/&/,love这成love
\< 匹配单词的开始,锚点词首,如:/匹配单词的结束,锚点词尾,如/love>/匹配包含以love结尾的单词的行
\:单词锚点
x{m} 或者 x\{m\} 重复字符x,m次,如:/0{5}/匹配包含5个0的行
x{m,} 或者x\{m,\}重复字符x,至少m次,如:/0{5,}/匹配至少有5个0的行
x{m,n} 或者x\{m,n\}重复字符x,至少m次,不多于n次,如:/0{5,10}/匹配5~10个0的行
a :新增, a 的後面可以接字串,而這些字串會在新的一行出現(目前的下一行)
c :取代, c 的後面可以接字串,這些字串可以取代 n1,n2 之間的行!
d :刪除,因為是刪除啊,所以 d 後面通常不接任何咚咚;
i :插入, i 的後面可以接字串,而這些字串會在新的一行出現(目前的上一行);
p :列印,亦即將某個選擇的資料印出。通常 p 會與參數 sed -n 一起運作;
s :取代,可以直接進行取代的工作哩!通常這個 s 的動作可以搭配正規表示法!
q:退出
g: 在行内进行全局替换(不加表示只对匹配行首次出现替换)
ng: 匹配行第n次出现进行替换
w: 将所选的行写入文件
r: 从文件中读取输入行
! 对所选行以外的所有行应用命令
sed ‘/FTP/a\ 456′ /etc/passwd 在含有FTP的行后面新插入一行,内容为456
sed ‘/FTP/i\ 123′ /etc/passwd 在含有FTP的行前面新插入一行,内容为123
sed ‘/FTP/i\ “123″’ /etc/passwd 在含有FTP的行前面新插入一行,内容为”123″
sed ’5a\ 123′ /etc/passwd 在第5行后插入一新行,内容为123
sed ’5 i\ “12345″’ /etc/passwd 在第5行前插入一新行,内容为”12345″
VIM文本编辑器
vi +n filename 打开文件filename,并将光标置于第n行首
vi + filename 打开文件filename,并将光标置于最后一行首
vi +/pattern filename 打开文件filename,并将光标置于第一个与pattern匹配的串处
vi -r filename 打开上次用vi编辑时发生系统崩溃,恢复filename

在普通模式下:
- 若输入的字符是合法的 vim 命令,则 vim 在接受用户命令之后完成相应的动作,输入的命令并不在屏幕上显示出来;
- 若输入的字符不是 vim 的合法命令,vim 会响铃报警。
- 从键盘上输入的任何字符都被当做编辑命令来解释。
G 用于直接跳转到文件尾
x 删除光标所在的字符
r 替换光标所在的字符
~ 切换光标所在字母的大小写
/和? 用于查找字符串
dd、YY、p 分别用于剪切、复制和粘贴一行文本
u 取消上一次编辑操作(undo)
. 重复上一次编辑操作(redo)
ZZ 用于存盘退出Vi
ZQ 用于不存盘退出Vi
/word 向光标之下寻找一个名称为 word 的字符串。例如要在档案内搜寻 vbird 这个字符串,就输入 /vbird 即可! (常用)
?word 向光标之上寻找一个字符串名称为 word 的字符串。
n 这个 n 是英文按键。代表『重复前一个搜寻的动作』。举例来说, 如果刚刚我们执行 /vbird 去向下搜寻 vbird 这个字符串,则按下 n 后,会向下继续搜寻下一个名称为 vbird 的字符串。如果是执行 ?vbird 的话,那么按下 n 则会向上继续搜寻名称为 vbird 的字符串!
N 这个 N 是英文按键。与 n 刚好相反,为『反向』进行前一个搜寻动作。 例如 /vbird 后,按下 N 则表示『向上』搜寻 vbird 。
:n1,n2s/word1/word2/g
n1 与 n2 为数字。在第 n1 与 n2 行之间寻找 word1 这个字符串,并将该字符串取代为 word2 !举例来说,在 100 到 200 行之间搜寻 vbird 并取代为 VBIRD 则:『:100,200s/vbird/VBIRD/g』。(常用)
:1,$s/word1/word2/g 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !(常用)
:1,$s/word1/word2/gc 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !且在取代前显示提示字符给用户确认 (confirm) 是否需要取代!(常用)
[Ctrl] + [f] 屏幕『向下』移动一页,相当于 [Page Down]按键 (常用)
[Ctrl] + [b] 屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用)
0 或功能键[Home] 这是数字『 0 』:移动到这一行的最前面字符处 (常用)
$ 或功能键[End] 移动到这一行的最后面字符处(常用)
G 移动到这个档案的最后一行(常用)
nG n 为数字。移动到这个档案的第 n 行。例如 20G 则会移动到这个档案的第 20 行(可配合 :set nu)
gg 移动到这个档案的第一行,相当于 1G 啊! (常用)
n n 为数字。光标向下移动 n 行(常用)
复制游标所在的那一行(常用) n 为数字。复制光标所在的向下 n 列,例如 20yy 则是复制 20 列(常用)
dd 删除游标所在的那一整列(常用)
ndd n 为数字。删除光标所在的向下 n 列,例如 20dd 则是删除 20 列 (常用)
p, P p 为将已复制的数据在光标下一行贴上,P 则为贴在游标上一行! 举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p 后, 那 10 行数据会贴在原本的 20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢? 那么原本的第 20 行会被推到变成 30 行。 (常用)
u 撤销前一个动作。(常用)
[Ctrl]+r 重做上一个动作。(常用)
. 不要怀疑!这就是小数点!意思是重复前一个动作的意思。 如果你想要重复删除、重复贴上等等动作,按下小数点『.』就好了! (常用)
insert插入模式
- Normal 模式下输入插入命令 i、附加命令 a 、打开命令 o、修改命令 c、取代命令 r 或替换命令 s 等都可进入 Insert 模式。
- 在该模式下,用户输入的任何字符都被vim当做文件内容保存起来,并将其显示在屏幕上。在文本输入过程中,若想回到Normal模式下,按 Esc 键即可。
commond模式
- 进入该模式后vim 会在显示窗口的最后一行 (屏幕的最后一行) 显示一个 “:” 作为 Command 模式的提示符,等待输入命令。
- 多数文件管理都是在此模式下执行的 (如保存文件等)
- Command 模式中所有的命令都必须按 <回车>后执行,命令执行完后,vim 自动回到 Normal 模式
- 若在 Command 模式下输入命令过程中改变了主意,可按 Esc键,或用退格键将输入的命令全部删除之后,再按一下退格键,即可使 vi 回到 Normal 模式下。
:n1,n2 co n3 用于块复制
:n1,n2 m n3 用于块移动
:n1,n2 d 用于块删除
:w 保存当前编辑文件,但并不退出
:w newfile 存为另外一个名为 “newfile” 的文件
:wq 用于存盘退出Vi
:q! 用于不存盘退出Vi
:q 用于直接退出Vi (未做修改)
:set autoindent 缩进,常用于程序的编写
:set noautoindent 取消缩进
:set number 在编辑文件时显示行号
:set nonumber 不显示行号
:set tabstop=value 设置显示制表符的空格字符个数
:set 显示设置的所有选项
:set all 显示所有可以设置的选项
:w 将编辑的数据写入硬盘档案中(常用)
:w! 若文件属性为『只读』时,强制写入该档案。不过,到底能不能写入, 还是跟你对该档案的档案权限有关啊!
:q 离开 vi (常用)
:q! 若曾修改过档案,又不想储存,使用 ! 为强制离开不储存档案
:wq 储存后离开,若为 :wq! 则为强制储存后离开 (常用)
ZZ 这是大写的 Z 喔!若档案没有更动,则不储存离开,若档案已经被更动过,则储存后离开!
:w [filename] 将编辑的数据储存成另一个档案(类似另存新档)
:r [filename] 在编辑的数据中,读入另一个档案的数据。亦即将『filename』 这个档案内容加到游标所在行后面
:n1,n2 w [filename] 将 n1 到 n2 的内容储存成 filename 这个档案。
:! command 暂时离开 vi 到指令列模式下执行 command 的显示结果!例如
『:! ls /home』即可在 vi 当中察看 /home 底下以 ls 输出的档案信息!
:set nu 显示行号,设定之后,会在每一行的前缀显示该行的行号
:set nonu 与 set nu 相反,为取消行号!
重定向
< 输入重定向
< 覆盖式的输出重定向
>> 追加式的输出重定向
2> 覆盖式的错误输出重定向
2>> 追加式的错误输出重定向
&> 同时实现输出重定向和错误重定向(覆盖式)
空设备是个黑洞,发往它的任何内容都将不复存在
经常用于屏蔽命令的输出或错误输出,尤其用于Shell脚本中
$ myprogram &> /dev/null
$ myprogram >/dev/null 2>&1 屏蔽命令的输出和错误输出
$ cp /dev/null myfile
$ > myfile 清空文件内容
管道运算符
统计磁盘占用情况
统计当前目录下磁盘占用最多的10个一级子目录
$ du . --max-depth=1 | sort -rn | head -11
以降序方式显示使用磁盘空间最多的普通用户的前十名
$ du * -cks | sort -rn | head -11
以排序方式查看当前目录(不包含子目录)的磁盘占据情况。
$ du -S | sort -rn | head -11
统计进程
按内存使用从大到小排列输出进程。
# ps -e -o "%C : %p : %z : %a"|sort -k5 -nr
按CPU使用从大到小排列输出进程。
# ps -e -o "%C : %p : %z : %a"|sort -nr
列出YUM仓库中所有可用的 Apache 模块并按升序输出
# yum list | grep ^mod_ | cut -d'.' -f 1 | sort
# yum list | grep ^mod_ | awk -F\. '{print $1}' | sort
以排序方式列出YUM仓库中在 /etc/httpd/conf.d/ 目录下生成配置文件的所有 Web 应用软件包(不包含 Apache 模块)
# repoquery --queryformat="%{NAME}\n" \
--whatprovides “/etc/httpd/conf.d/*” | \
egrep -v "(^$|^mod)" | sort | uniq
从ifconfig 命令的输出过滤出 eth0 网络接口当前的IPv4地址
# ifconfig eth0 | awk -F\: '/inet / {print $2}'|awk '{print $1} '
# ifconfig eth0 | grep 'inet ' | awk -F '[ :]+' ' {print $4}'
# ifconfig eth0 | grep -i 'inet[^6]' | sed 's/[a-zA-Z:]//g' | awk '{print $1}‘
从ip命令的输出过滤出 eno16777736网络接口当前的IPv4地址
# ip a s eno16777736|grep 'inet '| awk -F '[ /]+' '{print $3}'
命令1 | tee 文件名 | 命令2
将命令1的STDOUT保存在文件名中,然后管道输入给命令2
$(command) 或 `command`
cmd1 $(cmd2) 或 cmd1 `cmd2`
SHELL变量
内部变量:由系统提供,用户只能使用不能修改
用户变量:由用户建立和修改,在 shell 脚本编写中会经常用到
环境变量:这些变量决定了用户工作的环境,它们不需要用户去定义,可以直接在 shell 中使用,其中某些变量用户可以修改
单引号对中的字符都将作为普通字符,但不允许出现另外的单引号
双引号对中的部分字符仍保留特殊含义:
$(美元符号)- 变量扩展
`(反引号) - 命令替换
\(反斜线) - 禁止单个字符扩展
!(叹号) - 历史命令替换
局部变量:作用范围仅仅限制在其命令行所在的Shell或Shell脚本文件中
全局变量:作用范围则包括本Shell进程及其所有子进程
export 内置命令 局部变量设置与全局变量互换

所有环境变量都是全局变量(即可传递给 Shell 的子进程),并可以由用户重新设置
Shell变量的查询、显示和取消
env 显示所有环境变量
set 显示所有变量和函数(包括环境变量)
echo $NAME1 [$NAME2 ……] 显示某(些)个变量的值
unset 取消变量的声明或赋值
用户工作环境
用户工作环境有登录环境和非登录环境之分
登录环境是指用户登录系统时的工作环境,此时的Shell对登录用户而言是主Shell
非登录环境是指用户再调用子Shell时所使用的用户环境
解释:
你只需登录一次,即时~/.bash_profile或~/.profile正在读取和执行。由于你从登录shell运行的所有内容都会继承登录shell的环境,因此应该将所有环境变量都放在此处。像LESS,PATH,MANPATH,LC_*
登录后,你可以运行多个shell。想象一下,登录,运行X,并在X中启动一些带有bash shell的终端。这意味着你的登录shell启动了X,它继承了登录shell的环境变量,这启动了你的终端,它启动了你的非登录bash shell。你的环境变量在整个链中传递,所以你的非登录shell不需要再加载它们。非登录shell只能执行~/.bashrc,不是/.profile或者~/.bash_profile,出于这个确切原因,所以在那里定义只适用于bash的所有内容。这就是函数,别名,只有bash的变量,如HISTSIZE(这不是一个环境变量,不会导出它!),带有setand的shell选项shopt等等。
现在,作为UNIX特性的一部分,登录shell不会执行,~/.bashrc但只会~/.profile或者~/.bash_profile,因此你应该从后者手动获取。你会看到我这样做,我~/.profile也:source ~/.bashrc。

自检问题
-
目录的颜色是什么?符号是什么?
d 蓝色 -
普通用户家目录是哪里?root用户家目录是哪里?
/home/XXX /root -
切换用户命令是什么?
-
注销用户的命令是什么?
-
虚拟终端切换的快捷键是什么?
-
如何判断1个命令是内部或者外部命令?
-
查看系统分区情况的命令是什么?
-
查看系统cpu情况的命令是什么?
-
查看主机名的命令是什么?查看Ip地址的命令是什么?
-
ls [!xz]*
-
cd ~vieta是相对路径还是绝对路径?
-
.和…分别代表什么意思?
-
符号l代表什么类型文件?
-
cd ./…
-
改名目录应该用哪个命令?
-
新建目录的命令是?新建文件的命令是?
-
查看时区的命令是?
-
系统语言配置文件是?
-
删除非空目录应该使用什么命令?
-
Linux系统中文件目录涉及的时间类型有哪些?
-
Linux中目录/etc的作用是什么?/usr作用是什么?
-
/dev/sr0表示什么设备?
-
在/tmp下没有music目录,现在在/tmp通过命令创建music目录和其下的子目录chinese,应该如何操作?
-
将目录/root/bookdir 复制到目录/tmp/des目录命名为docdir
-
ls -al第2列显示的链接数,是dentry还是inode数?是软链接数还是硬链接数?
-
字符终端下查看超长文本happy.txt,应该如何操作?
-
grep -vn ‘the’ regular.txt
-
grep -n ‘t[ae]st’ regular.txt
-
grep -n ‘[1]oo’ regular.txt
-
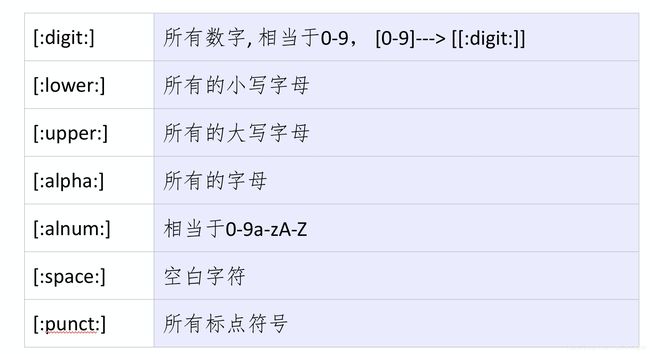
grep -n ‘[[:digit:]]’ regular.txt
-
grep -n ‘[a-zA-Z]’ regular.txt
-
grep -n ‘g*g’ regular.txt
-
grep -n ‘g.*g’ regular.txt
-
查找/home/rose目录下名字以.txt结尾的软链接文件
-
Vim如何查找reader字符串?
-
sed ‘ $a # This is a test’ regular.txt
-
sed ‘s/.$/!/g’ regular.txt
-
sed ‘s/^.*inet //g’
-
sed ‘s/ *netmask.*$//g’
:lower: ↩︎