爬取python、java、html在北京的工作岗位,写入数据库,写入csv文件,并统计北京各个区的工作岗位数量,各个薪资水平的数量,以 柱状图/直方图展示
进入终端 scrapy startproject 项目名称
Pycharm打开项目
编写蜘蛛
spider代码:
进入终端 scrapy startproject 项目名称
Pycharm打开项目
编写蜘蛛
spider代码:
# -*- coding: utf-8 -*-
import scrapy
from ..items import JobsItem
class JobSpider(scrapy.Spider):
name = 'job'
allowed_domains = ['51job']
start_urls = ['http://search.51job.com/list/010000,000000,0000,00,9,99,python,2,1.html','http://search.51job.com/list/010000,000000,0000,00,9,99,java,2,1.html','http://search.51job.com/list/010000,000000,0000,00,9,99,html,2,1.html']
def parse(self, response):
# 1.本页数据重新发起请求,进行解析
yield scrapy.Request(
url=response.url,
callback=self.parse_detail,
# 指定是否参与去重,默认值False
# 改为True,不参与去重
dont_filter=True
)
def parse_detail(self,response):
# 2.找到下一页按钮
next_page = response.xpath("//li[@class='bk'][2]/a/@href")
if next_page:
# 发起请求
yield scrapy.Request(
url=next_page.extract_first(''),
callback=self.parse_detail,
# 不参与去重
dont_filter=True
)
# 找到所有的工作岗位标签
jobs = response.xpath("//div[@id='resultList']/div[@class='el']")
for job in jobs:
# 薪资
job_money = job.xpath("span[@class='t4']/text()").extract_first('')
# 把按月薪万或千的数据拿回来
if '月' in job_money:
if '千' in job_money:
money = job_money.split('千')[0]
min_money = float(money.split('-')[0])*1000
max_money = float(money.split('-')[1])*1000
elif '万' in job_money:
money = job_money.split('万')[0]
min_money = float(money.split('-')[0])*10000
max_money = float(money.split('-')[1])*10000
else:
continue
else:
continue
# 工作名称
job_name = job.xpath("p/span/a/@title").extract_first('')
# 详情地址
detail_url = job.xpath("p/span/a/@href").extract_first('')
# 公司名称
company_name = job.xpath("span[@class='t2']/a/text()").extract_first('')
# 工作地点
job_place = job.xpath("span[@class='t3']/text()").extract_first('')
# 发布日期
job_date = job.xpath("span[@class='t5']/text()").extract_first('')
item = JobsItem()
item["job_name"] = job_name
item["job_place"] = job_place
item["detail_url"] = detail_url
item["company_name"] = company_name
item["job_date"] = job_date
item["job_money"] = job_money
item["max_money"] = max_money
item["min_money"] = min_money
yield itemclass JobsItem(scrapy.Item):
job_name = scrapy.Field()
detail_url = scrapy.Field()
company_name = scrapy.Field()
job_place = scrapy.Field()
job_date = scrapy.Field()
job_money = scrapy.Field()
min_money = scrapy.Field()
max_money = scrapy.Field()from fake_useragent import UserAgent
from random import choice
class RandomUAMiddleware(object):
def __init__(self,crawler):
super(RandomUAMiddleware, self).__init__()
self.crawler = crawler
self.ua = UserAgent()
self.ip_list = ['60.18.164.46:63000','61.135.217.7:80','123.7.38.31:9999']
@classmethod
def from_crawler(cls,crawler):
return cls(crawler)
# 处理请求函数
def process_request(self,request,spider):
# 随机产生请求头
request.headers.setdefault('User-Agent',self.ua.random)import csv
import codecs
class SaveCSVFile(object):
def __init__(self):
self.file_handle = codecs.open('jobs.csv','w',encoding='utf-8')
# 1.创建csv文件
self.csv = csv.writer(self.file_handle)
self.csv.writerow(('job_name','detail_url','company_name','job_place','job_date','job_money','min_money','max_money'))
def process_item(self,item,spider):
self.csv.writerow((item['job_name'],item['detail_url'],item['company_name'],item['job_place'],item['job_date'],item['job_money'],item['min_money'],item['max_money']))
return item
def __del__(self):
# 关闭文件
self.file_handle.close()
from twisted.enterprise import adbapi
from MySQLdb import cursors
class MysqlTwistedPipeline(object):
@classmethod
# 这个函数会自动调用
def from_settings(cls,settings):
# 准备好连接数据库需要的参数
db_params = dict(
host = settings["MYSQL_HOST"],
port = settings["MYSQL_PORT"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWD"],
charset = settings["MYSQL_CHARSET"],
db = settings["MYSQL_DBNAME"],
use_unicode = True,
# 指定游标类型
cursorclass=cursors.DictCursor
)
# 创建连接池
# 1.要连接的名称 2.连接需要的参数
db_pool = adbapi.ConnectionPool('MySQLdb',**db_params)
# 返回当前类的对象,并且把db_pool赋值给该类的对象
return cls(db_pool)
def __init__(self,db_pool):
# 赋值
self.db_pool = db_pool
# 处理item函数
def process_item(self,item,spider):
# 把要处理的事件进行异步处理
# 1.要处理的事件函数
# 2.事件函数需要的参数
query = self.db_pool.runInteraction(self.do_insert,item)
# 执行sql出现错误信息
query.addErrback(self.handle_error,item,spider)
return item
# 错误的原因
def handle_error(self,failure,item,spider):
print failure
# 处理插入数据库的操作
# cursor该函数是连接数据库的函数,并且放在异步去执行,cursor执行sql语句
def do_insert(self,cursor,item):
# 1.准备sql语句
sql = 'insert into job(job_name,detail_url,company_name,job_place,job_date,job_money,min_money,max_money)VALUES (%s,%s,%s,%s,%s,%s,%s,%s)'
# 2.用cursor游标执行sql
cursor.execute(sql, (item["job_name"], item["detail_url"], item["company_name"], item["job_place"], item["job_date"], item["job_money"],item["min_money"], item["max_money"]))DOWNLOADER_MIDDLEWARES = {
'ZHB51Job.middlewares.RandomUAMiddleware': 100,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None
}ITEM_PIPELINES = {
'JobsSpider.pipelines.MysqlTwistedPipeline': 300,
'JobsSpider.pipelines.SaveCSVFile': 301,
}MYSQL_HOST = '127.0.0.1'
MYSQL_PORT = 3306
MYSQL_DBNAME = 'jobs'
MYSQL_USER = 'root'
MYSQL_PASSWD = '123456'
MYSQL_CHARSET = 'utf8'from scrapy.cmdline import execute
execute(['scrapy','crawl','spider'])# -*- coding:utf-8 -*-
import sys
import matplotlib.pyplot as plt
import numpy
reload(sys)
sys.setdefaultencoding("utf-8")
import pandas as pd
df_obj = pd.read_csv('job.csv')
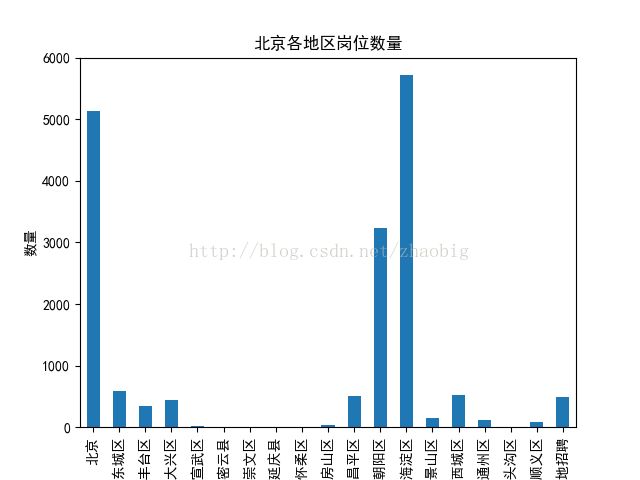
# 北京各岗位的数量
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
number = df_obj.groupby(df_obj['job_place']).size()
print number
number.plot.bar()
plt.title('北京各地区岗位数量')
plt.xlabel('地区')
plt.ylabel('数量')
plt.savefig('job.png')
plt.show()
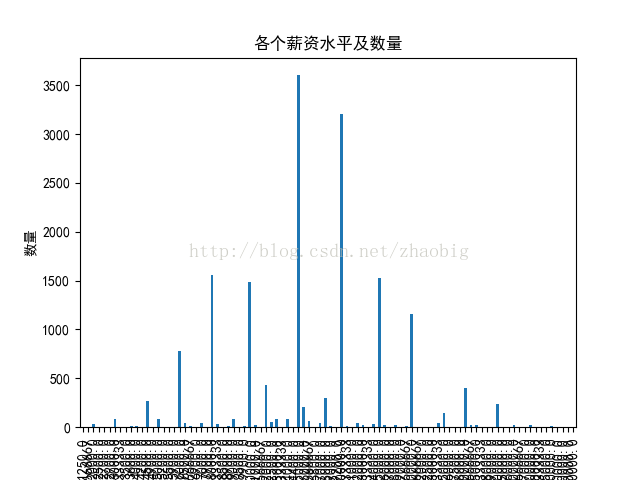
# 薪资及数量分布图df_obj1=df_obj[df_obj['max_money']>0]
max_money = df_obj1.groupby(df_obj1['max_money']).size()
max_money.plot.bar()
plt.title('各个薪资水平及数量')
plt.xlabel('薪资')
plt.ylabel('数量')
plt.savefig('pay.png')
plt.show()