移植Linux内核链表
Linux内核源码中的链表是一个双向循环链表,该链表的设计具有优秀的封装性和可扩展性。本文将从2.6.39版本内核的内核链表移植到Windows平台的visual studio2010环境中。链表的源码位于内核源码的include/linux/list.h中。移植的步骤如下:
(1)去除依赖的头文件
list.h依赖的头文件如下:
#include 依次进入这4个头文件,提取文件内的有被list使用到的代码:
//types.h:
struct list_head {
struct list_head *next, *prev;
};
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};//stddef.h:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)offsetof宏可参考offsetof和container_of一般它和container_of宏配合使用。内核的container_of原型如下:
#define container_of(ptr, type, member) ({ \
const typeof(((type*)0)->member)* __mptr = (ptr); \
(type*)((char*)__mptr - offsetof(type, member)); })因为typeof是GNU C编译器的关键字,微软编译器并不支持,所以不能使用该关键字,即没有类型检查的功能:
#define m_container(ptr, type, member) ((type *)( (char *)ptr - offsetof(type,member)))//poison.h:
#define LIST_POISON1 ((void *) 0x00100100 + POISON_POINTER_DELTA)
#define LIST_POISON2 ((void *) 0x00200200 + POISON_POINTER_DELTA)list的删除节点函数list_del()的实现中最后将被删除的节点的next和pre指针分别为LIST_POISON1和LIST_POISON2,所以可以将这两个宏修改为:
#define LIST_POISON1 ((void *) 0x00)
#define LIST_POISON2 ((void *) 0x00)//prefetch.h:
#define prefetch(x) __builtin_prefetch(x)__builtin_prefetch()是GNU C编译器特有的内置函数,意义在于代码优化。因为我们要将list.h移植到使用微软编译器的平台,所以不可使用__builtin_prefetch()函数,可修改为:
#define prefetch(x) ((void*)(x)) (2)将list.h中的所有函数的声明属性“static inline”修改为“static”,因为“static inline”同时修饰一个函数只在GNU C编译器声明。
链表的一般设计是: 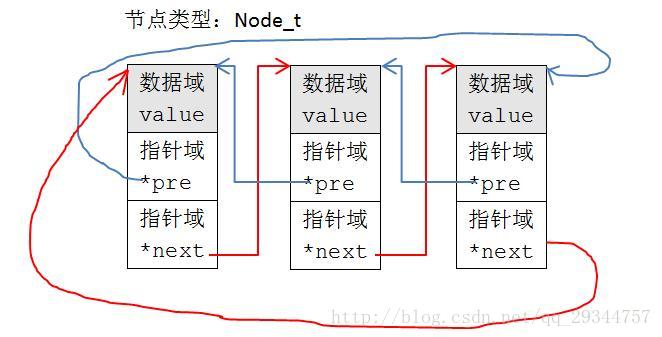
从图可见,节点的指针域指向的是下一个节点(或上一个节点)变量开始的地址,指针的类型为Node_t*。显然随着节点类型的不同,指针域的指针类型也要随之改变。Linux内核为了设计成具有封装性和扩展性的链表,将节点指针域中的指针的指向做了改变: 
作为双向循环链表的节点,每一个类型节点的指针域都具有两个指针,这是不变的,内核将指针的指向改为下一个节点(或上一个节点)变量的指针域开始地方,这样每一个节点的定义只需要包含内核定义的指针域类型即可使用内核链表。链表的操作(如增加/删除)是针对指针域类型的,所以这些函数能适用于任何使用内核链表组织的数据。
注意,这样一来,我们要访问使用内核链表的节点的数据域时,不可以直接通过指针域的的指向的地址来访问,中间需要一个转换过程,即使用内核的container_of宏,container_of可以实现通过结构体的某个成员变量的地址获取结构体变量的起始地址,我们通过该地址就可以获取给结构体的任意成员了,这正是Linux内核设计的巧妙之处。
内核链表的常用函数/宏有:
1.INIT_LIST_HEAD():初始化链表(头)
2.list_add():在;链表头插入节点
3.list_add_tail():在链表尾部插入节点
4.list_del():删除节点
5.list_entry():通过节点的指针域获取数据节点的起始地址
6.list_for_each():遍历链表(不可和list_del()配合使用)
7.list_for_each_safe():安全的遍历链表(可和list_del()配合使用))编写测试函数(1):
void list_test1()
{
struct Node_t
{
struct list_head head;
char value;
};
int i;
struct Node_t l = {0}; //定义头节点
struct list_head* p = NULL;
struct list_head* n;
//初始化链表(头节点)
INIT_LIST_HEAD(&l.head);
for (i = 0; i < 6; ++i)
{
struct Node_t* n = (struct Node_t* )malloc(sizeof(struct Node_t));
n->value = i;
//将新节点尾插到链表中
list_add_tail(&n->head, &l.head);
}
//遍历链表
list_for_each(p, &l.head)
{
//因为Node_t的第一个成员的类型就是struct list_head类型,所以可以强制类型转换
printf("%-2d", ((struct Node_t*)p)->value);
}
printf("\n");
list_for_each(p, &l.head)
{
//删除第一个value为2的节点
if (((struct Node_t*)p)->value == 2)
{
list_del(p); //执行list_del()后p的指针域都指向NULL
free((struct Node_t*)p);
break;
}
}
list_for_each(p, &l.head)
{
printf("%-2d", list_entry(p, struct Node_t, head)->value);
}
printf("\n");
//不可以通过list_for_each遍历来逐一销毁动态分配的节点,因为销毁完第一个节点后p的指针域都置为0
//而list_for_each宏是通过p来遍历下一个节点的
//list_for_each(p, &l.head)
//{
// list_del(p);
//}
//可以使用list_for_each_safe遍历来逐一销毁动态分配的节点,因为该宏使用了n来备份p指针
list_for_each_safe(p, n, &l.head)
{
list_del(p);
free((struct Node_t*)p); //销毁节点
//或者free(list_entry(p, struct Node_t, head)); //销毁节点
}
}测试函数(2):
void list_test2()
{
struct Node_t
{
char value;
struct list_head head;
};
struct Node_t l = {0};
struct list_head* p;
struct list_head* n;
int i;
//初始化链表(头节点)
INIT_LIST_HEAD(&l.head);
for (i = 0; i < 6; ++i)
{
struct Node_t* n = (struct Node_t* )malloc(sizeof(struct Node_t));
n->value = i;
//将新节点以头插的方式插入链表中
list_add(&n->head, &l.head);
}
//遍历打印
list_for_each(p, &l.head)
{
printf("%-2d", list_entry(p, struct Node_t, head)->value);
}
printf("\n");
//遍历链表
list_for_each(p, &l.head)
{
//因为Node_t的第一个成员不是list_head类型成员,所以需要list_entry宏获取Node_t类型对象的
//起始地址,进而访问其value成员
struct Node_t *n = list_entry(p, struct Node_t, head);
if (n->value == 2)
{
list_del(p);
free(n);
break;
}
}
list_for_each(p, &l.head)
{
printf("%-2d", list_entry(p, struct Node_t, head)->value);
}
printf("\n");
list_for_each_safe(p, n, &l.head)
{
list_del(p);
free(list_entry(p, struct Node_t, head)); //销毁节点
}
}使用内核链表需要注意:
a. 不可以使用list_for_each遍历链表节点并销毁节点,原因见代码注释;
b. 访问节点的数据域时,如果节点类型的第一个成员不是list_head类型的变量时需要使用list_entry()获取节点类型变量的起始地址,进而访问节点的数据域,否则可以通过强制类型转换(考虑两个结构体变量的内存布局)。