斯坦福CS229机器学习笔记-Lecture9- Learning Theory 学习理论

声明:此系列博文根据斯坦福CS229课程,吴恩达主讲 所写,为本人自学笔记,写成博客分享出来
博文中部分图片和公式都来源于CS229官方notes。
CS229的视频和讲义均为互联网公开资源
Lecture 9
主要内容如下:
· Bias/variance tradeoff (偏差/方差均衡)
· Union Bound + Hoeffding Inequality (联合界+Hoeffding不等式)
· Empirical risk minimization(经验风险最小化)
1.Bias/variance tradeoff 偏差/方差的平衡
在我们用模型拟合数据的时候,可能会存在欠拟合 及 过拟合 现象,这样的模型的泛化性能不好, 即泛化误差较大。
如下图中左侧和右侧的情况

泛化误差 简单来讲, 就是说 没有包含于训练集之中 的样本 的预期误差。
泛化误差一般都涉及两部分,即:偏差 bias 和方差 variance, 这里并没有给出这两者的正式定义,因为究竟是什么样的定义最为合适目前也还存在争议。
笼统的来讲,如果我们的模型过于“简单(simple)”,而且参数非常少,那这样就可能会有很大的偏差(bias), 而方差(variance)可能就很小;如上图中的左侧图,其偏差bias就比较大,无法较好的概括数据的结构特征;
反之,如果我们的模型过于“复杂(complex)”,有非常多的参数,那就可能有特别大的方差(variance),而偏差(bias)就会小一些。如上图中的右侧图,过拟合,使得模型可能仅仅适用于当前的小规模训练集,泛化性能很差;
所以我们希望在 bias 和 variance 之间寻求一种平衡(tradeoff),以寻求较小的泛化误差(generalization error)。简单来讲,就是希望获得的模型,既能有效的概括出数据的结构特征,又对其他新的样本具有良好的适应性,
2.Union Bound + Hoeffding Inequality (联合约束+Hoeffding不等式)
为了后面的证明,需要先引入两个引理:
① Union bound(联合约束)(维基百科中提到,其实这就是布尔不等式)
设 A1, A2, ..., Ak 是 K个不同事件(但不一定互相独立),则有:
![]()
就是说,k 个事件同时发生的概率 最多是 k 个不同的事件每个都发生的概率的总和。
②Hoeffding Inequality(在机器学习理论里面也称为 切尔诺夫约束,)
设 Z1, ... , Zm 是 m 个独立同分布(同伯努利分布)的随机变量,
![]() 是这些随机变量的均值,则有:
是这些随机变量的均值,则有:![]()
它说明:假设我们从一个伯努利分布的随机变量中随机变量的均值![]() 去估计参数
去估计参数![]() ,估计的参数和实际参数的差超过一个特定数值
,估计的参数和实际参数的差超过一个特定数值![]() 的概率有一确定的上界,并且随着样本量m的增大,二者也就越接近。就是说,只要m 足够大,我们偏移真实值很远的概率就比较小。
的概率有一确定的上界,并且随着样本量m的增大,二者也就越接近。就是说,只要m 足够大,我们偏移真实值很远的概率就比较小。
3.Empirical risk minimization(经验风险最小化)







在上面的讨论中,我们做的是针对某些特定的 m 和 γ 值,给定一个概率约束:
![]() (最原始的那个式子,使用hoeffding不等式那个阶段,不是指化简后的最后结果),
(最原始的那个式子,使用hoeffding不等式那个阶段,不是指化简后的最后结果),
这里有三个变量, m 和 γ 以及 误差概率,事实上,我们可以通过其中任意两个来对另一个变量进行约束。
比如,如果给定 γ,并提供δ>0, 要求保证 训练误差处于泛化误差 附近 γ 的概率最小为 1-δ(这可以看作在给定误差概率),则可以列式如下:

这种联合约束说明了 需要多少数量的训练样本才能对结果有所保证。这种 为了使某些方法 达到特定的 表现水平所需要的 训练集的规模 m 也被称为 样本复杂度--Sample complexity。上面这个约束的关键特性在于要保证结果,所需的训练样本数量只有 k 的对数。
同理,如果固定 m 和 要求保证 训练误差处于泛化误差 附近 γ 的概率最小为 1-δ(这可以看作在给定误差概率)
那么 也能得到 γ的范围:
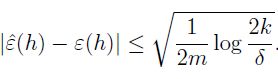
如此一来,我们就分别讨论了固定其中2个参数,另一个参数的限制范围。
现在,如果我们假设这个联合收敛成立,
也就是说,对于所有的![]()
也就是说,在上面的推导过程中的式子:
我们的学习算法选择了一个假设使得其获得的 训练误差最小![]()
那么我们如何证明其泛化性呢?








