163Python数据分析师课程考核项目07
163Python数据分析师课程考核项目07
泰坦尼克号获救问题
数据来源:
Kaggle数据集 → 共有1309名乘客数据,其中891是已知存活情况(train.csv),剩下418则是需要进行分析预测(test.csv),字段意义:
PassengerId: 乘客编号;Survived:存活情况(存活:1 ; 遇难:0); Pclass: 客舱等级;Name:乘客姓名;Sex:性别;Age:年龄;SibSp:同乘的兄弟姐妹/配偶数;Parch:同乘的父母/小孩数;Ticket:船票编号; Fare:船票价格;Cabin:客舱号;Embarked:登船港口。
目的:通过已知获救数据,预测乘客生存情况
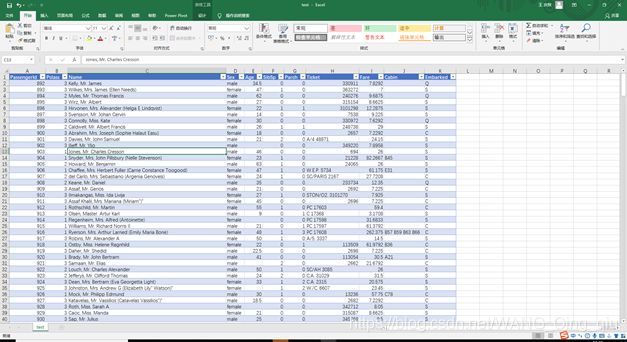
train数据一共891条
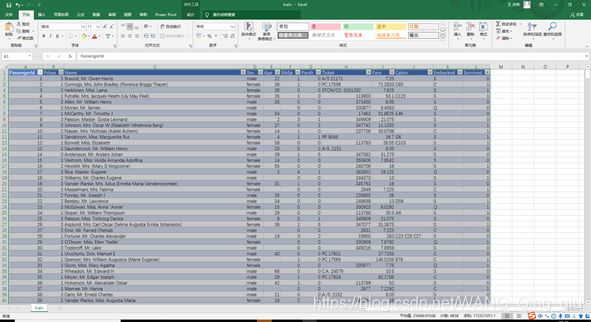
test数据一共417条
题目1
整体来看,存活比例如何?
要求:
① 读取已知生存数据train.csv
② 查看已知存活数据中,存活比例如何?
提示:
① 注意过程中筛选掉缺失值之后再分析
② 这里用seaborn制图辅助研究
代码
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 3 19:06:04 2019
@author: WQQ
"""
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# 导入作图模块
import seaborn as sns
from bokeh.models import ColumnDataSource
from bokeh.models import HoverTool
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
'''
1. 整体分析存活比例
'''
# 加载读取数据
import os
os.chdir('C:\\Users\\WQQ\\Desktop\\163data\\CLASSDATA_ch06数据分析项目实战\\练习09_泰坦尼克号获救问题\\')
data_train=pd.read_csv('train.csv',engine='python')
data_test=pd.read_csv('test.csv',engine='python')
# 提出需要的数据
data_sur=data_train['Survived'].reset_index()
# 绘制存活比率饼图
sns.set()
plt.axis('equal')
data_sur['Survived'].value_counts().plot.pie(autopct='%1.2f%%')
存活比率饼图
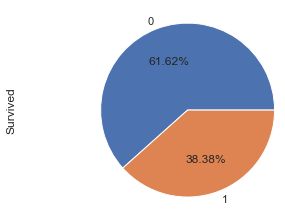
结论
0为遇难,遇难率为61.62%;1为幸存,幸存率为38.38。
题目2
结合性别和年龄数据,分析幸存下来的人是哪些人?
要求:
① 年龄数据的分布情况
② 男性和女性存活情况
③ 老人和小孩存活情况
代码
'''
# 2. 结合性别和年龄数据,分析幸存下来的是那些人
'''
# 绘制整体性别-年龄-幸存人数散点图
data_sur=data_train[['Survived','Age','Sex']]
data_sur.dropna(inplace=True)
data_sur=data_sur[data_sur['Survived']==1]
# 绘制幸存者性别-年龄散点图,点的大小代表获救的人数
# 改变参数方便绘制散点图
data_sur['Age'][data_sur['Age']<1]=0
data_sur['size']=0
data_sur['size']=data_sur.groupby(['Age','Sex']).cumsum()
data_sur['size']=data_sur['size']*2
data_sur['Sex'][data_sur['Sex']=='male']=0
data_sur['Sex'][data_sur['Sex']=='female']=1
data_cir=data_sur.groupby(['Age','Sex']).max()
# 提取散点图横纵坐标
data_cir['mix']=data_cir.index
data_cir['mix']=data_cir['mix'].astype(str).str.replace('(','').str.replace(')','')
data_cir['age']=data_cir['mix'].str.split(',', expand=True)[0]
data_cir['sex']=data_cir['mix'].str.split(',', expand=True)[1]
data_cir['age']=data_cir['age'].drop(0)
data_cir.dropna(inplace=True)
data_cir['age']=data_cir['age'].astype(float)
data_cir['sex']=data_cir['sex'].astype(float)
# 设置男女不同颜色
data_cir['color']=data_cir['sex']
data_cir['color'][data_cir['color']==1]='red'
data_cir['color'][data_cir['color']==0]='blue'
# 绘制幸存者性别-年龄散点图,点的大小代表获救的人数的多少
# 创建ColumnDataSource数据
source = ColumnDataSource(data_cir)
hover = HoverTool(tooltips=[("幸存人数","@size"), ("年龄","@age")])
# 构建绘图空间
s_a= figure(plot_width=800,plot_height=250,title="幸存者性别-年龄散点图",x_axis_label = 'Age',y_axis_label='Sex:1-female;0-male',
tools=[hover,'box_select,reset,xwheel_zoom,pan,crosshair'])
# 绘制散点图
s_a.circle(x='age',y='sex',source=source,line_color = 'black',line_dash = [6,4],fill_alpha = 0.6,size = 'size',fill_color='color')
s_a.title.text_font_style = "bold"
s_a.xgrid.grid_line_dash = [6, 4]
show(s_a)
# 整体年龄数据的分布情况
data_age=data_train[['Survived','Age']]
data_age=data_age[data_age['Age'].notnull()]
plt.figure(figsize=(12,5))
plt.subplot(121)
data_age['Age'].hist(bins=70)
plt.xlabel('Age')
plt.ylabel('Num')
plt.subplot(122)
data_age.boxplot(column='Age',showfliers=False)
print('数据一共包含%.f人,平均年龄%.f岁。' %(data_age['Age'].describe()[0],data_age['Age'].describe()[1]))
# 不同性别的存活情况
data_sex=data_train[['Survived','Sex']]
data_sex=data_sex[data_sex['Sex'].notnull()]
plt.figure(figsize=(12,5))
data_sex.groupby(['Sex']).mean().plot.bar(rot=0)
survive_sex = data_sex.groupby(['Sex','Survived'])['Survived'].count()
print(survive_sex)
print('女性存活率为%.2f%%,男性存活率为%.2f%%' %(survive_sex.loc['female',1]/survive_sex.loc['female'].sum()*100, survive_sex.loc['male',1]/survive_sex.loc['male'].sum()*100))
# 老人和小孩的存活率情况
age_yo=data_age
age_yo['Age'][age_yo['Age']<1]=0
average_age = age_yo[["Age","Survived"]].groupby(['Age'],as_index=False).mean()
plt.figure(figsize=(20,4))
sns.barplot(x='Age',y='Survived',data=average_age, palette = 'BuPu')
plt.grid(linestyle = '--',alpha = 0.5)
绘图结果和分析结论
0.总体分布
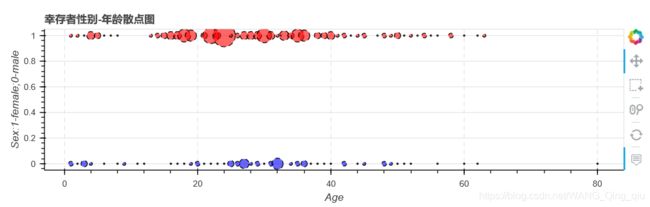 点的大小代表在这个年龄这个性别的获救者的数量的大小。
点的大小代表在这个年龄这个性别的获救者的数量的大小。
从图中整体可以看出,女性幸存者多余男性幸存者,青壮年幸存者多于少年和老年幸存者(这里没有考虑少年和老年人数可能占总人数的比例不高)。
1. 幸存者年龄数据分布情况:
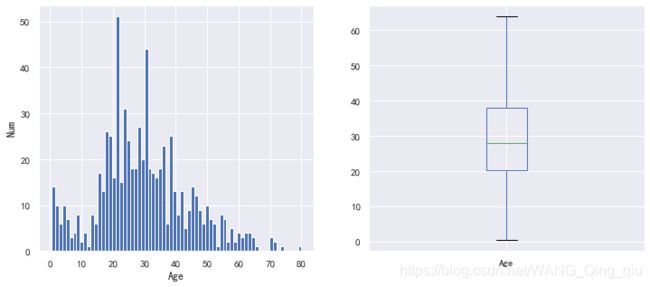
可以看出中年壮年的乘员较多,数据去除空值一共包含714人,平均年龄30岁。
2. 男性和女性存活情况:
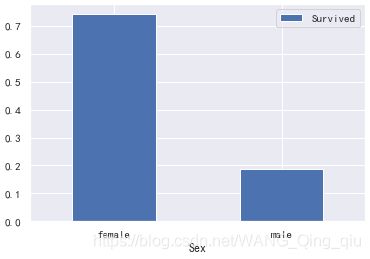
上图为女性和男性的存活率。总体统计数据:女性遇难81人,幸存233人;男性遇难469人,幸存109人;女性存活率为74.20%,男性存活率为18.89%
3. 老人和小孩的存活情况:

上图为不同年龄的存活率。由图可以看出,小孩的存活率整体较高,老人的存活率其次,壮年的再次,青年的存活率最低。灾难中,小孩和老人的幸存率较高。
题目3
结合 SibSp、Parch字段,研究亲人多少与存活的关系
要求:
① 有无兄弟姐妹/父母子女和存活与否的关系
② 亲戚多少与存活与否的关系
代码
# 有无兄弟姐妹/父母子女和存活与否的关系
# 提取数据
data3=data_train[['Survived','SibSp','Parch']]
# 筛选有无兄弟姐妹/配偶
sibsp_y=data3[data3['SibSp']!=0]
sibsp_n=data3[data3['SibSp']==0]
# 绘制有兄弟姐妹的遇难-幸存对比饼图
plt.figure(figsize=(12,3))
plt.subplot(141)
plt.axis('equal')
sibsp_y['Survived'].value_counts().plot.pie(labels=['遇难','幸存'],autopct='%1.1f%%',colormap='Blues')
plt.xlabel('乘客有兄弟姐妹的遇难-幸存比')
# 绘制没有兄弟姐妹的乘客的遇难-幸存对比饼图
plt.figure(figsize=(12,3))
plt.subplot(142)
plt.axis('equal')
sibsp_n['Survived'].value_counts().plot.pie(labels=['遇难','幸存'],autopct='%1.1f%%',colormap='Blues')
plt.xlabel('乘客没有兄弟姐妹的遇难-幸存比')
# 筛选有无父母子女
parch_y=data3[data3['Parch']!=0]
parch_n=data3[data3['Parch']==0]
# 绘制有父母子女和遇难/幸存的关系饼图
plt.figure(figsize=(12,3))
plt.subplot(143)
plt.axis('equal')
parch_y['Survived'].value_counts().plot.pie(labels=['遇难','幸存'],autopct='%1.1f%%',colormap='Reds')
# 绘制没有父母子女和遇难/幸存的关系饼图
plt.figure(figsize=(12,3))
plt.subplot(144)
plt.axis('equal')
parch_n['Survived'].value_counts().plot.pie(labels=['遇难','幸存'],autopct='%1.1f%%',colormap='Reds')
# 比较家庭大小与遇难/幸存的关系
data3['family_size']=data3['SibSp']+data3['Parch']+1
plt.subplots(figsize=(12,4))
average_per=data3[['family_size','Survived']].groupby(['family_size'],as_index=False).mean()
sns.barplot(x='family_size',y='Survived',data=average_per, color='blue',alpha=0.3)
plt.grid(linestyle = '--',alpha = 0.5)
绘图结果和分析结论
1. 有无兄弟姐妹或者配偶的幸存率的比较:
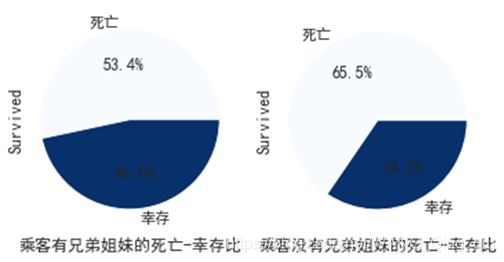
上图为有无兄弟姐妹或者配偶的遇难/幸存比率。有兄弟姐妹或者配偶的乘客存活概率大。
2. 有无父母子女的幸存率的比较:
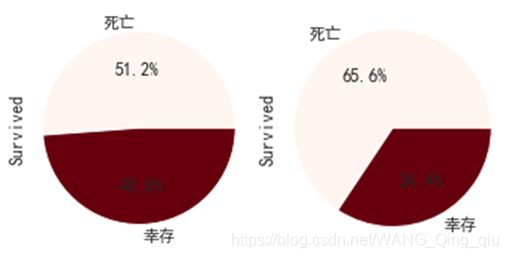
上图为有无父母子女的遇难/幸存比率,左侧为有父母子女,右侧为没有父母子女。有父母子女的乘客存活概率大。
3. 亲友数量和幸存率的关系:
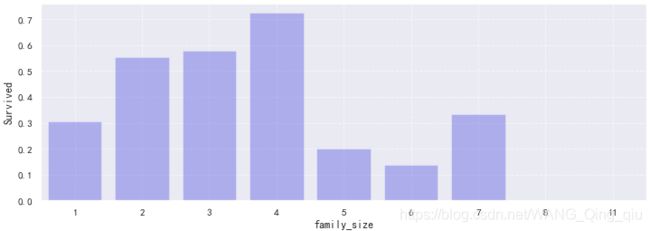
上图为家庭人数和幸存率的关系。当家庭人数为2个、3个和4个的时候幸存率较高,单独一个乘客或者家庭人数偏多幸存率偏低,当家庭人数数量超过7个存活率基本为0。
题目4
结合票的费用情况,研究票价和存活与否的关系
要求:
① 票价分布和存活与否的关系
② 比较研究生还者和未生还者的票价情况
代码
'''
4. 结合船票费用,研究票价和幸存/遇难的关系
'''
# 舱室情况和存活与否的关系
data4=data_train[['Survived','Fare','Pclass']]
plt.subplots(figsize=(12,4))
average_pclass=data4[['Pclass','Survived']].groupby(['Pclass'],as_index=False).mean()
sns.barplot(x='Pclass',y='Survived',data=average_pclass, color='blue',alpha=0.3)
plt.grid(linestyle = '--',alpha = 0.5)
# 票价分布和存活与否的关系
fig,ax=plt.subplots(1,2,figsize=(12,4))
data4['Fare'].hist(bins=50,ax=ax[0])
data4.boxplot(column='Fare',by='Pclass',showfliers=False,ax=ax[1])
# 绘制幸存者和遇难者的票价箱型图
data4.boxplot(column='Fare',by='Survived',showfliers=False)
# 分离幸存者和遇难者票价参数
sur_y=data4[data4['Survived']==1]
sur_n=data4[data4['Survived']==0]
# 计算幸存者会和遇难者的平均票价
sur_y['Fare'].describe()
sur_n['Fare'].describe()
print('幸存者的平均票价是:%.f\n遇难者的平均票价时:%.f' %(sur_y['Fare'].describe()[1],sur_n['Fare'].describe()[1]))
绘图结果和分析结论
1. 票价分布和是否幸存的关系:
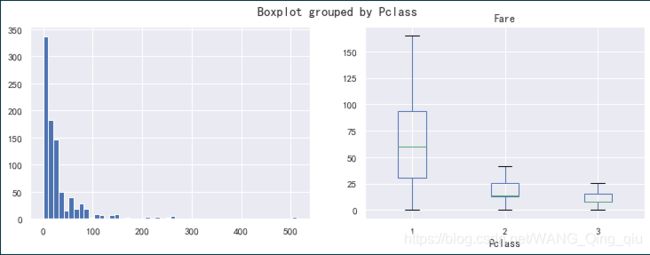
左侧图为票价分布直方图,右侧图为不同舱室票价分布的箱型图。从箱型图可以看出,随着舱室的等级提高,票价越高。
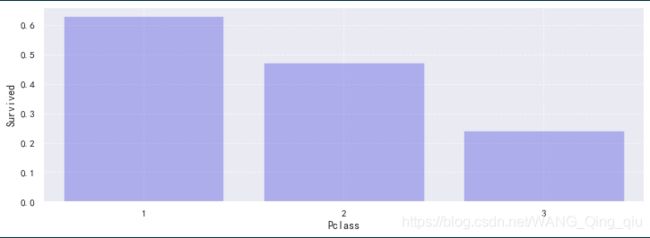
上图为幸存率和舱室的关系,舱室等级越高,幸存率越高。我们之前知道,舱室等级越高,票价越贵,这里得出结论,票价越高,幸存的概率越高。
2. 比较研究幸存者和遇难者的票价情况:
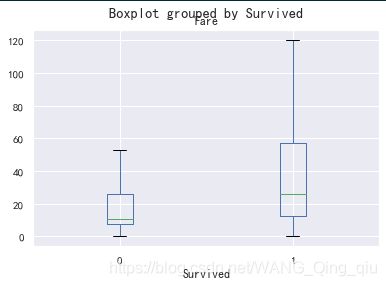
上图为遇难者和幸存者的票价比较箱型图,统计信息幸存者的平均票价是:48,遇难者的平均票价时:22。可以看出幸存者的平均票价要高于遇难者的票价。
题目5
利用KNN分类模型,对结果进行预测
要求:
① 模型训练字段:‘Survived’,‘Pclass’,‘Sex’,‘Age’,‘Fare’,‘Family_Size’
② 模型预测test.csv样本数据的生还率
提示:① 训练数据集中,性别改为数字表示 → 1代表男性,0代表女性
代码
'''
5.利用KNN分类模型归纳train.csv,对test.csv进行预测
'''
# 提出模型训练字段
data_train['sex_']=0
data_train['family_size']=data_train['SibSp']+data_train['Parch']+1
data_train['sex_'][data_train['Sex']=='female']=1
data_train['sex_'][data_train['Sex']=='male']=0
train=data_train[['Pclass','sex_','Age','Fare','family_size','Survived']]
train=train.dropna()
data_test['sex_']=0
data_test['family_size']=data_test['SibSp']+data_test['Parch']+1
data_test['sex_'][data_test['Sex']=='female']=1
data_test['sex_'][data_test['Sex']=='male']=0
test=data_test[['Pclass','sex_','Age','Fare','family_size']]
test=test.dropna()
# 导入KNN分类模块
from sklearn import neighbors
# 取得KNN分类器
knn=neighbors.KNeighborsClassifier()
# 加载数据,构建模型
knn.fit(train[['Pclass','sex_','Age','Fare','family_size']],train['Survived'])
test['Survived_pre']=knn.predict(test)
# 绘制幸存/死亡比例饼图
test['Survived_pre'].value_counts().plot.pie(autopct='%1.2f%%')
# 绘制预测性别-年龄-幸存人数散点图
test_pre=test[['Survived_pre','Age','sex_']]
test_pre.dropna(inplace=True)
test_pre=test_pre[test_pre['Survived_pre']==1]
# 绘制幸存者性别-年龄散点图,点的大小代表获救的人数
# 改变参数方便绘制散点图
test_pre['Age'][test_pre['Age']<1]=0
test_pre['size']=0
test_pre['size']=test_pre.groupby(['Age','sex_']).cumsum()
test_pre['size']=test_pre['size']*2
test_pre=test_pre.groupby(['Age','sex_']).max()
test_pre['mix']=test_pre.index
test_pre['mix']=test_pre['mix'].astype(str).str.replace('(','').str.replace(')','')
test_pre['age']=test_pre['mix'].str.split(',', expand=True)[0]
test_pre['sex']=test_pre['mix'].str.split(',', expand=True)[1]
test_pre['age']=test_pre['age'].drop(0)
test_pre.dropna(inplace=True)
# 提取散点图横纵坐标
test_pre['age']=test_pre['age'].astype(float)
test_pre['sex']=test_pre['sex'].astype(float)
# 设置男女不同颜色
test_pre['color']=test_pre['sex']
test_pre['color'][test_pre['color']==1]='red'
test_pre['color'][test_pre['color']==0]='blue'
# 绘制幸存者性别-年龄散点图,点的大小代表获救的人数的多少
# 创建ColumnDataSource数据
source = ColumnDataSource(test_pre)
hover = HoverTool(tooltips=[("幸存人数","@size"),("年龄","@age")])
# 构建绘图空间
s_a_pre= figure(plot_width=800,plot_height=250,
title="预测幸存者性别-年龄散点图",x_axis_label = 'Age',y_axis_label='Sex:1-female;0-male',
tools=[hover,'box_select,reset,xwheel_zoom,pan,crosshair'])
# 绘制散点图
s_a_pre.circle(x='age',y='sex',source=source,
line_color = 'black',line_dash = [6,4],fill_alpha = 0.6,
size = 'size',fill_color='color')
s_a_pre.title.text_font_style = "bold"
s_a_pre.xgrid.grid_line_dash = [6, 4]
show(s_a_pre)
print('###################完成######################')
预测模型的的生还率为38.07%
预测模型的验证
这里来验证test数据,为了和train数据作为对比,特别制作了幸存-遇难饼图和性别-年龄散点图(点的大小代表人数)来进行对比。

上图为train实际数据和test预测数据的幸存率饼图的对比。
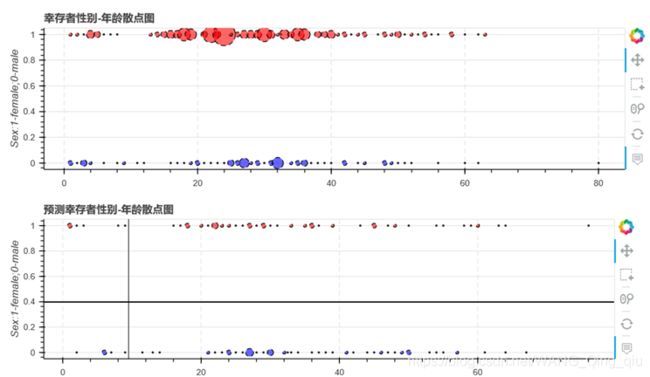
上图为train实际数据和test预测数据的散点图对比。
由以上两幅图可以看出,预测的模型比较贴合原本的模型。