利用mask-rcnn解决kaggle目标检测问题
mask-rcnn简介
mask-rcnn是Kaiming He大佬提出的图像分割模型,它在对图像中的目标进行检测的同时还能对每一个目标给出一个分割结果。它在Faster R-CNN[1]基础之上进行扩展,并行地在bounding box recognition分支上添加一个用于预测目标掩模(object mask)的新分支。该网络还很容易扩展到其他任务中,比如估计人的姿势,也就是关键点识别。该框架在COCO的一些列挑战任务重都取得了最好的结果,包括实例分割、候选框目标检测和人关键点检测。
原理部分我就不多做介绍,可以参考博客https://zhuanlan.zhihu.com/p/25954683,也可以去看mask-rcnn的原文,在这里我主要介绍一下mask-rcnn源码的使用方法。这里的mask-rcnn是keras版本的,要求安装好tensorflow,keras的GPU版本。
kaggle目标检测比赛
2018 Data Science Bowl比赛链接在此,我大概说一下这个比赛是要我们干什么的。比赛举办方会给我们600多张不同环境下多个细胞的图片和他们的细胞核位置,图示如下:
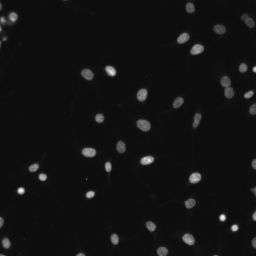
这是最简单的环境情况,背景是黑色的,而白色的那些东西就是细胞核,只不过有些暗一点,有些亮一点。而输出则是多张二维的2值图片,每张图上只有一个细胞核,图示如下:

这是其中一张,上面只有一个细胞核,图像只有0和1两种灰度值。参赛者所要做的事就是用训练数据训练一个模型,让该模型在测试图像上检测到细胞核,最终将细胞核的像素点位置输出到csv文件中提交。
样本扩充处理
刚刚提到了比赛举办方只给了我们600多张训练样本,这显然对于训练mask-rcnn网络是不够的,所以我们需要在原有的图像数据集上做变换来扩充样本。对于图像来说,常见的变换方法有旋转,平移,水平翻转,垂直翻转等,keras框架中的keras.preprocessing.image.ImageDataGenerator模块可以对图像做随机的变换操作,具体可见keras的文档说明。在这儿我给出一段进行图像基本变换的python代码,代码中只进行了水平/垂直翻转和90,180,270度的旋转变换,所以样本会扩充到原来的6倍。
代码块
import os
from PIL import Image
from copy import copy
def mkdir(path):
path=path.strip()
# 去除尾部 \ 符号
path=path.rstrip("\\")
isExists=os.path.exists(path)
if not isExists:
os.makedirs(path)
print(path+' 创建成功')
return True
else:
print(path+' 目录已存在')
return False
train_path = 'F://2018data//train//'#训练样本存放路径
Type = ['\\','lr\\','td\\','90\\','180\\','270\\']
train_ids = next(os.walk(train_path))[1]
for train_id in train_ids:
base_path = 'F:\\2018data\\newtrain\\'+train_id
for t in Type:
path = base_path + t
mkdir(path)
mkdir(path+'images\\')
mkdir(path+'masks\\')
TYPE = ['','lr','td','90','180','270']
train_path = 'F://2018data//train//'
new_path = 'F://2018data//newtrain//'
train_ids = next(os.walk(train_path))[1]
for i, id_ in enumerate(train_ids):
print(id_)
path = train_path + id_
new_image = []
image = path + '//images//' + id_ + '.png'
tmp_image = Image.open(image)
new_image.append(copy(tmp_image))
new_image.append(tmp_image.transpose(Image.FLIP_LEFT_RIGHT))
new_image.append(tmp_image.transpose(Image.FLIP_TOP_BOTTOM))
new_image.append(tmp_image.transpose(Image.ROTATE_90))
new_image.append(tmp_image.transpose(Image.ROTATE_180))
new_image.append(tmp_image.transpose(Image.ROTATE_270))
for (img,T) in zip(new_image,TYPE):
save_path = new_path + id_ + T + '//images//' + id_ + T + '.png'
img.save(save_path)
for mask_file in next(os.walk(path + '//masks//'))[2]:
mask_path = path + '//masks//' + mask_file
tmp_mask = Image.open(mask_path)
new_mask = []
new_mask.append(copy(tmp_mask))
new_mask.append(tmp_mask.transpose(Image.FLIP_LEFT_RIGHT))
new_mask.append(tmp_mask.transpose(Image.FLIP_TOP_BOTTOM))
new_mask.append(tmp_mask.transpose(Image.ROTATE_90))
new_mask.append(tmp_mask.transpose(Image.ROTATE_180))
new_mask.append(tmp_mask.transpose(Image.ROTATE_270))
for(ms,T) in zip(new_mask,TYPE):
save_path = new_path + id_ + T + '//masks//' + mask_file[:-4] + T + '.png'
ms.save(save_path)
mask-rcnn源码使用
博客开头给出了mask-rcnn的github链接,github上面其实有对它的使用方法做一些介绍,但博主在使用过程中还是遇上了一些坑,所以写了这个博客进行记录,如果能对其他人有点帮助也是好事。下载下来后有几个py文件需要浏览一下:

第一个方框圈起来的h5文件是mask-rcnn在coco数据集上训练好的模型,我们的模型训练就是用这个文件进行的参数初始化,如果你下载下来的源码没有这个文件可以单独搜一下下载下来。第二个文件是有关模型参数的设置的,里面有这么一个类:

其中最基本的参数有:
GPU_COUNT = 1#你打算用多少块GPU
IMAGES_PER_GPU = 2#一块12G的GPU最多能同时处理2张1024*1024的图像
STEPS_PER_EPOCH = 1000#一个epoch的迭代步数
NUM_CLASSES = 1#目标类别=1(背景)+object_class,如果我只打算检测细胞核,那就设置为2
IMAGE_MIN_DIM = 800#样本图像的最小边长,设置的不对会导致训练出错
IMAGE_MAX_DIM = 1024#样本图像的最大边长,同上
USE_MINI_MASK = True#是否压缩目标图像
MINI_MASK_SHAPE = (56, 56)#目标图像的压缩大小 需要注意的是,mask-rcnn训练的batch_size=IMAGES_PER_GPU*GPU_COUNT ,这个是比较僵硬的地方,意味着我没有那么多GPU的时候batch_size只能往小了设置;还有IMAGE_MIN_DIM 和IMAGE_MAX_DIM 这两个参数是不能默认的,一旦你传入的图像不在这个范围里面训练出的模型是有问题的,这也是我碰到的最坑的地方,训练不会报错但得到的模型是不能用的;还有USE_MINI_MASK 这个参数,当你的mask图像中目标很小时要把这个参数设置为False,假设目标就4,5个像素点,然后被你一压缩就没了,那训练不就出问题了么。
以上是必须要关注的参数,其他参数可能会影响训练出的模型性能,但上面的参数设置的不好直接导致训练的模型不能用。对模型性能有直接影响的参数应该是STEPS_PER_EPOCH ,epoch的数量和batch_size的大小。其他的参数暂时没有详细研究,后面研究过了会再来补充更新。
下面说一下第三个文件util.py,这个文件中有这么一个类是做样本接口的,使用的时候需要我们去实现这个接口,下面就来介绍一下:

这个类里面有三个函数需要我们重写:load_image,load_mask和image_reference,load_image的作用是返回对应id的image,load_mask的作用是返回对应id的mask,image_reference的作用是返回对应id的图像shapes信息。图像id并没有什么特殊要求,你传进去后按顺序1,2,3,…编号作为id就行。所以为了方便,我们可以在外部先把image和mask规格化成相同大小,按顺序放到一个list里面传进接口类中。那这几个函数重写起来就很方便了。
模型测试结果
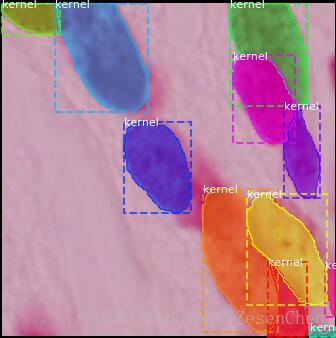
比赛已经结束,stage1的排名能拿到银牌,stage2时因为大量参赛者放弃提交导致最后有牌子的人只有100个,最后笔者排名190多名,top6%。
最后附上拖了很久的github链接: https://github.com/ZesenChen/mask-rcnn-kaggle-version-