源码分析mycat1.6之网络篇---前端线程模型下篇(读写事件篇)
1、mycat 前端读事件处理
程序的入口处:NIOReactor的run方法:

直接调用的方法为AbstractConnection的aysnRead方法。

NIOSocketWR,IO处理的核心入口:
@Override
public void asynRead() throws IOException {
ByteBuffer theBuffer = con.readBuffer; //@1
if (theBuffer == null) { //@2
theBuffer = con.processor.getBufferPool().allocate(con.processor.getBufferPool().getChunkSize());
con.readBuffer = theBuffer;
}
int got = channel.read(theBuffer); //@3
con.onReadData(got); //@4
}代码@1,首先,一个Connection与一个SocketWR一对一。首先获取该连接的reader buffer。
代码@2,如果reader buffer为空,则像内存池中申请一块内存(内存的具体分配,将在后文的内存篇重点讲解)。
代码@3,从SocketChannel中读取数据到 readerBuffer中。
代码@4,主要是对读入的数据进行处理。具体代码见AbstractConnection的onReadData。
/**
* 读取可能的Socket字节流
*/
public void onReadData(int got) throws IOException { //@1
if (isClosed.get()) {
return;
}
lastReadTime = TimeUtil.currentTimeMillis();
if (got < 0) {
this.close("stream closed");
return;
} else if (got == 0
&& !this.channel.isOpen()) {
this.close("socket closed");
return;
} // @2
netInBytes += got;
processor.addNetInBytes(got); //@3
// 循环处理字节信息
int offset = readBufferOffset, length = 0, position = readBuffer.position(); // @4
for (;;) {
length = getPacketLength(readBuffer, offset); //@5
if (length == -1) { //@6
if (offset != 0) {
this.readBuffer = compactReadBuffer(readBuffer, offset);
} else if (readBuffer != null && !readBuffer.hasRemaining()) {
throw new RuntimeException( "invalid readbuffer capacity ,too little buffer size "
+ readBuffer.capacity());
}
break;
}
if (position >= offset + length && readBuffer != null) { // @7
// handle this package
readBuffer.position(offset);
byte[] data = new byte[length];
readBuffer.get(data, 0, length);
handle(data); // @8
// maybe handle stmt_close
if(isClosed()) { // @9
return ;
}
// offset to next position
offset += length;
// reached end
if (position == offset) { // @10
// if cur buffer is temper none direct byte buffer and not
// received large message in recent 30 seconds
// then change to direct buffer for performance
if (readBuffer != null && !readBuffer.isDirect()
&& lastLargeMessageTime < lastReadTime - 30 * 1000L) { // used temp heap
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("change to direct con read buffer ,cur temp buf size :" + readBuffer.capacity());
}
recycle(readBuffer);
readBuffer = processor.getBufferPool().allocate(processor.getBufferPool().getConReadBuferChunk());
} else {
if (readBuffer != null) {
readBuffer.clear();
}
}
// no more data ,break
readBufferOffset = 0;
break;
} else { // @11
// try next package parse
readBufferOffset = offset;
if(readBuffer != null) {
readBuffer.position(position);
}
continue;
}
} else { // @12
// not read whole message package ,so check if buffer enough and
// compact readbuffer
if (!readBuffer.hasRemaining()) {
readBuffer = ensureFreeSpaceOfReadBuffer(readBuffer, offset, length);
}
break;
}
}
}首先,mycat处理读事件的接收缓存区为readBuffer,每个Connection只有一个。接下来,主要的思路是如果接收缓存区中包含一个完整的数据包,则对数据包进行处理,如果没有,确保接收缓存区能够容纳一个包的大小,然后等更多数据到达。整体浏览了该方法的实现,有些异议,本文先按照作者的思路进行分析,然后提出自己的优化建议供大家交流讨论。
代码@1,参数got,就是本次SocketChannel读入的字节数据。
代码@2,如果读取的数据为-1,或为0,并且通道已经关闭了,直接返回。
代码@3,NIOProcessor的 netInBytes 主要是用来统计信息的。
代码@4,offset,上次读到readerBuffer的偏移量。length,当前mysql请求包的数据长度(包括协议头),position,readerBuf当前可写,可读的位置,当前的reader ByteBuffer处于可写状态。
代码@5,开始循环解析数据包。从当前reader buffer中获取数据包的长度。
protected int getPacketLength(ByteBuffer buffer, int offset) {
int headerSize = getPacketHeaderSize();
if ( isSupportCompress() ) {
headerSize = 7;
} //@51
if (buffer.position() < offset + headerSize) { // @52
return -1;
} else { // @53
int length = buffer.get(offset) & 0xff;
length |= (buffer.get(++offset) & 0xff) << 8;
length |= (buffer.get(++offset) & 0xff) << 16;
return length + headerSize;
}
}代码@51,首先mysql协议包长度,如果没有启用压缩,协议头部长度固定为4字节,如果启用了压缩,则为7个字节。
代码@52,判断该readerBuffer中数据是否有一个完整的数据包头部,当前position为第一个可写的位置,readerBuffer中第一个有效数据为offset。如果不够一个完整的数据包,则返回-1。
代码@53,读取头部的前3个字节,表示数据包(报文体)的长度,由于使用了小端序列。然后返回加上头部长度,得出数据包的最终长度。
代码@6,如果readerBuffer中没有包含一个完整的数据包,并且offset不为0,则压缩该read buffer,节省空间。
代码@7、@8,如果该readerBuf中包含一个完整的mysql数据包。准备从readerbuf中读取一个完整的数据包,这里没有使用flip方法,而是手动改变position的值。
首先设置position的值为offset,然后在堆里创建一个与待解析数据包相同大小的byte[],然后就数据读入到该数组中。在这里我觉得这样做不妥,既然是用的堆外内存,在处理数的时候,为什么需要将数据从堆外内存拷贝到堆内呢?关于优化点先放到文章的末尾。然后将一个完整的数据包交给NIOHandler进行处理。
代码@9,处理完一个完整的数据包后,再次检查连接是否已经关闭。
代码@10,如果ReaderBuffer读取完毕,进行一次优化,如果使用的Reader ByteBuffer是一个堆内Buffer,则使用直接内存进行替换。
代码@11,尝试继续解析下一个数据包。
代码@12,如果readBuffer中不包含一个完整的数据包,则判断是否需要扩容当前的ByteBuffer,如果需要,则扩容,否则结束本次读任务,等待更多数据到达。
onReadData中,每解析一个数据包,将转发给NIOHandler进行处理(单线程中)。
压缩readBuffer的实现:
private ByteBuffer compactReadBuffer(ByteBuffer buffer, int offset) {
if(buffer == null) {
return null;
}
buffer.limit(buffer.position());
buffer.position(offset);
buffer = buffer.compact();
readBufferOffset = 0;
return buffer;
}readBuf扩容的实现:
private ByteBuffer ensureFreeSpaceOfReadBuffer(ByteBuffer buffer,
int offset, final int pkgLength) {
// need a large buffer to hold the package
if (pkgLength > maxPacketSize) {
throw new IllegalArgumentException("Packet size over the limit.");
} else if (buffer.capacity() < pkgLength) {
ByteBuffer newBuffer = processor.getBufferPool().allocate(pkgLength);
lastLargeMessageTime = TimeUtil.currentTimeMillis();
buffer.position(offset);
newBuffer.put(buffer);
readBuffer = newBuffer;
recycle(buffer);
readBufferOffset = 0;
return newBuffer;
} else {
if (offset != 0) {
// compact bytebuffer only
return compactReadBuffer(buffer, offset);
} else {
throw new RuntimeException(" not enough space");
}
}
}至此,mycat读事件的解决就分析到这里了,提出如下4个性能优化点:
性能优化点:
1、首先 该类的 readBufferOffset 属性其实完成可以不需要,依然能够合理的解析出数据包。readBufferOffset是voliate类型的字段,有一定的性能损坏。
2、第二个重点,在解析数据包的时候:
if (position >= offset + length && readBuffer != null) {
// handle this package
readBuffer.position(offset);
byte[] data = new byte[length];
readBuffer.get(data, 0, length);
handle(data);
// 其他代码省略readBuffer是 堆外内存,现在在处理数据的时候,又从堆外内存,拷贝一次到堆内存(byte[]),这里多了一本从堆内存拷贝到堆内存的步骤,抵消了直接内存的优势;是否可 以实现一个从ReadBuffer slice(int startIndex, int posistion),使用readerBuffer的内存,但用SliceByteBuffer进行后面的数据包解析等等。
这样的理解是否合理。
3、当Reader Buffer中没有一个足够的mysql数据包时,此时的扩容条件,可以进一步优化为
if (!readBuffer.hasRemaining() || (readBuffer.limit - offset + 1 ) < length ) {
readBuffer = ensureFreeSpaceOfReadBuffer(readBuffer, offset, length);
// readBuffer.limit - offset + 1 表示readBuffer可以写入的总长度,如果可以写入的总长度小于数据包的长度,则需要扩容
}4、readBuffer只有扩容,没有容量压缩,这里不同于上面compactReadBuffer的实现。举个例子,默认readBuffer的容量为4K,突然一个数据包,用了16M,,但以后每个包的容量又只需要4K,但该连接的readBuffer始终占有16M的空间,导致内存空间的浪费。
2、mycat前端写事件处理
入口:
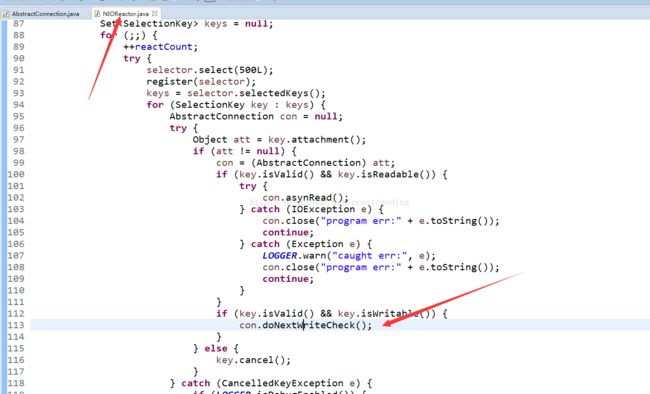
AbstractConnection的doNextWriteCheck()
public void doNextWriteCheck() throws IOException {
this.socketWR.doNextWriteCheck();
}在讲解写事件之前,我们不妨再看看NIOSocketWR的相关属性,我们从前文已经知道NIOSocketWR与AbstractConnection一一对应。NIOSocketWR是负责Connection网络的读写。
private SelectionKey processKey;
private static final int OP_NOT_READ = ~SelectionKey.OP_READ;
private static final int OP_NOT_WRITE = ~SelectionKey.OP_WRITE;
private final AbstractConnection con;
private final SocketChannel channel;
private final AtomicBoolean writing = new AtomicBoolean(false); //@1通道是否正在处理写事件,默认为false。接下来重点关注doNextWrite
public void doNextWriteCheck() {
if (!writing.compareAndSet(false, true)) { // @1
return;
}
try {
boolean noMoreData = write0(); //@2
writing.set(false);
if (noMoreData && con.writeQueue.isEmpty()) { //@3
if ((processKey.isValid() && (processKey.interestOps() & SelectionKey.OP_WRITE) != 0)) {
disableWrite();
}
} else { // @4
if ((processKey.isValid() && (processKey.interestOps() & SelectionKey.OP_WRITE) == 0)) {
enableWrite(false);
}
}
} catch (IOException e) {
if (AbstractConnection.LOGGER.isDebugEnabled()) {
AbstractConnection.LOGGER.debug("caught err:", e);
}
con.close("err:" + e);
}
}代码@1,如果有写操作正在进行,则直接退出。
代码@2,具体的通道写,稍后查看。
代码@3,如果没有数据待写,并且写任务队列为空,并且关注了写事件,则取消写事件。noMoreData为true,表示没有更多数据。
代码@4,如果有更多数据待写,并且没有关注写事件,重新关注写事件。
接下来重点关注写操作的具体执行逻辑:
private boolean write0() throws IOException {
int written = 0;
ByteBuffer buffer = con.writeBuffer;
if (buffer != null) { //@1
while (buffer.hasRemaining()) {
written = channel.write(buffer);
if (written > 0) {
con.netOutBytes += written;
con.processor.addNetOutBytes(written);
con.lastWriteTime = TimeUtil.currentTimeMillis();
} else {
break;
}
}
if (buffer.hasRemaining()) {
con.writeAttempts++;
return false;
} else {
con.writeBuffer = null;
con.recycle(buffer);
}
}
while ((buffer = con.writeQueue.poll()) != null) { //@2
if (buffer.limit() == 0) {
con.recycle(buffer);
con.close("quit send");
return true;
}
buffer.flip();
try {
while (buffer.hasRemaining()) {
written = channel.write(buffer);// java.io.IOException:
// Connection reset by peer
if (written > 0) {
con.lastWriteTime = TimeUtil.currentTimeMillis();
con.netOutBytes += written;
con.processor.addNetOutBytes(written);
con.lastWriteTime = TimeUtil.currentTimeMillis();
} else {
break;
}
}
} catch (IOException e) {
con.recycle(buffer);
throw e;
}
if (buffer.hasRemaining()) {
con.writeBuffer = buffer;
con.writeAttempts++;
return false;
} else {
con.recycle(buffer);
}
}
return true;
}经典的写处理操作,while( buffer.hasRemaining()),在循环中,调用通道的write方法,然后判断写入的字节数,如果大于0,则继续写,否则跳出,然后再次检测待写缓存区是否有剩余空间,如果没有,则回收该ByteBuffer,如果没有,待下次继续写入(直接结束本次写入操作)。如果成功将AbstractConnection的writeBuffer写入后,继续处理写任务队列中的ByteBuffer,如果全部写完,则返回true,表示没有更多数据,否则返回false。写事件的处理就分析到到,既然有任务缓存区,我们肯定也要关注一下,缓存区中的待写ByteBuffer是从哪来的。关注一下AbstractConnection:
protected volatile ByteBuffer writeBuffer;
protected final ConcurrentLinkedQueue writeQueue = new ConcurrentLinkedQueue();//写任务队列
private final void writeNotSend(ByteBuffer buffer) { // 放入写任务队列,但不立即写出
if (isSupportCompress()) {
ByteBuffer newBuffer = CompressUtil.compressMysqlPacket(buffer, this, compressUnfinishedDataQueue);
writeQueue.offer(newBuffer);
} else {
writeQueue.offer(buffer);
}
}
//该方法先将写任务放入到写任务队列中,然后触发一次写操作,doNextWriteCheck 支持重入不产生副作用。
@Override
public final void write(ByteBuffer buffer) {
if (isSupportCompress()) {
ByteBuffer newBuffer = CompressUtil.compressMysqlPacket(buffer, this, compressUnfinishedDataQueue);
writeQueue.offer(newBuffer);
} else {
writeQueue.offer(buffer);
}
// if ansyn write finishe event got lock before me ,then writing
// flag is set false but not start a write request
// so we check again
try {
this.socketWR.doNextWriteCheck();
} catch (Exception e) {
LOGGER.warn("write err:", e);
this.close("write err:" + e);
}
}
public ByteBuffer checkWriteBuffer(ByteBuffer buffer, int capacity, boolean writeSocketIfFull) { // @1
if (capacity > buffer.remaining()) { //@2
if (writeSocketIfFull) {
writeNotSend(buffer);
return processor.getBufferPool().allocate(capacity);
} else {// Relocate a larger buffer //@3
buffer.flip();
ByteBuffer newBuf = processor.getBufferPool().allocate(capacity + buffer.limit() + 1);
newBuf.put(buffer);
this.recycle(buffer);
return newBuf;
}
} else {
return buffer;
}
} 代码@1,首先checkWriteBuffer的调用者,一般都是mysql协议包,比如RowDataPacket。buffer,待写入的缓存区,capacity,需要继续往缓存区buffer写入的字节数,writeSocketIfFull,如果buffer无法容纳待写入的字节数,是创建一个新的,还是扩容。
代码@2,如果待写入字节数大于ByteBuffer可以容纳空间,此时要么重新分配一个新的,将原先的直接放入到任务队列中,要么采取扩容。这两种方式都有优劣
如果直接放入到任务队列,重新按容量创建一个,可能会浪费一部分内存,但扩容,会涉及数据的移动,损耗性能。综合来说,个人还是倾向于第一种,重新分配一个新的,然后将原先的ByteBuffer丢入到写任务队列中。
附上checkWriteBuffer的调用示例(io.mycat.net.mysql.RowDataPacket):
@Override
public ByteBuffer write(ByteBuffer bb, FrontendConnection c,
boolean writeSocketIfFull) {
bb = c.checkWriteBuffer(bb, c.getPacketHeaderSize(), writeSocketIfFull);
BufferUtil.writeUB3(bb, calcPacketSize());
bb.put(packetId);
for (int i = 0; i < fieldCount; i++) {
byte[] fv = fieldValues.get(i);
if (fv == null ) {
bb = c.checkWriteBuffer(bb, 1, writeSocketIfFull);
bb.put(RowDataPacket.NULL_MARK);
}else if (fv.length == 0) {
bb = c.checkWriteBuffer(bb, 1, writeSocketIfFull);
bb.put(RowDataPacket.EMPTY_MARK);
}
else {
bb = c.checkWriteBuffer(bb, BufferUtil.getLength(fv),
writeSocketIfFull);
BufferUtil.writeLength(bb, fv.length);
bb = c.writeToBuffer(fv, bb);
}
}
return bb;
}本文源码分析mycat读写事件的处理逻辑,特别对mycat在处理读事件的一些改进想法(备注,改进实现在两周内提交到github库);同时剖析了mycat写缓存的实现原理。待分析问题:mycat前后端连接是如何交互的。
欢迎加笔者微信号(dingwpmz),加群探讨,笔者优质专栏目录:
1、源码分析RocketMQ专栏(40篇+)
2、源码分析Sentinel专栏(12篇+)
3、源码分析Dubbo专栏(28篇+)
4、源码分析Mybatis专栏
5、源码分析Netty专栏(18篇+)
6、源码分析JUC专栏
7、源码分析Elasticjob专栏
8、Elasticsearch专栏
9、源码分析Mycat专栏