Fast R-CNN关键点自总
目录
网络结构
宏观概括
训练过程时的网络结构
对应代码
检测过程时的网络结构
Fast R CNN里面用到的损失函数
smoothl1 loss
网络结构
宏观概括
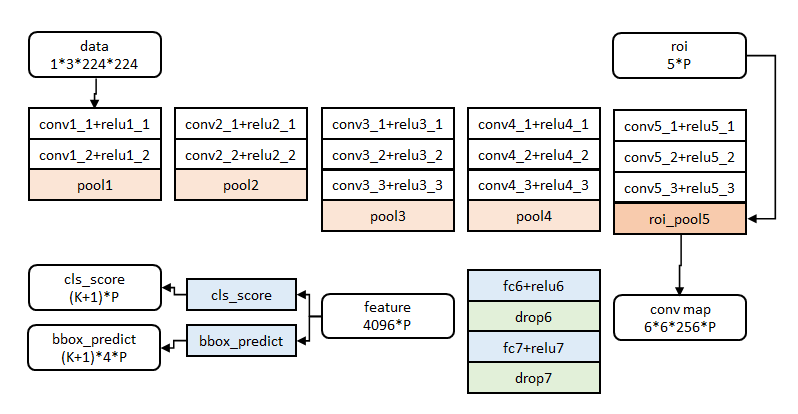
这个图很牛逼,也很关键,其他的常规的地方,就不说了,只记录我自己觉得最最让我费解的点,就算P对应的是什么意思,很容易发现,从roi_pool5后,每个数据之后都带上了一个“*P”,那这个代表的是什么含义呢?先说答案,P代表的是候选区域的个数。
Fast rcnn出名的地方在于它提出了ROI Pooling的概念,那ROI的输入(根据输入image,将提前划定画定好的ROI区域映射到feature map对应位置)是包含两个部分:
(1). 特征图:指的是图1中所示的特征图,在Fast RCNN中,它位于RoI Pooling之前,(在Faster RCNN中,它是与RPN共享那个特征图,通常我们常常称之为“share_conv”;)
(2). rois:在Fast RCNN中,指的是Selective Search的输出;(在Faster RCNN中指的是RPN的输出,一堆矩形候选框框,形状为1x5x1x1(4个坐标+索引index)),其中值得注意的是:坐标的参考系不是针对feature map这张图的,而是针对原图的(神经网络最开始的输入)
那么问题来了,提前划定好的ROI输入区域是唯一的吗?显然不是,那是几个呢?就是P个!,所以,相当于进行ROI Pooling操作的时候,是输入进去了P张图进行的,每张图处理完后生成一个6*6*256固定大小的特征图组,那么P张图不就是6*6*256*P嘛!而且,重要的是,从这步开始,之后的所以步骤,所生成的张量都是P个。
PS;那这个P是怎么来的呢?这就是一个鸡生蛋蛋生鸡的关系了,如果要做目标检测肯定是要把真值位置框提前标定处理,作为已知输入来进行的,那问题又来了,那么多的训练数据集,我总不能雇好多人手工标注吧,那太麻烦了,所以,Fast Rcnn 的作者在解决这个问题的时候,提出来了一个Selective Search算法,这个算法大概就是说同捕捉多个初始区域(RCNN同样借鉴了如此的过程),然后,计算这几个初始区域的相似性,将相似性高的合并在一起,一直这样重复,直至找到唯一的一张框,或者覆盖同一个目标物的多个框(P个),这么多框的信息就作为一个ROI输入区域来进行输入了。为什么说是鸡生蛋蛋生鸡呢?因为如果准的话,框都已经把幕布物给框出来了,那还合并训练网络来检测呢?
再问个问题,那selective search这个是相当于是训练之前提前的预处理吗?是先找到了,然后,存起来,训练网络的时候再导进去吗?不是的,如果这么干,那test的过程中,就必须输入一个预先ROI区域了,但这样做就太低端了。真正的做法是,selective search是在输入图片后自动去找的,大约在图像中提取2k个左右的候选框;再将这些框(经过筛选后,具体的策略是:选择P=128个候选框,这其中,与某个真值重叠在[0.5,1]的候选框占25%作为前景图片;与真值重叠的最大值在[0.1,0.5)的候选框占75%作为i背景图片)作为ROI的候选区域,进行输入训练。 训练的时候得有正有负啊,总不能全为正吧,严格来说正例子才是P个
详细介绍见:https://zhuanlan.zhihu.com/p/39927488
这个P的重要性主要体现在后面的NMS的过程当中。
训练过程时的网络结构
Part1: 输入是224*224
Part2: 经过5个卷积层和2个降采样层(这两个降采样层分别跟在第一和第二个卷积层后面)后
Part3: 进入ROIPooling层,该层是输入是conv5层的输出和region proposal,region proposal的个数差不多2000。
Part4: 然后再经过两个都是output是4096的全连接层。
Part5: 最后分别经过output个数是21和84的两个全连接层(这两个全连接层是并列的,不是前后关系),前者是分类的输出,代表每个region proposal属于每个类别(21类)的得分,后者是回归的输出,代表每个region proposal的四个坐标。最后是两个损失层,分类的是softmaxWithLoss,输入是label和分类层输出的得分;回归的是SmoothL1Loss,输入是回归层的输出和target坐标及weight。
对应代码
def build_network(self, images, class_num, is_training=True, keep_prob=0.5, scope='Fast-RCNN'):
#导入的images的尺寸是224*224,主网络(5个卷积和2个pooling)采用的是VGG16。
self.conv1 = self.convLayer(images, 11, 11, 4, 4, 96, "conv1", "VALID")
lrn1 = self.LRN(self.conv1, 2, 2e-05, 0.75, "norm1")
self.pool1 = self.maxPoolLayer(lrn1, 3, 3, 2, 2, "pool1", "VALID")
self.conv2 = self.convLayer(self.pool1, 5, 5, 1, 1, 256, "conv2", groups=2)
lrn2 = self.LRN(self.conv2, 2, 2e-05, 0.75, "lrn2")
self.pool2 = self.maxPoolLayer(lrn2, 3, 3, 2, 2, "pool2", "VALID")
self.conv3 = self.convLayer(self.pool2, 3, 3, 1, 1, 384, "conv3")
self.conv4 = self.convLayer(self.conv3, 3, 3, 1, 1, 384, "conv4", groups=2)
self.conv5 = self.convLayer(self.conv4, 3, 3, 1, 1, 256, "conv5", groups=2)
#进入到ROI层
self.roi_pool6 = roi_pooling(self.conv5, self.rois, pool_height=6, pool_width=6)
#从ROI层出来后,接着过两个全连接网络就可以了,每个全连接后面接着一个drop层
with slim.arg_scope([slim.fully_connected, slim.conv2d],
activation_fn=nn_ops.relu,
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01),
weights_regularizer=slim.l2_regularizer(0.0005)):
flatten = slim.flatten(self.roi_pool6, scope='flat_32')
self.fc1 = slim.fully_connected(flatten, 4096, scope='fc_6')
drop6 = slim.dropout(self.fc1, keep_prob=keep_prob, is_training=is_training, scope='dropout6',)
self.fc2 = slim.fully_connected(drop6, 4096, scope='fc_7')
drop7 = slim.dropout(self.fc2, keep_prob=keep_prob, is_training=is_training, scope='dropout7')
#最后,的分类和回归都是从最后一层的全连接层分出来的。
cls = slim.fully_connected(drop7, class_num,activation_fn=nn_ops.softmax ,scope='fc_8')
bbox = slim.fully_connected(drop7, (self.class_num-1)*4,
weights_initializer=tf.truncated_normal_initializer(0.0, 0.001),
activation_fn=None ,scope='fc_9')
return cls,bbox检测过程时的网络结构
与训练基本相同,最后两个loss层要改成一个softmax层,输入是分类的score,输出概率。最后对每个类别采用NMS(non-maximun suppression)。这个的过程,我其实有点懵,下面自己捋一下。
首先,根据训练的时候的网络结构,先得到分类(results)和边框(bbox_)的预测:
images, roises, labels = self.data.get_valid_batch(test_index)
feed_dict = {self.net.images: images, self.net.rois: roises}
results, bbox_ = self.sess.run([self.net.logits, self.net.bbox], feed_dict=feed_dict)
for index in range(len(results)):
if (np.argmax(results[index][0:class_num])) != 0 and np.max(results[index][0:class_num] > 0.5):
rois = roises[index][1:5] * 16
regions_old = [(rois[0] + rois[2]) / 2.0, (rois[1] + rois[3]) / 2.0, rois[2] - rois[0],
rois[3] - rois[1]]
ind = np.argmax(results[index]) - 1
score = np.max(results[index][0:5])
x_rate, y_rate, w_rate, h_rate = bbox_[index][ind * 4], bbox_[index][ind * 4 + 1], \
bbox_[index][ind * 4 + 2], bbox_[index][ind * 4 + 3]
region_new = [regions_old[0] + regions_old[2] * x_rate, regions_old[1] + regions_old[3] * y_rate,
regions_old[2] * np.exp(w_rate), regions_old[3] * np.exp(h_rate)]
results_dic[ind + 1].append(
[results[index][ind + 1], region_new[0] - region_new[2] / 2.0, region_new[1] - region_new[3] / 2.0,
region_new[0] + region_new[2] / 2.0, region_new[1] + region_new[3] / 2.0])
regions.append([region_new[0] - region_new[2] / 2.0, region_new[1] - region_new[3] / 2.0, region_new[2],
region_new[3], ind + 1, score])最后生成到一个results_dic里面,第一个值是分类信息,对应下面P组值(x,y,w,h),表示对某个类别的对应的所有预测框的组数。
如果正常的话,应该是21*P个分类和84*P个回归框(21*4,每个类别对应一个框,一个框有四个值(x,y,w,h))的张量大小,那么预测的时候,将这两个进行合并成一个五维的张量组,(类别,x,y,w,h)共P个,接下来就要从这P组值里面可能都检测到了目标物,但想筛选出一个最好的框,这就需要NMS的过程了。
将result_dic里面所有的类别判分,从大到小排一下,最大的那个作为初始比较的值,然后,将剩下的框值从大到小开始和初始值进行比较,如果重叠率大于提前设定的阈值,就把这个比较的值给排除出去。如此循环过后,就只剩下了最大的框值。
def NMS_IOU(self, vertice1, vertice2): # verticle:[pro,xin,ymin,xmax,ymax]
lu = np.maximum(vertice1[1:3], vertice2[1:3])
rd = np.minimum(vertice1[3:], vertice2[3:])
intersection = np.maximum(0.0, rd - lu)
inter_square = intersection[0] * intersection[1]
square1 = (vertice1[3] - vertice1[1]) * (vertice1[4] - vertice1[2])
square2 = (vertice2[3] - vertice2[1]) * (vertice2[4] - vertice2[2])
union_square = np.maximum(square1 + square2 - inter_square, 1e-10)
return np.clip(inter_square / union_square, 0.0, 1.0)
def NMS(self, result_dic):
final_result = []
for cls_ind, cls_collect in result_dic.items():
cls_collect = sorted(cls_collect, reverse=True)
for i in range(len(cls_collect) - 1):
for j in range(len(cls_collect) - 1, i, -1):
if self.NMS_IOU(cls_collect[i], cls_collect[j]) > cfg.NMS_threshold:
del cls_collect[j]
for each_result in cls_collect:
final_result.append(
[each_result[1], each_result[2], each_result[3] - each_result[1], each_result[4] - each_result[2],
cls_ind, each_result[0]])
return final_result
def NMS_average(self, result_dic):
final_result = []
for cls_ind, cls_collect in result_dic.items():
cls_collect = sorted(cls_collect, reverse=True)
for i in range(len(cls_collect) - 1):
for j in range(len(cls_collect) - 1, i, -1):
if self.NMS_IOU(cls_collect[i], cls_collect[j]) > cfg.NMS_threshold:
cls_collect[i] = [(x + y) / 2.0 for (x, y) in zip(cls_collect[i], cls_collect[j])]
del cls_collect[j]
for each_result in cls_collect:
final_result.append(
[each_result[1], each_result[2], each_result[3] - each_result[1], each_result[4] - each_result[2],
cls_ind, each_result[0]])
return final_result
完整代码
def predict(self):
class_num = cfg.Class_num
image_path = cfg.Images_path
with open(r'./Data/test_list.txt','r') as f:
test_index_collect = f.readlines()
for test_index in test_index_collect:
test_index = test_index.strip()
regions = []
results_dic = {}
for cls_index in range(1, class_num+1):
results_dic[cls_index] = []
images, roises, labels = self.data.get_valid_batch(test_index)
feed_dict = {self.net.images: images, self.net.rois: roises}
results, bbox_ = self.sess.run([self.net.logits, self.net.bbox], feed_dict=feed_dict)
print('********************************************')
for index in range(len(results)):
if (np.argmax(results[index][0:class_num])) != 0 and np.max(results[index][0:class_num] > 0.5):
rois = roises[index][1:5] * 16
regions_old = [(rois[0] + rois[2]) / 2.0, (rois[1] + rois[3]) / 2.0, rois[2] - rois[0],
rois[3] - rois[1]]
ind = np.argmax(results[index]) - 1
score = np.max(results[index][0:5])
x_rate, y_rate, w_rate, h_rate = bbox_[index][ind * 4], bbox_[index][ind * 4 + 1], \
bbox_[index][ind * 4 + 2], bbox_[index][ind * 4 + 3]
region_new = [regions_old[0] + regions_old[2] * x_rate, regions_old[1] + regions_old[3] * y_rate,
regions_old[2] * np.exp(w_rate), regions_old[3] * np.exp(h_rate)]
results_dic[ind + 1].append(
[results[index][ind + 1], region_new[0] - region_new[2] / 2.0, region_new[1] - region_new[3] / 2.0,
region_new[0] + region_new[2] / 2.0, region_new[1] + region_new[3] / 2.0])
regions.append([region_new[0] - region_new[2] / 2.0, region_new[1] - region_new[3] / 2.0, region_new[2],
region_new[3], ind + 1, score])
if len(regions) != 0:
print(image_path+test_index+'.jpg')
Data.show_rect(image_path+test_index+'.jpg', regions, test_index)
else:
print('There is no target')
NMS_results = self.NMS(results_dic)
if len(NMS_results) != 0:
Data.show_rect(image_path+test_index+'.jpg', NMS_results, test_index )
NMS_average_results = self.NMS_average(results_dic)
if len(NMS_average_results) != 0:
Data.show_rect(image_path+test_index+'.jpg', NMS_average_results, test_index )
def NMS_IOU(self, vertice1, vertice2): # verticle:[pro,xin,ymin,xmax,ymax]
lu = np.maximum(vertice1[1:3], vertice2[1:3])
rd = np.minimum(vertice1[3:], vertice2[3:])
intersection = np.maximum(0.0, rd - lu)
inter_square = intersection[0] * intersection[1]
square1 = (vertice1[3] - vertice1[1]) * (vertice1[4] - vertice1[2])
square2 = (vertice2[3] - vertice2[1]) * (vertice2[4] - vertice2[2])
union_square = np.maximum(square1 + square2 - inter_square, 1e-10)
return np.clip(inter_square / union_square, 0.0, 1.0)
def NMS(self, result_dic):
final_result = []
for cls_ind, cls_collect in result_dic.items():
cls_collect = sorted(cls_collect, reverse=True)
for i in range(len(cls_collect) - 1):
for j in range(len(cls_collect) - 1, i, -1):
if self.NMS_IOU(cls_collect[i], cls_collect[j]) > cfg.NMS_threshold:
del cls_collect[j]
for each_result in cls_collect:
final_result.append(
[each_result[1], each_result[2], each_result[3] - each_result[1], each_result[4] - each_result[2],
cls_ind, each_result[0]])
return final_result
def NMS_average(self, result_dic):
final_result = []
for cls_ind, cls_collect in result_dic.items():
cls_collect = sorted(cls_collect, reverse=True)
for i in range(len(cls_collect) - 1):
for j in range(len(cls_collect) - 1, i, -1):
if self.NMS_IOU(cls_collect[i], cls_collect[j]) > cfg.NMS_threshold:
cls_collect[i] = [(x + y) / 2.0 for (x, y) in zip(cls_collect[i], cls_collect[j])]
del cls_collect[j]
for each_result in cls_collect:
final_result.append(
[each_result[1], each_result[2], each_result[3] - each_result[1], each_result[4] - each_result[2],
cls_ind, each_result[0]])
return final_resultFast R CNN里面用到的损失函数
因为这个过程对应的包含分类和边框回归,那么对应两个损失函数,针对分类的部分,用softmax损失函数来进行,针对边框回归部分,用smoothl1 loss来进行,前一个是比较常见的,一般对分类的任务,都会用到,softmax将输出的21个值的scroe转换成了概率分布,得分高的概率大,概率越大,证明对应的类别更有可能是target.
smoothl1 loss
这个函数多见于回归问题中,
函数形式为:

按照作者最正统的解释,因为回归的targets没有明确的限制,因此可能会出现较大的错误的偏移去主导loss的情况,最终造成梯度爆炸,使用这个函数能够更好地避免这种情况。
- 当预测框与 ground truth 差别过大时,梯度值不至于过大;
- 当预测框与 ground truth 差别很小时,梯度值足够小。

同时,这个函数是L1损失函数和L2损失函数的折中体,或者说是优化体,具体见下面链接。
详解:https://www.zhihu.com/question/58200555