从Inception到Xception,卷积方式的成长之路!
2014年Google提出了多尺度、更宽的Inception网络结构,不仅比同期的VGG更新小,而且速度更快。Xception则将Inception的思想发挥到了极致,解开了分组卷积和大规模应用的序幕。
本文将详细讲述
- Inception v1的多尺度卷积和Pointwise Conv
- Inception v2的小卷积核替代大卷积核方法
- Inception v3的卷积核非对称拆分
- Bottleneck卷积结构
- Depthwise Separable Conv深度可分离卷积
多尺度卷积
Inception 最初提出的版本主要思想是利用不同大小的卷积核实现不同尺度的感知,网络结构图如下:
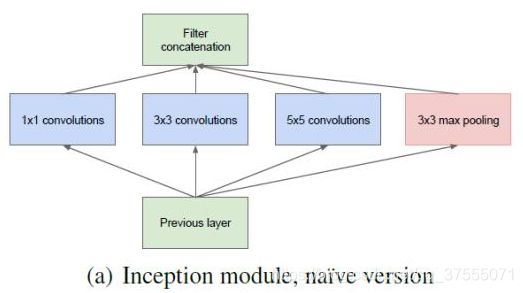
Inception Module基本组成结构有四个成分。1*1卷积,3*3卷积,5*5卷积,3*3最大池化。最后对四个成分运算结果进行通道上组合,这就是Inception Module的核心思想:利用不同大小的卷积核实现不同尺度的感知,最后进行融合,可以得到图像更好的表征。
使用了多尺度卷积后,我们的网络更宽了,同时也提高了对于不同尺度的适应程度。
Pointwise Conv
使用了多尺度卷积后,我们的网络更宽了,虽然提高了对于不同尺度的适应程度,但是计算量也变大了,所以我们就要想办法减少参数量来减少计算量,于是在 Inception v1 中的最终版本加上了 1x1 卷积核,网络结构图如下:
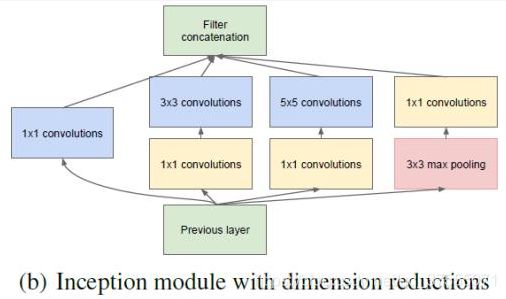
图a与图b的区别就是是否使用了 1x1 卷积进行压缩降维
使用1x1 卷积核主要目的是进行压缩降维,减少参数量,这就是Pointwise Conv,简称PW。
举个例子,假如输入的维度是 96 维,要求输出的维度是 32 维,二种计算方式:
- 第一种:用3x3的卷积核计算,参数量是
3*3*96*32=27648(为了方便计算,这里忽略偏置bias,后面的计算均如此) - 第二种:先用1x1卷积核将输出通道降维到32,参数量是
1*1*96*32=3072,再用3x3卷积计算输出,参数量是3*3*32*32=9216,总的参数量是3072+9216=12288
从结果12288/27648=0.44可以看到,第二种方式的参数量是第一种方式的0.44倍,大大减少了参数量,加快训练速度。
由Inception Module组成的GoogLeNet(Inception V1):

Inception V1 的主要思想是利用不同大小的卷积核实现了不同尺度的感知,再加上1x1 卷积的大量运用,模型比较精简,比VGG更深但是却更小
也有用Pointwise Conv做升维的,在 MobileNet v2 中就使用 Pointwise Conv 将 3 个特征图变成 6 个特征图,丰富输入数据的特征。
卷积核替换
就算有了Pointwise Conv,由于 5x5 卷积核直接计算参数量还是非常大,训练时间还是比较长,于是Google学习VGGNet的特点,提出了使用多个小卷积核替代大卷积核的方法,这就是 Inception V2:

在Inception V2中,使用两个 3x3 卷积核来代替 5x5 卷积,不仅使参数量少了,深度也变深了,提升了神经网络的效果,可谓一举多得。
为什么提升了网络深度,可以提升神经网络效果?
因为多层非线性层(每一层都加了relu)可以提供更复杂的模式学习,而且参数量更少 => 采用堆积的小卷积核优于采用大卷积核(相同感受野的情况下)
现在来计算一下参数量感受下吧!
假设输入 256 维,输出 512 维,计算参数量:
- 使用 5x5 卷积核,参数量为
5*5*256*512=3276800 - 使用两个 3x3 卷积核,参数量为
3*3*256*256+3*3*256*512=1769472
从结果1769472/3276800=0.54可以看到,第二种方式的参数量是第一种方式0.54倍,大大的减少了参数量,加快训练速度。
卷积核拆分
在使用多个小卷积核替代大卷积核的方法后,参数量还是比较大,于是Google学习Factorization into small convolutions的思想,在Inception V2的基础上,将一个二维卷积拆分成两个较小卷积,例如将7*7卷积拆成1*7卷积和7*1卷积,这样做的好处是降低参数量。该paper中指出,通过这种非对称的卷积拆分比对称的拆分为几个相同的小卷积效果更好,可以处理更多,更丰富的空间特征。这就是Inception V3网络结构:

让我们计算下参数量感受下吧!
假设输入 256 维,输出 512 维,计算参数量:
- 使用 5x5 卷积核,参数量为
5*5*256*512=3276800 - 先使用两个 1x5和5x1 卷积核,参数
1*5*256*256+5*1*256*512=983040
从结果983040/3276800=0.3可以看到,第二种方式的参数量是第一种方式0.3倍,比使用多个小卷积核替代大卷积核的方法减少还多。
Inception V4考虑到借鉴了微软的ResNet网络结构思想,等以后再做详细介绍。
Bottleneck
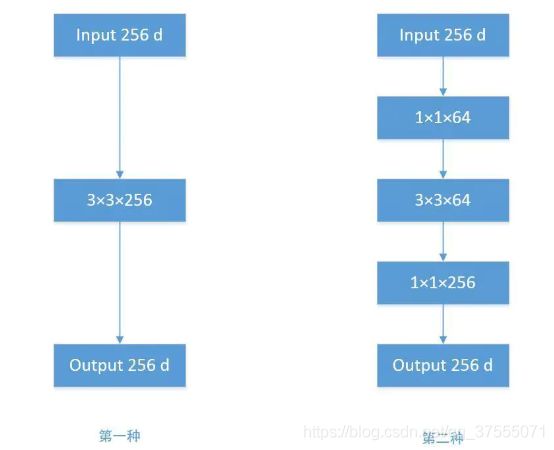
我们发现使用上面的结构和方法,参数量还是较大,于是人们提出了 Bottleneck 的结构降低参数量。
Bottleneck结构分三步走,首先用Pointwise Conv进行降维,再用常规卷积核进行卷积,最后使用Pointwise Conv进行进行升维,如下所示:
来吧,又到了计算参数量的时刻!
假设输入 256 维,输出 512 维,计算参数量:
- 使用 3x3 卷积核,参数量为
3*3*256*256=589824 - 使用 Bottleneck 的方式,先使用1x1卷积核将输入的256维讲到64维,再使用3x3卷积核进行卷积,最后用1x1卷积核将64升到256维,参数量为
1*1*256*64+3*3*64*64+1*1*64*256=69632
从结果69632/3276800=0.12可以看到,第二种方式的参数量是第一种方式0.12倍,参数量降得令人惊叹!
Depthwise Separable Conv
人们发现上面的方法参数量还是不少啊,于是又提出了Depthwise Separable Conv(深度可分离卷积),这就是大名鼎鼎的Xception的网络结构。
Depthwise Separable Conv的核心思想是首先经过1*1卷积,然后按通道分组进行卷积,假如每一个分组只有一个通道,就是Xception,即Extreme Inception。
Xception 要求每一个分组只有一个通道,而Depthwise Separable Conv除了每一个分组只有一个通道之外,也可以一个分组有多个通道。
我们来回顾一下从Inception到Xception的过程:
(1)典型的Inception结构(Inception V2):

(2)简单的Inception结构:

(3)对简单Inception结构进行严格等价变形的Inception结构(每一个分组有多个通道的Depthwise Separable Conv):

(4)极端的Inception结构(Extreme Inception),即Xception(每一个分组只有一个通道的Depthwise Separable Conv):

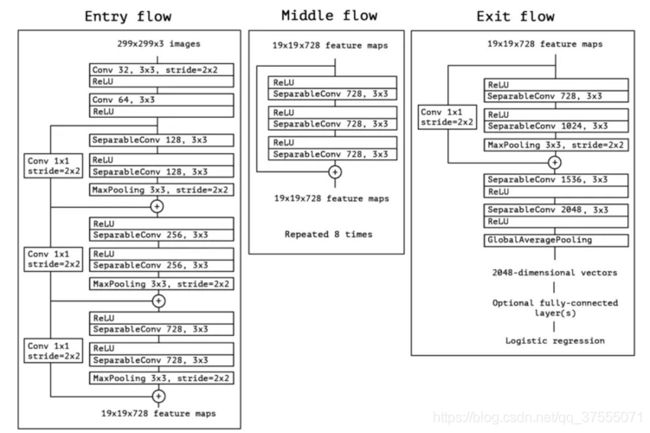
Xception Net的主题结构是以Separable Conv+relu为基本模块,再加上1x1卷积作为跳层连接,结构如下:
现在我们来对比一下,计算参数量吧!
一般的卷积如下:
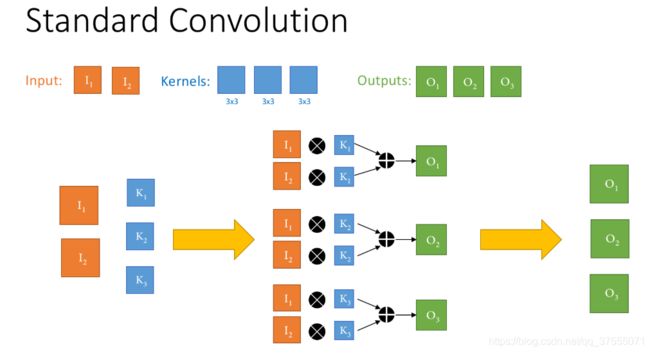
上图,输入通道2,输出通道3,卷积核大小3x3,参数量为3*3*2*3=54
Depthwise Separable Conv如下:

输入通道2,先进行经过1*1卷积,输出通道为3,参数量:1*1*2*3=6,再对这三个通道分组,分成3组,每组只有一个通道,进行Separable Conv(分离卷积),参数量:3*3*3=27,总的参数量为6+27=33
从结果33/54=0.61可以看到,第二种方式的参数量是第一种方式0.61倍,如果有更多卷积核对不同通道进行卷积,则参数量降低的效果更明显。
有的文章说Depthwise Separable Conv是先对不同的输入通道分别进行卷积,然后再融合,步骤是先 Depthwise Conv 再 Pointwise Conv,这个说法是错误的,Xception的论文中是先进行Pointwise Conv,然后再分组进行分离卷积。
Suummary
- Inception v1的多尺度卷积利用不同大小的卷积核实现不同尺度的感知,可以得到图像更好的表征。
- Inception v1的Pointwise Conv利用1x1卷积核进行压缩降维,减少参数量,使模型更加精简。
- Inception v2使用多个小卷积核替代大卷积核的方法,不仅使参数量少了,深度也变深了,提升了神经网络的效果。
- Inception v3的卷积核非对称拆分不仅可以降低参数量,而且可以处理更多,更丰富的空间特征。
- Bottleneck卷积结构分三步走,参数量降得令人惊叹!
- Depthwise Separable Conv首先经过1*1卷积,然后按通道分组进行卷积,再度减少参数量,使分组卷积这样的思想被广泛用于设计性能高效的网络。
基于Xception的网络结构MobileNets构建了轻量级的28层神经网络,成为了移动端上的高性能优秀基准模型;Resnet的残差连接直接skip connect,解决了深层网络的训练问题;可变形卷积 deformable convolution network 通过可变的感受野提升了CNN对具有不同几何形变物体识别能力的模型;DenseNet密集连接网络,把残差做到了极致,提高了特征的利用率;非局部神经网络转换一种思维,采用Non-Local连接,让神经网络具有更大的感受视野;多输入网络可以输入多张图片来完成一些任务;3D卷积虽然带来了暴涨的计算量,但是可以用于视频分类和分割;RNN和LSTM用于处理非固定长度或者大小的视频,语音等,更加适合用来处理这些时序信号;非生成对抗网络GAN已从刚开始的一个生成器一个判别器发展到了多个生成器多个判别器等各种各样的结构…人类的探索历程永无止境,未来必然有更加优秀的卷积方式和CNN架构出现,加油吧,后浪!
【参考文档】
[1] GoogLeNet中的inception结构,你看懂了吗
[2] 总结12大CNN主流模型架构设计思想
[3] 对于xception非常好的理解
[4] Chollet F. Xception: DeepLearningwithDepthwiseSeparableConvolutions