Python使用opencv识别简单图片中的主颜色
一、业务需求
本人也是python的初学者,在工作中接触一些简单的人工智能。因为工作关系,需要从系统提供的屏幕截图中识别系统菜单中的文字,该文字有一明显特征,就是橘色的高亮文字。那么需求就是从一个图片文件中识别里面的橘色高亮文字。识别图片样例:
![]()
二、设计思路
对样例图片进行分析,发现图片比较简单,没有太多颜色混杂在一起,主要是黑色字体、高亮的橘色字体这2两种字体组成。这样就给解决方案带来了很多便利性,设计思路大概如需:
- 分割图片:找到样例图片中的字块,进行分割,获取图片字块的像素坐标;
- 获取图片字块中的颜色:对图片字块中的颜色进行识别,找出属于橘色系的颜色部分,如果颜色区域的面积大于一个预设的阈值,就可以判断该图块的字体颜色符合预期。
三、分割图片
1、使用opencv,将图片转换为二值图,方便进行下面的处理
import cv2
import numpy as np
import matplotlib.pyplot as plt
image = cv2.imread('x4.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 转换了灰度化
ret, img = cv2.threshold(gray, 160, 255, cv2.THRESH_BINARY) # 将灰度图像二值化
img = 255 - img
cv2.imshow("img", img)
cv2.waitKey()
二值化的图片:
![]()
2、然后进行腐蚀图片。腐蚀图片的意义就不在这里赘述了,大家有兴趣的自行百度搜索吧。
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (7, 7))
img = cv2.dilate(img, kernel)
h, w = img.shape
cv2.imshow("img", img)
cv2.waitKey()
腐蚀后的图片:
![]()
3、垂直投影二值化图片。
这个时候,可以看到有字体的区域,已经连成一块了,这时候进行图片分割,就能很好的将连成一块的图片分割出来。这里用的分割技巧,就是垂直投影:二维图像(二值图)在x轴上的投影。垂直投影的核心就是在垂直方向,如果有像素点的值等于255,就将该垂直方向都标记为值255。
# 垂直反向投影
def vProject(binary):
h, w = binary.shape
# 创建 w 长度都为0的数组
w_w = [0]*w
for i in range(w):
for j in range(h):
if binary[j, i ] == 255:
w_w[i] += 255
plt.plot(range(w),w_w)
plt.show()
return w_w
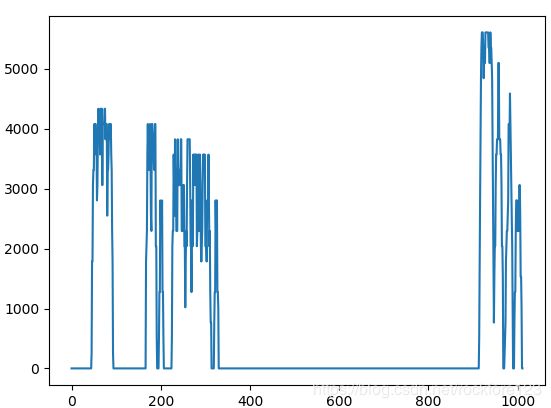
4、计算切分点并将切分点保存起来
w_w = vProject(img)
position = []
# w_start,w_end是记录垂直投影后白色块的x轴开始坐标和x轴结束坐标
# wstart,wend是记录白色块的开始标志和结束标志,开始记录时wstart=1,结束时wend=1
wstart, wend, w_start, w_end = 0, 0, 0, 0
for j in range(len(w_w)):
if w_w[j] > 0 and wstart == 0:
w_start = j
wstart = 1
wend = 0
if w_w[j] == 0 and wstart == 1:
w_end = j
wstart = 0
wend = 1
# 当确认了起点和终点之后保存坐标[x1,y1,x2,y2]
if wend == 1:
position.append([w_start, 0, w_end, h - 1])
wend = 0
5、按照已记录的坐标,对原图进行画出框框,标记出来已识别到的汉字图块。
# 其中(x1,y1)为左边的点,(x2,y2)为右边的点
for p in position:
cv2.rectangle(image, (p[0], p[1]), (p[2], p[3]), (255, 0, 255), 2)
cv2.imshow('image', image)
cv2.waitKey(0)
画出框的效果,可以看出效果还可以。下一步就是要对每个框框里面的字或内容进行颜色识别了。
![]()
四、获取图片字块中的颜色
识别图片的颜色,需要用到HSV模型,具体HSV模型原理不在这里赘述了。下面直接给出代码。
1、先给出橘色定义
#定义橘色识别模型
lower_orange = np.array([11, 43, 46])
upper_orange = np.array([25, 255, 255])
2、以lower_blue、upper_blue为阈值,去除背景部分。这样一来,除了橘色高亮字体的图片块,其他图片块都是一片黑色(图像值为0)。
#RGB 转 HSV 颜色模型
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# 低于lower_orange/高于upper_orange的值,图像值为0
# 在此之间的值变成255,即涂白色
mask = cv2.inRange(hsv, lower_orange, upper_orange)
cv2.imshow('image', mask)
cv2.waitKey(0)
识别出来的图片块如下:
![]()
3、寻找图像的轮廓
binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1] #将灰度图像二值化
binary = cv2.dilate(binary, None, iterations=2) #图像膨胀
#cv2的版本不同,findContours的返回值个数也不一样,此处是为了兼容不同版本
if int(cv2.__version__[0])>2:
contours,_= cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
else:
_, contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
4、计算找出来的图片轮廓的面积,与整体面积的比例是否达到预期。
#3-求轮廓的面积
sum = 0
space = img.shape[0]*img.shape[1]
for cts in contours:
sum+=cv2.contourArea(cts)
print("面积占比:",sum / space)
if sum / space > 0.3: #这里假定是30%,
print("get orange SUCCESS!")
5、至此,可以得到该图片的颜色确定是橘色无疑。然后再在原图上,根据已确认橘色的图块坐标把图抠出来就行了。
#注意图片块用[y1,y2,x1,x2]来获取
img = image[imgPos[1]:imgPos[3],imgPos[0]:imgPos[2]]
抠出来的图片如下:
![]()
五、总结
识别的图片还是比较简单的。使用了opencv里面的垂直投影方法,还有HSV模型中的颜色模型,来完成图片颜色的识别。此方法也可以用于车牌的识别。