一文读懂神经网络(附PPT、视频)

来源:云栖社区
本文共6500字,建议阅读10分钟。
本文从神经网络的发展历史出发,为你介绍感知器模型、前馈神经网络及BP算法。
[导读] 提起神经网络,你会想到什么?关于深度学习,你又是否思考过其中的原理呢?从上个世纪四十年代神经网络诞生开始,到今天已经历经70多年的发展,这中间它又经历了什么?本文将带领大家走进神经网络的“前世今生”一探究竟。
演讲嘉宾简介:
孙飞(丹丰),阿里巴巴搜索事业部高级算法工程师。中科院计算所博士,博士期间主要研究方向为文本分布式表示,在SIGIR、ACL、EMNLP以及IJCAI等会议发表论文多篇。目前主要从事推荐系统以及文本生成相关方面研发工作。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本次的分享主要围绕以下五个方面:
神经网络的发展历史
感知器模型
前馈神经网络
后向传播
深度学习入门
一.神经网络的发展历史
在介绍神经网络的发展历史之前,首先介绍一下神经网络的概念。神经网络主要是指一种仿造人脑设计的简化的计算模型,这种模型中包含了大量的用于计算的神经元,这些神经元之间会通过一些带有权重的连边以一种层次化的方式组织在一起。每一层的神经元之间可以进行大规模的并行计算,层与层之间进行消息的传递。
下图展示了整个神经网络的发展历程:
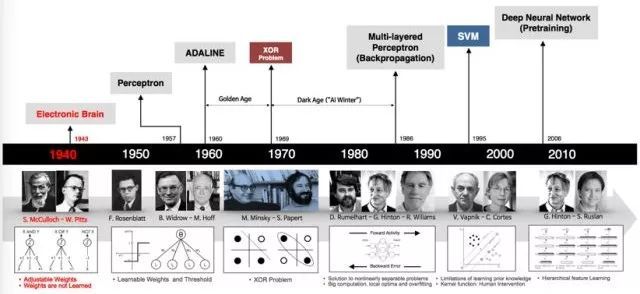
神经网络的发展历史甚至要早于计算机的发展,早在上个世纪四十年代就已经出现了最早的神经网络模型。接下来本文将以神经网络的发展历程为主线带领大家对神经网络的基本知识作初步了解。
第一代的神经元模型是验证型的,当时的设计者只是为了验证神经元模型可以进行计算,这种神经元模型既不能训练也没有学习能力,可以简单的把它看成是一个定义好的逻辑门电路,因为它的输入和输出都是二进制的,而中间层的权重都是提前定义好的。
神经网络的第二个发展时代是十九世纪五六十年代,以Rosenblatt提出的感知器模型和赫伯特学习原则等一些工作为代表。
二.感知器模型
感知器模型与之前提到的神经元模型几乎是相同的,但是二者之间存在着一些关键的区别。感知器模型的激活函数可以选择间断函数和sigmoid函数,且其输入可以选择使用实数向量,而不是神经元模型的二进制向量。与神经元模型不同,感知器模型是一个可以学习的模型,下面介绍一下感知器模型的一个优良特性——几何解释。
我们可以把输入值(x1, . . . , xn)看作是N维空间中的一个点的坐标,w⊤x−w0 = 0 可以认为是N维空间中的一个超平面,显然,当w⊤x−w0<0时,此时的点落在超平面的下方,而当w⊤x−w0>0时,此时的点落在超平面的上方。感知器模型对应的就是一个分类器的超平面,它可以将不同类别的点在N维空间中分离开。从下图中可以发现,感知器模型是一个线性的分类器。

对于一些基本的逻辑运算,例如与、或、非,感知器模型可以非常容易地作出判断分类。那么是不是所有的逻辑运算都可以通过感知器进行分类呢?答案当然是否定的。比如异或运算通过一个单独的线性感知器模型就很难作出分类,这同样也是神经网络的发展在第一次高潮之后很快进入低谷的主要原因。这个问题最早在Minsky等人在关于感知器的著作中提出,但其实很多人对这本著作存在误区,实际上Minsky等人在提出这个问题的同时也指出异或运算可以通过多层感知器实现,但是由于当时学术界没有有效的学习方式去学习多层感知器模型,所以神经网络的发展迎来了第一次低谷。
关于多层感知器模型实现异或操作的直观几何体现如下图所示:

三.前馈神经网络
进入十九世纪八十年代之后,由于单层的感知器神经网络的表达能力非常有限,只能做一些线性分类器的任务,神经网络的发展进入了多层感知器时代。一个典型的多层神经网络就是前馈神经网络,如下图所示,它包括输入层、节点数目不定的隐层和输出层。任何一个逻辑运算都可以通过多层感知器模型表示,但这就涉及到三层之间交互的权重学习问题。将输入层节点xk乘以输入层到隐层之间的权重vkj,然后经过一个如sigmoid此类的激活函数就可以得到其对应的隐层节点数值hj,同理,经过类似的运算可以由hj得出输出节点值yi。
需要学习的权重信息就是w和v两个矩阵,最终得到的信息是样本的输出y和真实输出d。具体过程如下图所示:

如果读者有简单的机器学习知识基础的话,就会知道一般情况下会根据梯度下降的原则去学习一个模型。在感知器模型中采用梯度下降的原则是较为容易的,以下图为例,首先确定模型的loss,例子中采用了平方根loss,即求出样本的真实输出d与模型给出的输出y之间的差异,为了计算方便,通常情况下采用了平方关系E= 1/2 (d−y)^2 = 1/2 (d−f(x))^2 ,根据梯度下降的原则,权重的更新遵循如下规律:wj ← wi + α(d − f(x))f′(x)xi ,其中α为学习率,可以作人工调整。

四.后向传播
对于一个多层的前馈神经网络,我们该如何学习其中所有的参数呢?首先对于最上层的参数是非常容易获得的,可以根据之前提到的计算模型输出和真实输出之间的差异,根据梯度下降的原则来得出参数结果,但问题是对于隐层来说,虽然我们可以计算出其模型输出,但是却不知道它的期望输出是什么,也就没有办法去高效训练一个多层神经网络。这也是困扰了当时学术界很长时间的一个问题,进而导致了上个世纪六十年代之后神经网络一直没有得到更多发展。
后来到了十九世纪七十年代,有很多科学家独立的提出了一个名为后向传播的算法。这个算法的基本思想其实非常简单,虽然在当时无法根据隐层的期望输出去更新它的状态,但是却可以根据隐层对于Error的梯度来更新隐层到其他层之间的权重。计算梯度时,由于每个隐层节点与输出层多个节点之间均有关联,所以会对其上一层所有的Error作累加处理。
后向传播的另一个优势是计算同层节点的梯度和权重更新时可以并行进行,因为它们之间不存在关联关系。整个BP算法的过程可以用如下的伪码表示:

接下来介绍一些BP神经网络的其他性质。BP算法其实就是一个链式法则,它可以非常容易地泛化到任意一个有向图的计算上去。根据梯度函数,在大多数情况下BP神经网络给出的只是一个局部的最优解,而不是全局的最优解。但是从整体来看,一般情况下BP算法能够计算出一个比较优秀的解。下图是BP算法的直观演示:

在大多数情况下,BP神经网络模型会找到范围内的一个极小值点,但是跳出这个范围我们可能会发现一个更优的极小值点。在实际应用中针对这样的问题我们有很多简单但是非常有效的解决办法,比如可以尝试不同的随机初始化的方式。而实际上在深度学习领域当今比较常用的一些模型上,初始化的方式对于最终的结果是有非常大的影响的。另外一种使模型跳出局部最优解范围的方式是在训练的时候加入一些随机干扰(Random noises),或者用一些遗传算法去避免训练模型停留在不理想的局部最优解位置。
BP神经网络是机器学习的一个优秀的模型,而提到机器学习就不得不提到一个在整个机器学习过程中经常遇到的基本问题——过拟合(Overfitting)问题。过拟合的常见现象是模型在训练集上面虽然loss一直在下降,但是实际上在test集上它的loss和error可能早已经开始上升了。避免出现过拟合问题有两种常见的方式:
提前停止(Early Stopping):我们可以预先划分一个验证集(Validation),在训练模型的同时也在验证集之中运行这个模型,然后观察该模型的loss,如果在验证集中它的loss已经停止下降,这时候即使训练集上该模型的loss仍在下降,我们依然可以提前将其停止来防止出现过拟合问题。
正则(Regularization):我们可以在神经网络中边的权重上加一些正则。最近几年经常用到的dropout方式——随机丢一些点或者随机丢一些边,也可以看作是正则的一种方式,正则也是一种很有效的防止过拟合的应用方式。
十九世纪八十年代神经网络一度非常流行,但很不幸的是进入九十年代,神经网络的发展又陷入了第二次低谷。造成这次低谷的原因有很多,比如支持向量机(SVM)的崛起,支持向量机在九十年代是一个非常流行的模型,它在各大会议均占有一席之地,同时也在各大应用领域都取得了非常好的成绩。支持向量机有一个非常完善的统计学习理论,也有非常好的直观解释,并且效率也很高,结果又很理想。
所以在此消彼长的情况下,支持向量机相关的统计学习理论的崛起一定程度上压制了神经网络的发展热度。另一方面,从神经网络自身的角度来看,虽然理论上可以用BP去训练任意程度的神经网络,但是在实际应用中我们会发现,随着神经网络层数的增加,神经网络的训练难度成几何式增长。比如在九十年代早期,人们就已经发现在层次比较多的一个神经网络当中可能会出现梯度消失或者梯度爆炸的一个现象。
举一个简单的梯度消失的例子,假设神经网络的每一层都是一个sigmoid结构层,那么BP向后传播时它的loss每一次都会连成一个sigmoid的梯度。一系列的元素连接在一起,如果其中有一个梯度非常小的话,会导致传播下去的梯度越来越小。实际上,在传播一两层之后,这个梯度已经消失了。梯度消失会导致深层次的参数几乎静止不动,很难得出有意义的参数结果。这也是为什么多层神经网络非常难以训练的一个原因所在。
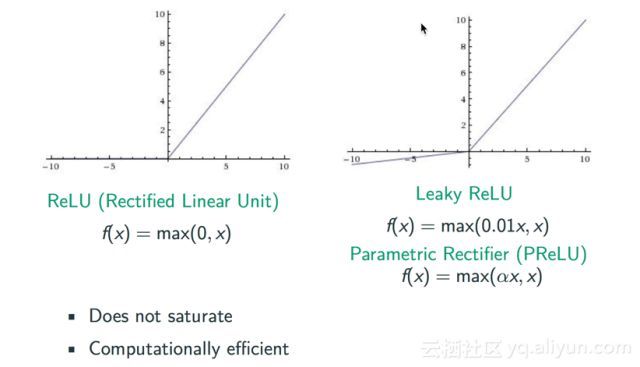
学术界对于这个问题有比较多的研究,最简单的处理方式就是修改激活函数。早期的尝试就是使用Rectified这种激活函数,由于sigmoid这个函数是指数的形式,所以很容易导致梯度消失这种问题,而Rectified将sigmoid函数替换成max(0,x),从下图我们可以发现,对于那些大于0的样本点,它的梯度就是1,这样就不会导致梯度消失这样一个问题,但是当样本点处于小于0的位置时,我们可以看到它的梯度又变成了0,所以ReLU这个函数是不完善的。后续又出现了包括Leaky ReLU和Parametric Rectifier(PReLU)在内的改良函数,当样本点x小于0时,我们可以人为的将其乘以一个比如0.01或者α这样的系数来阻止梯度为零。
随着神经网络的发展,后续也出现了一些从结构上解决梯度难以传递问题的方法,比如元模型,LSTM模型或者现在图像分析中用到非常多的使用跨层连接的方式来使其梯度更容易传播。
五.深度学习入门
经过上个世纪九十年代神经网络的第二次低谷,到2006年,神经网络再一次回到了大众的视野,而这一次回归之后的热度远比之前的任何一次兴起时都要高。神经网络再次兴起的标志性事件就是Hinton等人在Salahudinov等地方发表的两篇关于多层次神经网络(现在称作“深度学习”)的论文。
其中一篇论文解决了之前提到的神经网络学习中初始值如何设置的问题,解决途径简单来说就是假设输入值是x,那么输出则是解码x,通过这种方式去学习出一个较好的初始化点。而另一篇论文提出了一个快速训练深度神经网络的方法。其实造成现在神经网络热度现状的原因还有很多,比如当今的计算资源相比当年来说已经非常庞大,而数据也是如此。在十九世纪八十年代时期,由于缺乏大量的数据和计算资源,当时很难训练出一个大规模的神经网络。
神经网络早期的崛起主要归功于三个重要的标志性人物Hinton、Bengio和LeCun。Hinton的主要成就在于布尔计算机(Restricted Boltzmann Machine)和深度自编码机(Deep autoencoder);Bengio的主要贡献在于元模型在深度学习上的使用取得了一系列突破,这也是深度学习最早在实际应用中取得突破的领域,基于元模型的language modeling在2003时已经可以打败当时最好的概率模型;LeCun的主要成就代表则是关于CNN的研究。深度学习崛起最主要的表现是在各大技术峰会比如NIPS,ICML,CVPR,ACL上占据了半壁江山,包括Google Brain,Deep Mind和FaceBook AI等在内的研究部门都把研究工作的中心放在了深度学习上面。

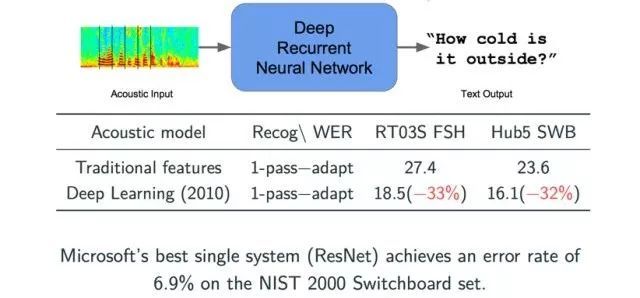
神经网络进入公众视野后的第一个突破是在语音识别领域,在使用深度学习理论之前,人们都是通过使用定义好的统计库来训练一些模型。在2010年,微软采用了深度学习的神经网络来进行语音识别,从图中我们可以看到,两个错误的指标均有将近三分之一的大幅度下降,效果显著。而基于最新的ResNet技术,微软公司已经把这个指标降到了6.9%,每一年都有一个明显的提升。
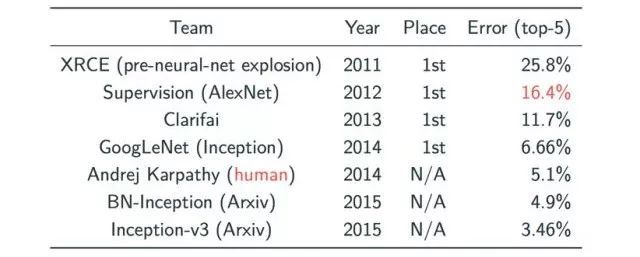
到2012年,在图片分类领域,CNN模型在ImageNet上取得了一个较大的突破。测试图片分类的是一个很大的数据集,要将这些图片分成1000类。在使用深度学习之前,当时最好的结果是错误率为25.8%(2011年的一个结果),在2012年Hinton和它的学生将CNN应用于这个图片分类问题之后,这个指标下降了几乎10%,自2012年之后,我们从图表中可以观察到每一年这个指标都有很大程度的突破,而这些结果的得出均使用了CNN模型。
深度学习模型能取得如此大的成功,在现代人看来主要归功于其层次化的结构,能够自主学习并将数据通过层次化结构抽象地表述出来。而抽象出来的特征可以应用于其他多种任务,这也是深度学习当前十分火热的原因之一。
下面介绍两个非常典型且常用的深度学习神经网络:一个是卷积神经网络(CNN),另外一个是循环神经网络。
1.卷积神经网络
卷积神经网络有两个基本核心概念,一个是卷积(Convolution),另一个是池化(Pooling)。讲到这里,可能有人会问,为什么我们不简单地直接使用前馈神经网络,而是采用了CNN模型?举个例子,对于一个1000*1000的图像,神经网络会有100万个隐层节点,对于前馈神经网络则需要学习10^12这样一个庞大数量级的参数,这几乎是无法进行学习的,因为需要海量的样本。但实际上对于图像来说,其中很多部分具有相同的特征,如果我们采用了CNN模型进行图片的分类的话,由于CNN基于卷积这个数学概念,那么每个隐层节点只会跟图像中的一个局部进行连接并扫描其局部特征。假设每个隐层节点连接的局部样本点数为10*10的话,那么最终参数的数量会降低到100M,而当多个隐层所连接的局部参数可以共享时,参数的数量级更会大幅下降。

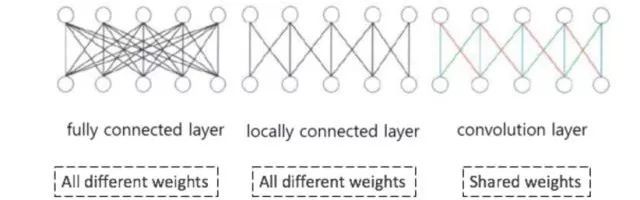
从下图中我们可以直观的看出前馈神经网络和CNN之间的区别。图中的模型从左到右依次是全连接的普通的前馈神经网络,局部连接的前馈神经网络和基于卷积的CNN模型网络。我们可以观察到基于卷积的神经网络隐层节点之间的连接权重参数是可以共享的。
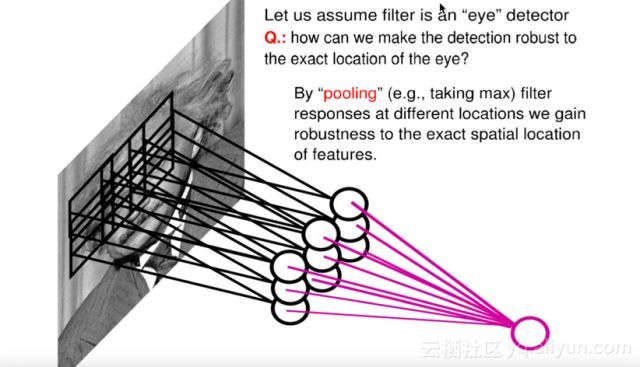
另一个操作则是池化(Pooling),在卷积生成隐层的基础上CNN会形成一个中间隐层——Pooling层,其中最常见的池化方式是Max Pooling,即在所获得的隐层节点中选择一个最大值作为输出,由于有多个kernel进行池化,所以我们会得到多个中间隐层节点。
那么这样做的好处是什么呢?首先,通过池化操作会是参数的数量级进一步缩小;其次就是具有一定的平移不变性,如图所示,假设图中的九个隐层节点中的其中一个发生平移,池化操作后形成的Pooling层节点仍旧不变。
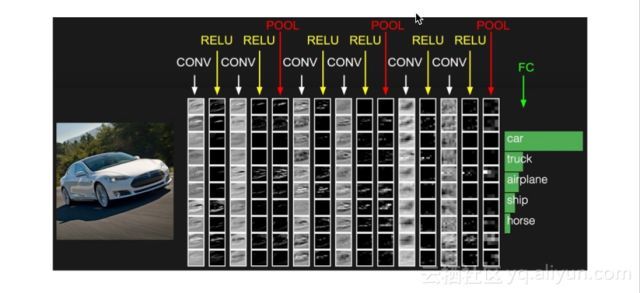
CNN的这两个特性使得它在图像处理领域的应用非常广泛,现在甚至已经成为了图像处理系统的标配。像下面这个可视化的汽车的例子就很好地说明了CNN在图像分类领域上的应用。将原始的汽车图片输入到CNN模型之中后,从起初最原始的一些简单且粗糙的特征例如边和点等,经过一些convolution和RELU的激活层,我们可以直观的看到,越接近最上层的输出图像,其特征越接近一辆汽车的轮廓。该过程最终会得到一个隐层表示并将其接入一个全连接的分类层然后得出图片的类别,如图中的car,truck,airplane,ship,horse等。
下图是早期LeCun等人提出的一个用于手写识别的神经网络,这个网络在九十年代时期已经成功运用到美国的邮件系统之中。感兴趣的读者可以登录LeCun的网站查看其识别手写体的动态过程。

当CNN在图像领域应用十分流行的同时,在近两年CNN在文本领域也得到了大规模应用。例如对于文本分类这个问题,目前最好的模型是基于CNN模型提出来的。从文本分类的特点来看,对一个文本的类别加以鉴别实际上只需要对该文本中的一些关键词信号加以识别,而这种工作非常适合CNN模型来完成。
实际上如今的CNN模型已经应用到人们生活中的各个领域,比如侦查探案,自动驾驶汽车的研发,Segmenttation还有Neural Style等方面。其中Neural Style是个非常有趣的应用,比如之前App Store中有个非常火的应用Prisma,可以将使用者上传的照片转换成其他的风格,比如转换成梵高的星空一样的画风,在这其中就大量应用了CNN的技术。
2. 循环神经网络
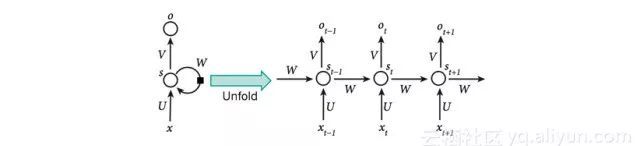
关于循环神经网络的基本原理如下图所示,从图中可以看循环神经网络的输出不仅依赖于输入x,而且依赖于当前的隐层状态,而这个隐层状态会根据前一个x进行更新。从展开图中可以直观的理解这个过程,第一次输入的中间隐层状态S(t-1)会影响到下一次的输入X(t)。循环神经网络模型的优势在于可以用于文本、语言或者语音等此类序列型的数据,即当前数据的状态受到此前数据状态的影响。对于此类数据,前馈神经网络是很难实现的。
提到RNN,那就不得不介绍一下之前提到的LSTM模型。实际上LSTM并不是一个完整的神经网络,它只是一个RNN网路中的节点经过复杂处理后的结果。LSTM中包含三个门:输入门,遗忘门和输出门。
这三个门均用于处理cell之中的数据内容,分别决定是否要将cell中的数据内容输入、遗忘和输出。

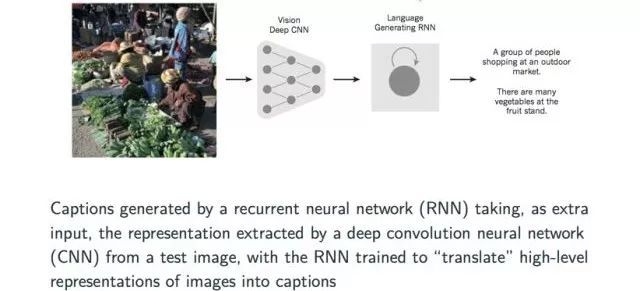
最后介绍一个目前非常流行的交叉领域的神经网络的应用——将一个图片转换成描述形式的文字或者该图片的title。具体的实现过程可以简单的解释为首先通过一个CNN模型将图片中的信息提取出来形成一个向量表示,然后将该向量作为输入传送到一个训练好的RNN模型之中得出该图片的描述。
直播视频回顾地址:https://yq.aliyun.com/video/play/1370?spm=a2c41.11124528.0.0
