聚类算法系列--聚类的性能评估Clustering performance evaluation
博客:https://blog.csdn.net/sinat_33363493/article/details/52496011,
https://www.jianshu.com/p/b5996bf06bd6,
https://blog.csdn.net/u013709270/article/details/74276533
论文:Liu Y, Li Z, Xiong H, et al. Understanding of Internal Clustering Validation Measures[C]// IEEE, International Conference on Data Mining. IEEE, 2011:911-916.
http://scikit-learn.org/stable/modules/clustering.html#clustering-performance-evaluation
评估聚类算法仅仅通过简单的计算错误的预测数量来进行评估效果不好
Purity方法:只需计算正确聚类的数占总数的比例

其中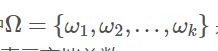 表示聚类的集合ωk表示第k个聚类的集合,
表示聚类的集合ωk表示第k个聚类的集合,![]() 表示真实的类别信息
表示真实的类别信息
知道数据的类别信息
Adjusted Rand index
兰德指数,rand index,C是真实的类别信息,K是聚类算法聚类结果的类别信息,a表示聚类结果类别和实际类别一致的元素对数,b,表示聚类结果的类别和实际类别不一致的元素对数:

RI取值范围为[0,1],值越大意味着聚类结果与真实情况越吻合。
考虑到随机标签在进行分类的时候指标应该为0,(当簇数和样本数目的数量级相同时)
提出了调整兰德指数,需要计算一个随机标签的期望兰德指数
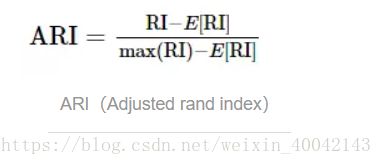
ARI取值范围为[−1,1],值越大意味着聚类结果与真实情况越吻合
优点:
- Random (uniform) label assignments have a ARI score close to 0.0 for any value of
n_clustersandn_samples(which is not the case for raw Rand index or the V-measure for instance).----随机标签分配的类别ARI得分为0 - Bounded range [-1, 1]: negative values are bad (independent labelings), similar clusterings have a positive ARI, 1.0 is the perfect match score.
- No assumption is made on the cluster structure: can be used to compare clustering algorithms such as k-means which assumes isotropic blob shapes with results of spectral clustering algorithms which can find cluster with “folded” shapes.
缺点:
需要事先知道真实的类别信息,在现实中不现实
Mutual Information based scores
互信息,在给定真实类别信息的前提下,用来评估两个数据分布的一致性的,他不考虑数据的排序。
Normalized Mutual Information(NMI):标准互信息通用用于literature 领域。
Adjusted Mutual Information(AMI):针对偶然性进行的规范化
数学表达
https://en.wikipedia.org/wiki/Adjusted_mutual_information,
https://en.wikipedia.org/wiki/Mutual_information
用熵来表示划分的不确定性
NMI公式如下:

AMI公式如下:

优点:
- Random (uniform) label assignments have a AMI score close to 0.0 for any value of
n_clustersandn_samples(which is not the case for raw Mutual Information or the V-measure for instance).----随机标签分配的可调整互信息得分为0 - Bounded range [0, 1]: Values close to zero indicate two label assignments that are largely independent(得分为0表示这两个标签很大程度上是独立的), while values close to one indicate significant agreement.
Further, values of exactly 0 indicate purely independent label assignments and a AMI of exactly 1 indicates that the two label assignments are equal (with or without permutation).
- No assumption is made on the cluster structure: can be used to compare clustering algorithms such as k-means which assumes isotropic blob shapes with results of spectral clustering algorithms which can find cluster with “folded” shapes.
缺点:
- 需要事先知道真实的类别信息
- NMI and MI are not adjusted against chance---NMI和MI没有针对偶然性进行调整
Homogeneity, completeness and V-measure
对于给定了真实类别信息的数据,可以分析其条件熵来看聚类效果
homogeneity:每个簇只包含一个单一的类别
completeness:对所给的一个类别的所有数据应该划分到一个簇里面
这两个标准的得分界限为[0,1],分数越高,聚类的效果越好
V-measure:homogeneity和completeness的平均值, V-measure is symmetric: it can be used to evaluate the agreement of two independent assignments on the same dataset.
数学公式如下

优点:
- Bounded scores: 0.0 is as bad as it can be, 1.0 is a perfect score.得分越高,聚类算法性能越好
- Intuitive interpretation: clustering with bad V-measure can be qualitatively analyzed in terms of homogeneity and completeness to better feel what ‘kind’ of mistakes is done by the assignment.通过对三个值的分析,可以发现划分类别时的错误,比如,一个簇里面包含了多个类别,同一类别的数据划分到了不同的簇里面
- No assumption is made on the cluster structure: can be used to compare clustering algorithms such as k-means which assumes isotropic blob shapes with results of spectral clustering algorithms which can find cluster with “folded” shapes.
缺点:
- random labeling won’t yield zero scores especially when the number of clusters is large.
This problem can safely be ignored when the number of samples is more than a thousand and the number of clusters is less than 10. (当样本数据超过1000,簇数小于10的时候,该问题可以忽略)For smaller sample sizes or larger number of clusters it is safer to use an adjusted index such as the Adjusted Rand Index (ARI).-----样本数目很少或者簇数量很大的时候建议使用ARI进行评估
Fowlkes-Mallows scores
在知道数据的真实类别信息的情况下,可以用该指标对聚类算法进行评估。
FMI is defined as the geometric mean of the pairwise precision and recall(定义为精确率和召回率的几何平均数):

关于精确率和召回率可参考:https://blog.csdn.net/mousever/article/details/48622163
Where TP is the number of True Positive (i.e. the number of pair of points that belong to the same clusters in both the true labels and the predicted labels), FP is the number of False Positive (i.e. the number of pair of points that belong to the same clusters in the true labels and not in the predicted labels) and FN is the number of False Negative (i.e the number of pair of points that belongs in the same clusters in the predicted labels and not in the true labels).
缺点:需要事先知道数据的类别信息
不知道知道数据的正确类别信息
Silhouette Coefficient
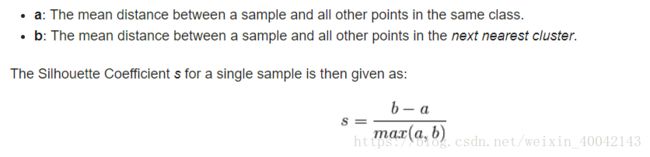
缺点:不适合基高密度的聚类算法DBSCAN
Calinski-Harabaz Index

缺点:不适合基于密度的聚类算法,DBSCAN