从R-CNN,Fast R-CNN,Faster R-CNN再到Mask R-CNN详解
众所周知,Mask R-CNN是继承于Faster R-CNN (2016)的,Mask R-CNN只是在Faster R-CNN上面加了一个Mask Prediction Branch (Mask 预测分支),并且改良了ROI Pooling,提出了ROI Align。Faster R-CNN又是继承于Fast R-CNN (2015),Fast R-CNN继承于R-CNN (2014)。因此,在本篇博文中,就按照R-CNN, Fast R-CNN,Faster R-CNN再到Mask R-CNN的发展顺序全部解析。
首先时间回到了2014年,在2014年,正是深度学习如火如荼的发展的第三年。在CVPR 2014年中Ross Girshick提出的R-CNN中,使用到了卷积神经网络来进行目标检测。下面笔者就来概述一下R-CNN是如何采用卷积神经网络进行目标检测的工作。
 首先模型输入为一张图片,然后在图片上提出了约2000个待检测区域,然后这2000个待检测区域一个一个地(串联方式)通过卷积神经网络提取特征,然后这些被提取的特征通过一个支持向量机(SVM)进行分类,得到物体的类别,并通过一个bounding box regression调整目标包围框的大小。下面,笔者简要概述一下R-CNN是怎么实现以上步骤的。
首先模型输入为一张图片,然后在图片上提出了约2000个待检测区域,然后这2000个待检测区域一个一个地(串联方式)通过卷积神经网络提取特征,然后这些被提取的特征通过一个支持向量机(SVM)进行分类,得到物体的类别,并通过一个bounding box regression调整目标包围框的大小。下面,笔者简要概述一下R-CNN是怎么实现以上步骤的。
首先在第一步提取2000个待检测区域的时候,是通过一个2012年提出的方法,叫做selective search。简单来说就是通过一些传统图像处理方法将图像分成若干块,然后通过一个SVM将属于同一目标的若干块拿出来。selective search的核心是一个SVM,架构如下所示:

然后在第二步进行特征提取的时候,Ross直接借助了当时深度学习的最新成果AlexNet (2012)。那么,该网络是如何训练的呢?是直接在ImageNet上面训练的,也就是说,使用图像分类数据集训练了一个仅仅用于提取特征的网络。
在第三步进行对目标的时候,使用了一个支持向量机(SVM),在训练这个支持向量机的时候,结合目标的标签(类别)与包围框的大小进行训练,因此,该支持向量机也是被单独训练的。
在2014年R-CNN横空出世的时候,颠覆了以往的目标检测方案,精度大大提升。对于R-CNN的贡献,可以主要分为两个方面:
1) 使用了卷积神经网络进行特征提取。
2) 使用bounding box regression进行目标包围框的修正。
但是,我们来看一下,R-CNN有什么问题:
-
耗时的selective search,对一帧图像,需要花费2s。
-
耗时的串行式CNN前向传播,对于每一个RoI,都需要经过一个AlexNet提特征,为所有的RoI提特征大约花费47s。
-
三个模块是分别训练的,并且在训练的时候,对于存储空间的消耗很大。
那么,面对这种情势,Ross在2015年提出的Fast R-CNN进行了改进,下面我们来概述一下Fast R-CNN的解决方案:
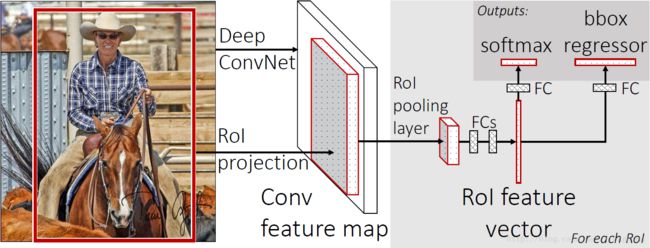
首先还是采用selective search提取2000个候选框,然后,使用一个神经网络对全图进行特征提取。接着,使用一个RoI Pooling Layer在全图特征上摘取每一个RoI对应的特征,再通过全连接层(FC Layer)进行分类与包围框的修正。Fast R-CNN的贡献可以主要分为两个方面:
-
取代R-CNN的串行特征提取方式,直接采用一个神经网络对全图提取特征(这也是为什么需要RoI Pooling的原因)。
-
除了selective search,其他部分都可以合在一起训练。
可是,Fast R-CNN也有缺点,体现在耗时的selective search还是依旧存在。那么,如何改良这个缺陷呢?发表于2016年的Faster R-CNN进行了如下创新:
取代selective search,直接通过一个Region Proposal Network (RPN)生成待检测区域,这么做,在生成RoI区域的时候,时间也就从2s缩减到了10ms。我们来看一下Faster R-CNN是怎么做的。
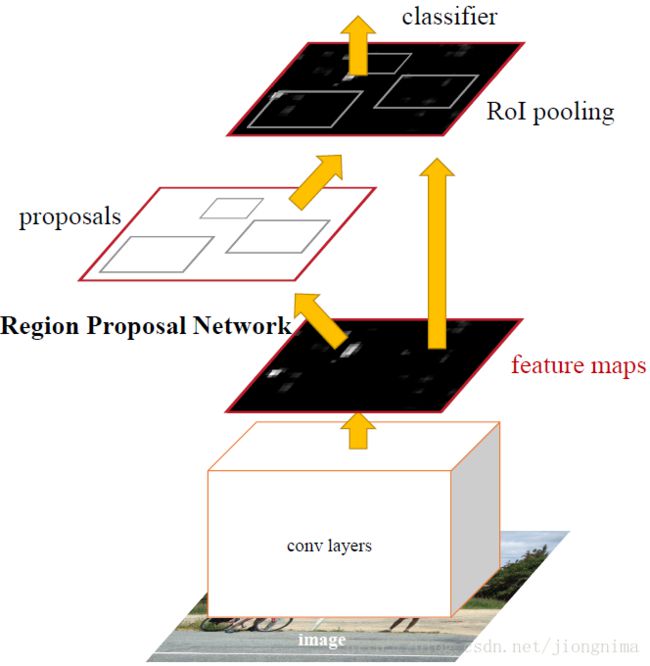
首先使用共享的卷积层为全图提取特征,然后将得到的feature maps送入RPN,RPN生成待检测框(指定RoI的位置)并对RoI的包围框进行第一次修正。之后就是Fast R-CNN的架构了,RoI Pooling Layer根据RPN的输出在feature map上面选取每个RoI对应的特征,并将维度置为定值。最后,使用全连接层(FC Layer)对框进行分类,并且进行目标包围框的第二次修正。尤其注意的是,Faster R-CNN真正实现了端到端的训练(end-to-end training)。
要理解Mask R-CNN,只有先理解Faster R-CNN。因此,笔者根据Faster R-CNN的架构(Faster R-CNN的ZF model的train.prototxt),画了一个结构图,如下所示:
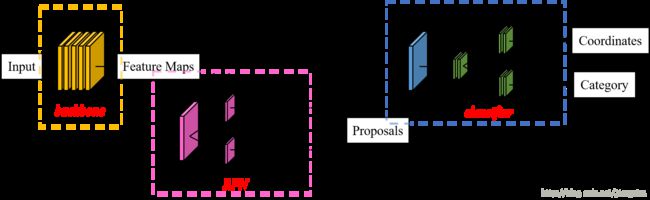
如上图所示,Faster R-CNN的结构主要分为三大部分,第一部分是共享的卷积层-backbone,第二部分是候选区域生成网络-RPN,第三部分是对候选区域进行分类的网络-classifier。其中,RPN与classifier部分均对目标框有修正。classifier部分是原原本本继承的Fast R-CNN结构。我们下面来简单看看Faster R-CNN的各个模块。
首先来看看RPN的工作原理:
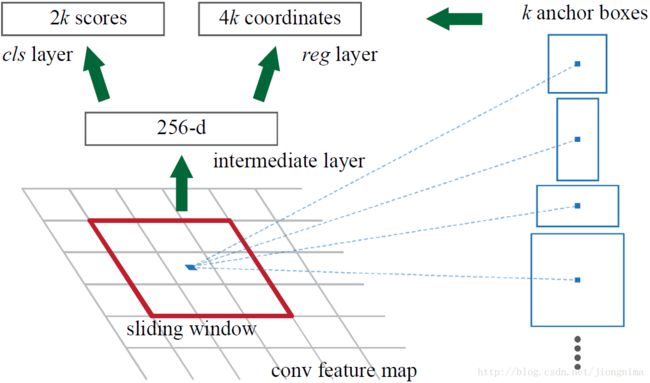
简单地说,RPN依靠一个在共享特征图上滑动的窗口,为每个位置生成9种预先设置好长宽比与面积的目标框(文中叫做anchor)。这9种初始anchor包含三种面积(128×128,256×256,512×512),每种面积又包含三种长宽比(1:1,1:2,2:1)。示意图如下所示:

由于共享特征图的大小约为40×60,RPN生成的初始anchor的总数约为20000个(40×60×9)。对于生成的anchor,RPN要做的事情有两个,第一个是判断anchor到底是前景还是背景,意思就是判断这个anchor到底有没有覆盖目标,第二个是为属于前景的anchor进行第一次坐标修正。对于前一个问题,Faster R-CNN的做法是使用SoftmaxLoss直接训练,在训练的时候排除掉了超越图像边界的anchor;对于后一个问题,采用SmoothL1Loss进行训练。那么,RPN怎么实现呢?这个问题通过RPN的本质很好求解,RPN的本质是一个树状结构,树干是一个3×3的卷积层,树枝是两个1×1的卷积层,第一个1×1的卷积层解决了前后景的输出,第二个1×1的卷积层解决了边框修正的输出。来看看在代码中是怎么做的:


从如上代码中可以看到,对于RPN输出的特征图中的每一个点,一个1×1的卷积层输出了18个值,因为是每一个点对应9个anchor,每个anchor有一个前景分数和一个背景分数,所以9×2=18。另一个1×1的卷积层输出了36个值,因为是每一个点对应9个anchor,每个anchor对应了4个修正坐标的值,所以9×4=36。那么,要得到这些值,RPN网络需要训练。在训练的时候,就需要对应的标签。那么,如何判定一个anchor是前景还是背景呢?文中做出了如下定义:如果一个anchor与ground truth的IoU在0.7以上,那这个anchor就算前景(positive)。类似地,如果这个anchor与ground truth的IoU在0.3以下,那么这个anchor就算背景(negative)。在作者进行RPN网络训练的时候,只使用了上述两类anchor,与ground truth的IoU介于0.3和0.7的anchor没有使用。在训练anchor属于前景与背景的时候,是在一张图中,随机抽取了128个前景anchor与128个背景anchor。
在上一段中描述了前景与背景分类的训练方法,本段描述anchor边框修正的训练方法。边框修正主要由4个值完成,tx,ty,th,tw。这四个值的意思是修正后的框在anchor的x和y方向上做出平移(由tx和ty决定),并且长宽各自放大一定的倍数(由th和ty决定)。那么,如何训练网络参数得到这四个值呢?Fast R-CNN给出了答案,采用SmoothL1loss进行训练,具体可以描述为:
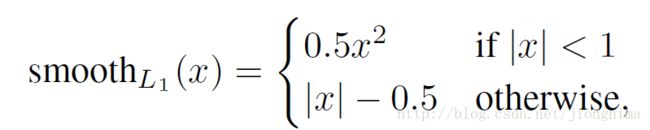
到这里有个问题,就是不是对于所有的anchor,都需要进行anchor包围框修正的参数训练,只是对positive的anchors有这一步。因此,在训练RPN的时候,只有对128个随机抽取的positive anchors有这一步训练。因此,训练RPN的损失函数可以写成:
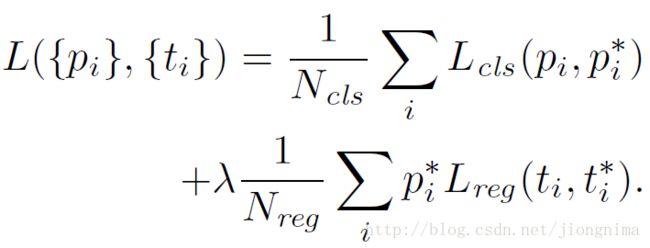
在这里Lreg就是上面的Lloc,λ被设置为10,Ncls为256,Nreg为2400。这样设置的话,RPN的两部分loss值能保持平衡。
到这里RPN就解析完毕了,下面我们来看看后面的classifier,但是在介绍classifier之前,我们先来看看RoI Pooling到底做了什么?
首先第一个问题是为什么需要RoI Pooling?答案是在Fast R-CNN中,特征被共享卷积层一次性提取。因此,对于每个RoI而言,需要从共享卷积层上摘取对应的特征,并且送入全连接层进行分类。因此,RoI Pooling主要做了两件事,第一件是为每个RoI选取对应的特征,第二件事是为了满足全连接层的输入需求,将每个RoI对应的特征的维度转化成某个定值。RoI Pooling示意图如下所示:
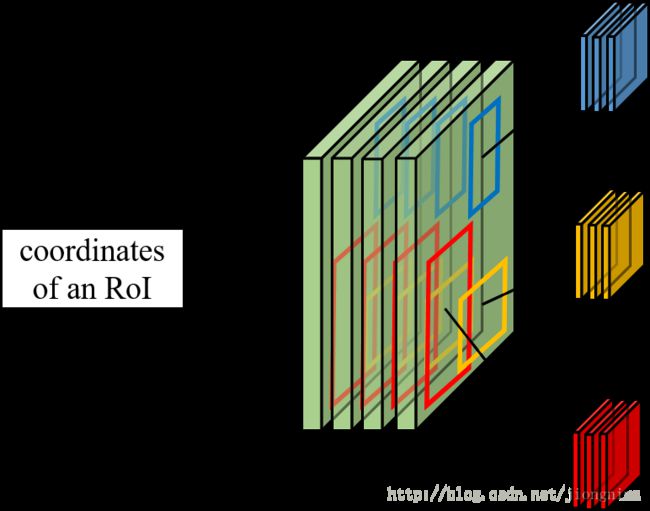
如上图所示,对于每一个RoI,RoI Pooling Layer将其对应的特征从共享卷积层上拿出来,并转化成一样的大小(6×6)。
在RoI Pooling Layer之后,就是Fast R-CNN的分类器和RoI边框修正训练。分类器主要是分这个提取的RoI具体是什么类别(人,车,马等等),一共C+1类(包含一类背景)。RoI边框修正和RPN中的anchor边框修正原理一样,同样也是SmoothL1 Loss,值得注意的是,RoI边框修正也是对于非背景的RoI进行修正,对于类别标签为背景的RoI,则不进行RoI边框修正的参数训练。对于分类器和RoI边框修正的训练,可以公式描述如下:
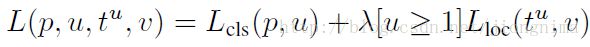
上式中u>=1表示RoI边框修正是对于非背景的RoI而言的,实验中,上式的λ取1。
在训练分类器和RoI边框修正时,步骤如下所示:
-
首先通过RPN生成约20000个anchor(40×60×9)。
-
对20000个anchor进行第一次边框修正,得到修订边框后的proposal。
-
对超过图像边界的proposal的边进行clip,使得该proposal不超过图像范围。
-
忽略掉长或者宽太小的proposal。
-
将所有proposal按照前景分数从高到低排序,选取前12000个proposal。
-
使用阈值为0.7的NMS算法排除掉重叠的proposal。
-
针对上一步剩下的proposal,选取前2000个proposal进行分类和第二次边框修正。
总的来说,Faster R-CNN的loss分两大块,第一大块是训练RPN的loss(包含一个SoftmaxLoss和SmoothL1Loss),第二大块是训练Fast R-CNN中分类器的loss(包含一个SoftmaxLoss和SmoothL1Loss),Faster R-CNN的总的loss函数描述如下:
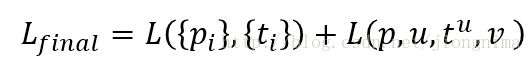
然后,对于Faster R-CNN的训练方式有三种,可以被描述如下:
-
RPN和Fast R-CNN交替训练,这种方式也是作者采用的方式。
-
近似联合RPN和Fast R-CNN的训练,在训练时忽略掉了RoI边框修正的误差,也就是说只对anchor做了边框修订,这也是为什么叫"近似联合"的原因。
-
联合RPN和Fast R-CNN的训练。
对于作者采用的交替训练的方式,步骤如下:
-
使用在ImageNet上预训练的模型初始化共享卷积层并训练RPN。
-
使用上一步得到的RPN参数生成RoI proposal。再使用ImageNet上预训练的模型初始化共享卷积层,训练Fast R-CNN部分(分类器和RoI边框修订)。
-
将训练后的共享卷积层参数固定,同时将Fast R-CNN的参数固定,训练RPN。(从这一步开始,共享卷积层的参数真正被两大块网络共享)
-
同样将共享卷积层参数固定,并将RPN的参数固定,训练Fast R-CNN部分。
Faster R-CNN的测试流程和训练流程挺相似,描述如下:
-
首先通过RPN生成约20000个anchor(40×60×9)通过RPN。
-
对20000个anchor进行第一次边框修正,得到修订边框后的proposal。
-
对超过图像边界的proposal的边进行clip,使得该proposal不超过图像范围。
-
忽略掉长或者宽太小的proposal。
-
将所有proposal按照前景分数从高到低排序,选取前6000个proposal。
-
使用阈值为0.7的NMS算法排除掉重叠的proposal。
-
针对上一步剩下的proposal,选取前300个proposal进行分类和第二次边框修正。
到这里,Faster R-CNN就介绍完毕了。接下来到了Mask R-CNN,我们来看看RoI Pooling出了什么问题:
问题1:从输入图上的RoI到特征图上的RoI feature,RoI Pooling是直接通过四舍五入取整得到的结果。
这一点可以在代码中印证:

可以看到直接用round取的值,这样会带来什么坏处呢?就是RoI Pooling过后的得到的输出可能和原图像上的RoI对不上,如下图所示:

右图中蓝色部分表示包含了轿车主体的的信息的方格,RoI Pooling Layer的四舍五入取整操作导致其进行了偏移。
问题2:再将每个RoI对应的特征转化为固定大小的维度时,又采用了取整操作。在这里笔者举例讲解一下RoI Pooling的操作:
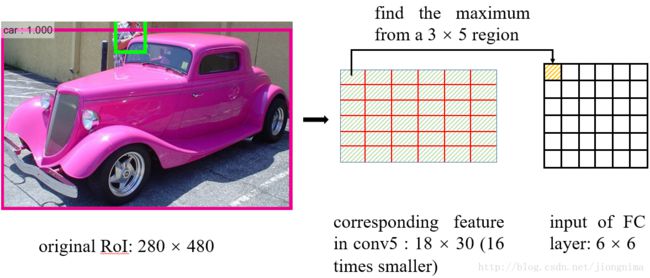
在从RoI得到对应的特征图时,进行了问题1描述的取整,在得到特征图后,如何得到一个6×6的全连接层的输入呢?RoI Pooling这样做:将RoI对应的特征图分成6×6块,然后直接从每块中找到最大值。在上图中的例子中,比如原图上的的RoI大小是280×480,得到对应的特征图是18×30。将特征图分成6块,每块大小是3×5,然后在每一块中分别选择最大值放入6×6的对应区域中。在将特征图分块的时候,又用到了取整,这点同样可以在代码中得到佐证:

这种取整操作(在Mask R-CNN中被称为quantization)对RoI分类影响不大,可是对逐像素的预测目标是有害的,因为对每个RoI取得的特征并没有与RoI对齐。因此,Mask R-CNN对RoI Pooling做了改进并提出了RoI Align。
RoI Align的主要创新点是,针对问题1,不再进行取整操作。针对问题2,使用双线性插值来更精确地找到每个块对应的特征。总的来说,RoI Align的作用主要就是剔除了RoI Pooling的取整操作,并且使得为每个RoI取得的特征能够更好地对齐原图上的RoI区域。
下图阐述了Mask R-CNN的Mask branch:

在Mask R-CNN中的RoI Align之后有一个"head"部分,主要作用是将RoI Align的输出维度扩大,这样在预测Mask时会更加精确。在Mask Branch的训练环节,作者没有采用FCN式的SoftmaxLoss,反而是输出了K个Mask预测图(为每一个类都输出一张),并采用average binary cross-entropy loss训练,当然在训练Mask branch的时候,输出的K个特征图中,也只是对应ground truth类别的那一个特征图对Mask loss有贡献。
Mask R-CNN的训练损失函数可以描述为:

在上式中,Lbox和Lmask都是对positive RoI才会起作用的。
在Mask R-CNN中,相较于Faster R-CNN还有些略微的调整,比如positive RoI被定义成了与Ground truth的IoU大于0.5的(Faster R-CNN中是0.7)。太过于细节的东西本篇博文不再赘述,详情参见Mask R-CNN中的Implementation Details。
到这里再将Mask R-CNN和FCIS做个比较,首先两者的相同点是均继承了Faster R-CNN的RPN部分。不同点是对于FCIS,预测mask和分类是共享的参数。而Mask R-CNN则是各玩各的,两个任务各自有各自的可训练参数。对于这一点,Mask R-CNN论文里还专门作了比较,显示对于预测mask和分类如果使用共享的特征图对于某些重叠目标可能会出现问题。
Mask R-CNN的实验取得了很好的效果,达到甚至超过了state-of-the-art的水平。不过训练代价也是相当大的,需要8块GPU联合训练。
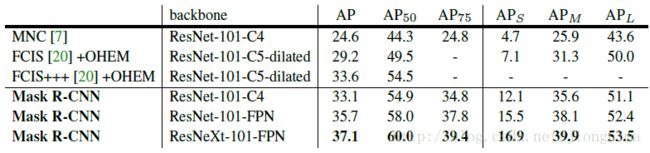
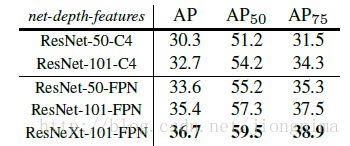
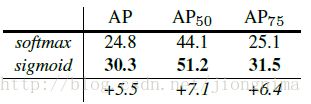
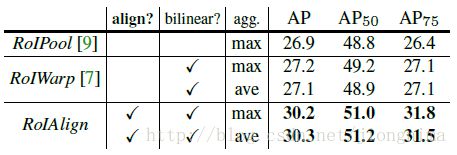
Mask R-CNN的实验非常详细,还做了很多对比实验,比如说改换网络深度,在训练mask branch时的误差种类,将RoI Align同RoI Pooling和RoI Warping进行比较,改变预测mask的方式(FCN和全连接层)等,详情请参见Mask R-CNN的实验部分。

到这里Mask R-CNN介绍就结束了。
Respect
本文为CSDN博主「jiongnima」的原创文章,我只是个搬运工,方便以后自己的学习和回顾。原文链接:https://blog.csdn.net/jiongnima/article/details/79094159