MyCat数据库中间件的取舍问题
Mycat从入门到放弃
当初写这篇文章的初衷只是想提醒自己在用一个开源产品前不仅要了解其提供的功能,更要了解其功能和场景边界。
1.非分片字段查询
Mycat中的路由结果是通过分片字段和分片方法来确定的。例如下图中的一个Mycat分库方案:
- 根据 tt_waybill 表的 id 字段来进行分片
- 分片方法为 id 值取 3 的模,根据模值确定在DB1,DB2,DB3中的某个分片
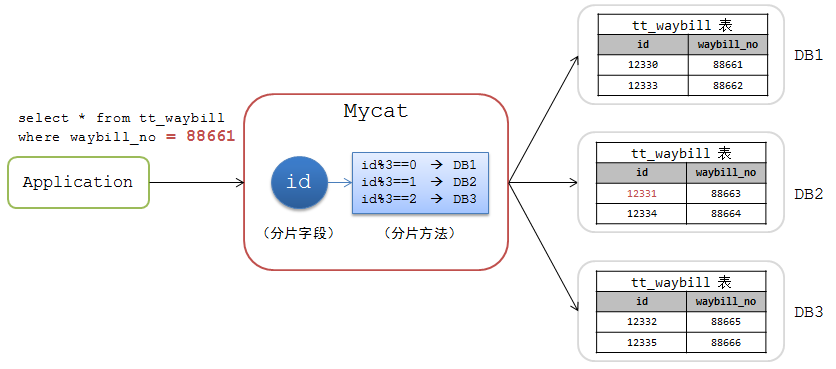
如果查询条件中有 id 字段的情况还好,查询将会落到某个具体的分片。例如:
mysql>select * from tt_waybill where id = 12330;
此时Mycat会计算路由结果
12330 % 3 = 0 –> DB1
并将该请求路由到DB1上去执行。
如果查询条件中没有 分片字段 条件,例如:
mysql>select * from tt_waybill where waybill_no =88661;
此时Mycat无法计算路由,便发送到所有节点上执行:
DB1 –> select * from tt_waybill where waybill_no =88661;
DB2 –> select * from tt_waybill where waybill_no =88661;
DB3 –> select * from tt_waybill where waybill_no =88661;
如果该分片字段选择度高,也是业务常用的查询维度,一般只有一个或极少数个DB节点命中(返回结果集)。示例中只有3个DB节点,而实际应用中的DB节点数远超过这个,假如有50个,那么前端的一个查询,落到MySQL数据库上则变成50个查询,会极大消耗Mycat和MySQL数据库资源。
如果设计使用Mycat时有非分片字段查询,请考虑放弃!
2.分页排序
先看一下Mycat是如何处理分页操作的,假如有如下Mycat分库方案:
一张表有30份数据分布在3个分片DB上,具体数据分布如下
DB1:[0,1,2,3,4,10,11,12,13,14]
DB2:[5,6,7,8,9,16,17,18,19]
DB3:[20,21,22,23,24,25,26,27,28,29]
(这个示例的场景中没有查询条件,所以都是全分片查询,也就没有假定该表的分片字段和分片方法)
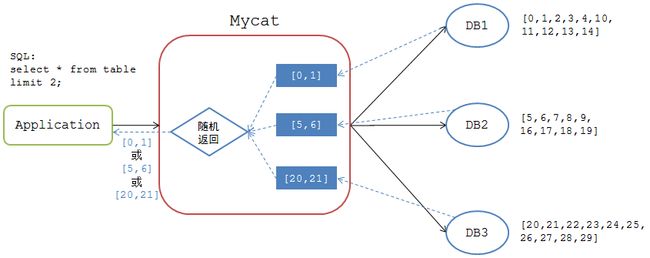
当应用执行如下分页查询时
mysql>select * from table limit 2;
Mycat将该SQL请求分发到各个DB节点去执行,并接收各个DB节点的返回结果
DB1: [0,1]
DB2: [5,6]
DB3: [20,21]
但Mycat向应用返回的结果集取决于哪个DB节点最先返回结果给Mycat。如果Mycat最先收到DB1节点的结果集,那么Mycat返回给应用端的结果集为 [0,1],如果Mycat最先收到DB2节点的结果集,那么返回给应用端的结果集为 [5,6]。也就是说,相同情况下,同一个SQL,在Mycat上执行时会有不同的返回结果。
在Mycat中执行分页操作时必须显示加上排序条件才能保证结果的正确性,下面看一下Mycat对排序分页的处理逻辑。
假如在前面的分页查询中加上了排序条件(假如表数据的列名为id)
mysql>select * from table order by id limit 2;
Mycat的处理逻辑如下图:
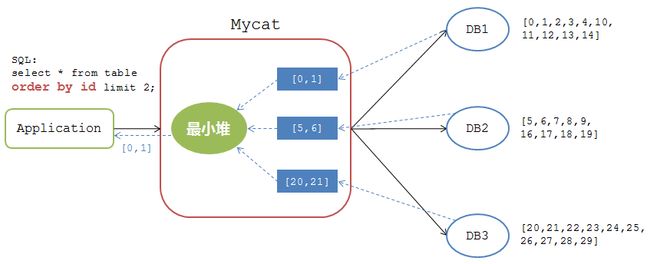
在有排序呢条件的情况下,Mycat接收到各个DB节点的返回结果后,对其进行最小堆运算,计算出所有结果集中最小的两条记录 [0,1] 返回给应用。
但是,当排序分页中有 偏移量 (offset)时,处理逻辑又有不同。假如应用的查询SQL如下:
mysql>select * from table order by id limit 5,2;
如果按照上述排序分页逻辑来处理,那么处理结果如下图:
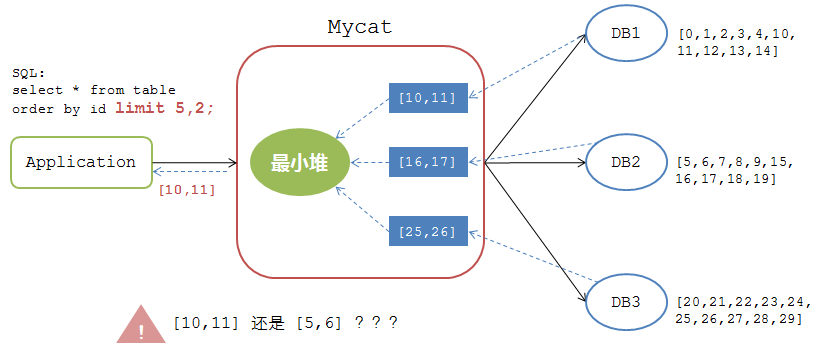
Mycat将各个DB节点返回的数据 [10,11], [16,17], [20,21] 经过最小堆计算后返回给应用的结果集是 [10,11]。可是,对于应用而言,该表的所有数据明明是 0-29 这30个数据的集合,limit 5,2 操作返回的结果集应该是 [5,6],如果返回 [10,11] 则是错误的处理逻辑。
所以Mycat在处理 有偏移量的排序分页 时是另外一套逻辑——改写SQL 。如下图:
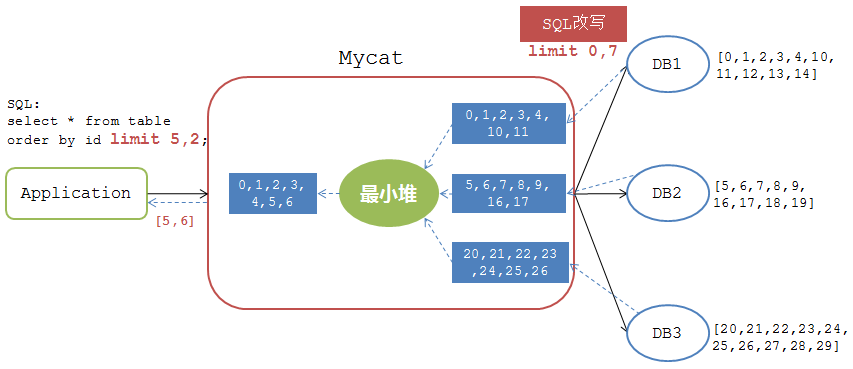
Mycat在下发有 limit m,n 的SQL语句时会对其进行改写,改写成 limit 0, m+n 来保证查询结果的逻辑正确性。所以,Mycat发送到后端DB上的SQL语句是
mysql>select * from table order by id limit 0,7;
各个DB返回给Mycat的结果集是
DB1: [0,1,2,3,4,10,11]
DB2: [5,6,7,8,9,16,17]
DB3: [20,21,22,23,24,25,26]
经过最小堆计算后得到最小序列 [0,1,2,3,4,5,6] ,然后返回偏移量为5的两个结果为 [5,6] 。
虽然Mycat返回了正确的结果,但是仔细推敲发现这类操作的处理逻辑是及其消耗(浪费)资源的。应用需要的结果集为2条,Mycat中需要处理的结果数为21条。也就是说,对于有 t 个DB节点的全分片 limit m, n 操作,Mycat需要处理的数据量为 (m+n)*t 个。比如实际应用中有50个DB节点,要执行limit 1000,10操作,则Mycat处理的数据量为 50500 条,返回结果集为10,当偏移量更大时,内存和CPU资源的消耗则是数十倍增加。
如果设计使用Mycat时有分页排序,请考虑放弃!
3.任意表JOIN
先看一下在单库中JOIN中的场景。假设在某单库中有 player 和 team 两张表,player 表中的 team_id 字段与 team 表中的 id 字段相关联。操作场景如下图:
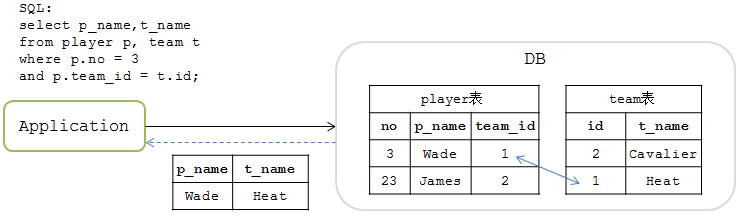
JOIN操作的SQL如下
mysql>select p_name,t_name from player p, team t where p.no = 3 and p.team_id = t.id;
此时能查询出结果
| p_name | t_name |
|---|---|
| Wade | Heat |
如果将这两个表的数据分库后,相关联的数据可能分布在不同的DB节点上,如下图:
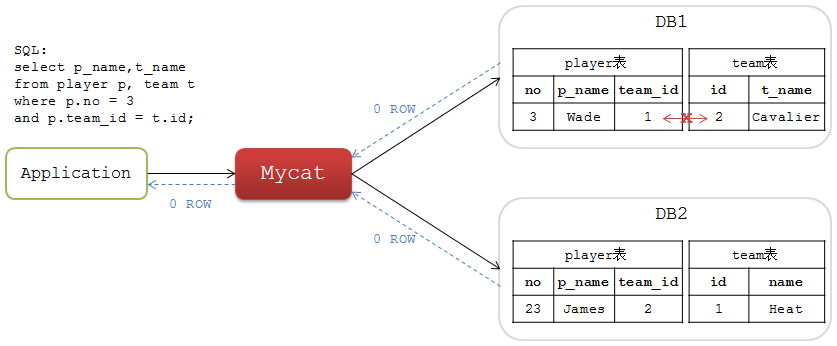
这个SQL在各个单独的分片DB中都查不出结果,也就是说Mycat不能查询出正确的结果集。
设计使用Mycat时如果要进行表JOIN操作,要确保两个表的关联字段具有相同的数据分布,否则请考虑放弃!
4.分布式事务
Mycat并没有根据二阶段提交协议实现 XA事务,而是只保证 prepare 阶段数据一致性的 弱XA事务 ,实现过程如下:
应用开启事务后Mycat标识该连接为非自动提交,比如前端执行
mysql>begin;
Mycat不会立即把命令发送到DB节点上,等后续下发SQL时,Mycat从连接池获取非自动提交的连接去执行。
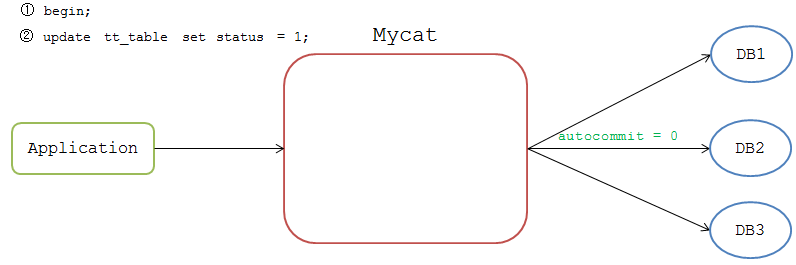
Mycat会等待各个节点的返回结果,如果都执行成功,Mycat给该连接标识为 Prepare Ready 状态,如果有一个节点执行失败,则标识为 Rollback 状态。
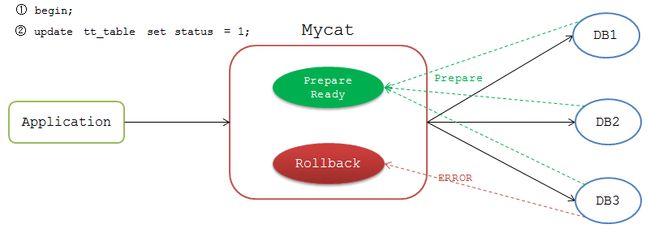
执行完成后Mycat等待前端发送 commit 或 rollback 命令。发送 commit 命令时,Mycat检测当前连接是否为 Prepare Ready 状态,若是,则将 commit 命令发送到各个DB节点。
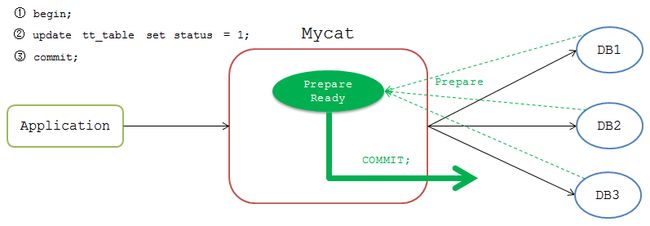
但是,这一阶段是无法保证一致性的,如果一个DB节点在 commit 时故障,而其他DB节点 commit 成功,Mycat会一直等待故障DB节点返回结果。Mycat只有收到所有DB节点的成功执行结果才会向前端返回 执行成功 的包,此时Mycat只能一直 waiting 直至TIMEOUT,导致事务一致性被破坏。
设计使用Mycat时如果有分布式事务,得先看是否得保证事务得强一致性,否则请考虑放弃!
https://blog.csdn.net/u013235478/article/details/53178657
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013235478/article/details/53178657

hq333
2017-03-21 03:14#5楼2条回复 回复-
上面提到的,PostgreSQL 可以胜任,只是国内不流行
-
-
hq333
2017-11-08 21:16-
回复hq333:如,Greenplum是开源的PostgreSQL 分布式数据库完全支持ANSI SQL 2008标准和SQL OLAP 2003 扩展;支持分布式事务,保证数据的强一致性。
不过,下面的摘自网上:
Consistency(一致性), 数据一致更新,所有数据变动都是同步的
Availability(可用性), 好的响应性能
Partition tolerance(分区容错性) 可靠性
定理:任何分布式系统只可同时满足二点,没法三者兼顾。
忠告:架构师不要将精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。

Evenin
2017-03-09 08:50#4楼回复-
严格来说,这不只是mycat的缺陷,是目前所有分库分表中间件的缺陷。要使用分库分表,设计上要有考量的。

Devil_May_Crying
2017-05-31 17:14#8楼1条回复 回复-
这位师兄,看了您的博客以后,我进入了mycat6群,提出您说的分页问题,群里的答案是,分页需要加入分片,您的写法错误导致消耗内存。不知道是个啥情况。我今天刚下mycat权威指南,希望师兄别介意我的问题。也希望收到师兄的回复。谢谢

u013235478
2017-05-31 18:23-
回复Devil_May_Crying:我说的这种场景是需要排序的分页,别人说分页需要加入分片,可能是没有顺序要求的场景

elonpage
2017-09-23 19:01#10楼回复-
关于第三点,1.6版本的mycat是可以实现的。mycat有一个叫做catlet的功能,可以实现跨库任意表JOIN。
例如team,player表在不同的库,在查询的时候加上注释就可以查询到所需要的数据了。
- /*!mycat:catlet=io.mycat.catlets.ShareJoin */SELECT * from test_02 team,test_03 player ON team.id=player.team_id;
-

-
wanghuawei19930812
2018-03-19 15:30#15楼回复-
设计使用Mycat时如果有分布式事务,得先看是否得保证事务得强一致性,否则请考虑放弃!
-

-
bandaoyu
2018-03-09 09:35#14楼回复-
mycat1.6 有嵌套查询,子查询不支持切分到对应的库bug,查询发现很慢,explain查看竟然子查询跑到所有的分库去执行了一遍。
现在项目的主创团队精力似乎都在创业上了,官方维护和更新已经在1年前,提bug也无动于衷,感觉这个项目要慢慢衰落,也准备放弃
-

-
Lsmacha
2018-01-11 13:31#13楼1条回复 回复-
请问楼主:有无调研过其他开源的数据库分库分表中间件,他们又是如何解决上述问题的?