大数据 爬取网站并分析数据
大数据+爬取前程无忧校园招聘+flume+hive+mysql+数据可视化
- 自己搭建的hadoop博客
- 1.爬取前程无忧网页和校园招聘
- 1.1用scrapy爬取前途无忧网站,我爬了10w多条数据,在存入MongoDB中.
- 1.2.存入Mogodb中,设置管道和setting.
- 1.3.从cmd里面mogodb/bin目录下导出数据
- 1.3.1 导出命令
- 1.3.2 对导出数据做清洗
- 2.我对文件清洗过后变为txt文件.传入linux中
- 2.1转换格式问题,我的数据从138MB变为了100MB.
- 2.2通过flume向hdfs传输数据,创建qiangcheng.conf文件,写入flume传输代码.
- 2.3遇到报错信息,由于日志信息过大.
- 2.4解决方案:
- 2.5可以看到我上传的文件.
- 2.5.1 对上传的数据进行合并
- 2.5.2对合并的文件修改文件名为qiangc.
- 2.5.3 下载hdfs上的文件我们可以看到数据以制表符为分隔,我改成了以" ` "这个符号分隔.
- 2.6 重新上传一遍以" ` "分隔符来对数据进行分隔. 在对hdfs文件进行改写.上传分隔好的数据.在传入flume中.
- 2.7对数据进行清洗后.在hive中创建数据表.
- 3.对hdfs中清洗的数据,创建表导入hdfs上的数据.
- 3.2从hdfs导入数据到hive,导入数据成功.
- 4.创建caiji表装自己想要的数据,来装取数据采集表
- 4.1 可以看到我们获得的数据.
- 5.把大数据工程师的数据插入到数据caiji当中.
- 5.1导入大数据工程师数据成功
- 5.1.2查看大数据工程师的数据.
- 6.把数据分析的数据插入到数据表caiji当中.
- 6.1插入数据分析成功
- 6.1.2查看我们的采集表(有数据、大数据工程师、数据分析).
- 7.现在对caiji表进行分析.
- 7.1我们要对jobmoney的工资进行数据分析.
- 7.1.1分析"数据分析","大数据开发工程师","数据采集"等岗位的平均工资、最高工资、最低工资,做条形图展示.
- 7.1.2创建一个表用来计算所有数据的最大值、最小值、平均值.
- 7.1.3通过查看所有数据,发现jobmoney数据有为null的数据,所以对jobmoney为null的数据不要.
- 7.1.4 修改jobmoney为null的数据成功.
- 7.1.5计算数据分析的工资.
- 7.1.6由于数据少对数据进行模糊查询.
- 7.1.7可以的三个数据的最高工资、最低工资、和平均工资.
- 7.1.8我们创建三个表,来看个给地区的岗位数.
- 7.1.9我们来看各个地区的岗位数.
- 7.1.10 数据分析岗位数
- 7.1.11 大数据分析师岗位数
- 7.1.12 数据采集岗位数
- 8.我们来看工作个几年工作经验计算工资.
- 8.1 创建几年工资经验表(sannianggongzi).
- 8.2 把数据重dashujujingyan插入到sannianggongzi表
- 8.2.1 查看大数据岗位三年工资数据.
- 9.分析大数据岗位需求,查看大数据走向,做折线图展示.
- 9.1 创建数据表
- 9.2 查看数据表的内容
- 10.hive导入数据到HDFS
- 10.1hive上传到hdfs
- 11.利用sqoop传入到mysql
- 11.1连接我的本地mysql
- 11.2创将数据表
- 11.3利用sqoop上传到mysql上.
- 11.3.1 sqoop导入mysql数据表
- 12.数据可视化
- 12.1 三年工资薪资图
- 12.2 数据分析饼图岗位地区个数
- 12.3 大数据岗位分析图
- 12.4 数据采集
- 12.5 大数据1-3年经验工资
- 12.3 折线图
- 13.总结
自己搭建的hadoop博客
我搭建了hadopp伪分布式和分布式,记录在我的博客中
伪分布式链接:https://blog.csdn.net/ysy_1_2/article/details/106615430
完全分布式链接:https://blog.csdn.net/ysy_1_2/article/details/106260140
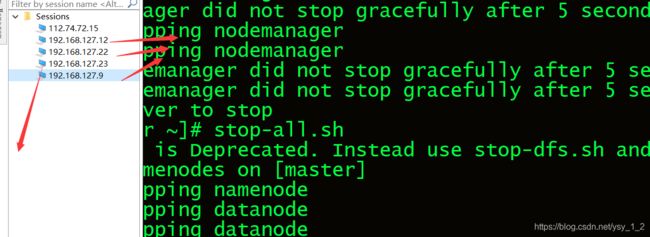
1.爬取前程无忧网页和校园招聘
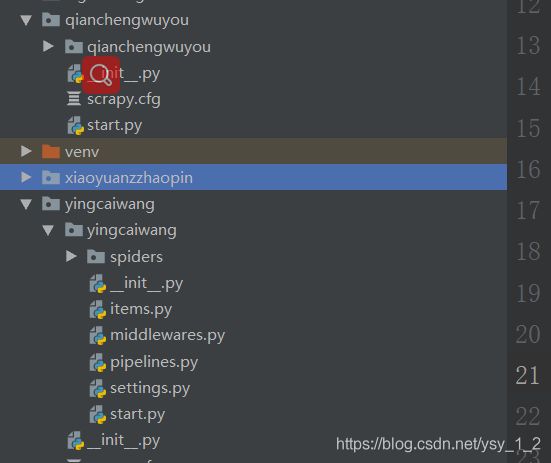
1.1用scrapy爬取前途无忧网站,我爬了10w多条数据,在存入MongoDB中.
# -*- coding: utf-8 -*-
import scrapy
from qianchengwuyou.items import QianchengwuyouItem
class QiangchengSpider(scrapy.Spider):
name = 'qiangcheng'
allowed_domains = ['51job.com']
start_urls = ["https://search.51job.com/list/000000,000000,0000,00,9,99,%2520,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="]
def parse(self, response):
job_list = response.xpath("//div[@class='dw_table']//div[@class='el']/p[1]//span/a/@href").getall()
for i_items in job_list:
yield scrapy.Request(url=i_items,callback=self.jiexi_content,dont_filter=True)
#获取下一页的href
next_pages = response.xpath("//div[@class='p_in']//li[last()]/a/@href").get()
if next_pages:
yield scrapy.Request(url=next_pages,callback=self.parse,dont_filter=True)
def jiexi_content(self,response):
item = QianchengwuyouItem()
item['job_name'] = response.xpath("//div[@class='cn']/h1/text()").extract_first()
try:
item['job_money'] = response.xpath("//div[@class='cn']/strong/text()").extract_first()
except:
item['job_money'] = "面议"
item['job_company'] = response.xpath("//div[@class='cn']//a[1]/text()").extract_first()
#抓取所有工作地点和教育程度
job_all = response.xpath("//div[@class='cn']//p[2]/text()").getall()
#对抓取的列表进行分割取出,列表中包含了工作地点和工作经历和教育程度.
try:
item['job_place'] = job_all[0].strip()
except:
item['job_place'] = ""
try:
item['job_experience'] = job_all[1].strip()
except:
item['job_experience'] = '无要求'
try:
item['job_education'] = job_all[2].strip()
except:
item['job_education'] = '不要求'
#对所有岗位职责和任务进行提取,都爬取了的,爬取的岗位职责和任职要求
job_content = response.xpath("//div[@class='bmsg job_msg inbox']/p/text()").getall()
job_nz = []
#遍历循环取得岗位职责和任职要求的数据添加到job_nz[]中,在取出数据.
for job_nzs in job_content:
job_nz.append(job_nzs)
try:
item['job_nz'] = job_nz
except:
item['job_nz'] = "上岗安排"
yield item
校园招聘

1.2.存入Mogodb中,设置管道和setting.
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
class QianchengwuyouPipeline:
def __init__(self):
pass
# 链接数据库
client = pymongo.MongoClient(host=settings['MONGO_HOST'], port=settings['27017'])
self.db = client[settings['MONGO_DB']] # 获得数据库的句柄
self.coll = self.db[settings['MONGO_COLL']] # 获得collection的句柄
#数据库登录需要账号密码的话
#self.db.authenticate(settings['MONGO_USER'], settings['MONGO_PSW'])
def process_item(self, item, spider):
pass
postItem = dict(item) # 把item转化成字典形式
self.coll.insert(postItem) # 向数据库插入一条记录
return item # 会在控制台输出原item数据,可以选择不写
def close(self):
close.client.close()
setting中设置

1.3.从cmd里面mogodb/bin目录下导出数据
1.3.1 导出命令
mongoexport -d dbname(你的数据库名) -c user(要导出的表) -f locations(要导出的字段) --type=csv -o D:\我导入的是当前目录(你要导入的目录).
其中,"d"是使用Mongo数据库,"c"指的是数据库集合(也就是数据库表),"f"指的是域(也就是要导出的数据字段),"0"指的是csv文件的输出路径.
1.3.2 对导出数据做清洗
导出csv文件,对文件作出清洗

2.我对文件清洗过后变为txt文件.传入linux中
在我的主机创建data文件夹,存入txt文件.
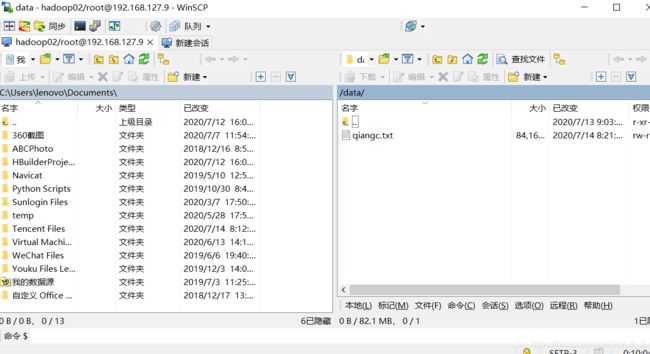
2.1转换格式问题,我的数据从138MB变为了100MB.

2.2通过flume向hdfs传输数据,创建qiangcheng.conf文件,写入flume传输代码.
flume命令:
./flume-ng agent -n a1 -c ../conf -f ../conf/qiangcheng.conf -Dflume.root.logger=INFO,console
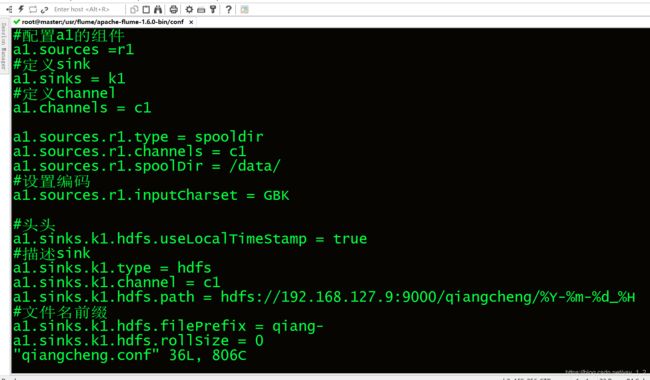
2.3遇到报错信息,由于日志信息过大.
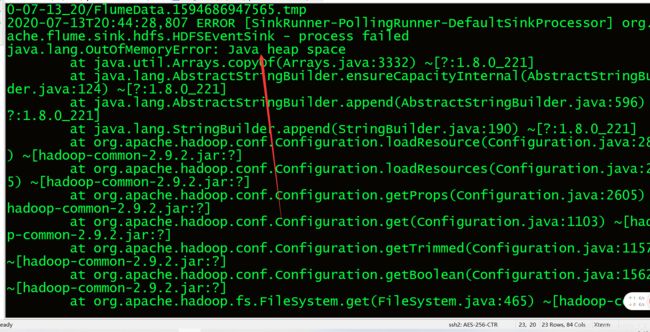
2.4解决方案:
在lfume下的conf/flume-env.sh下文件添加:
export JAVA_OPTS="-Xms512m -Xmx1024m -Dcom.sun.management.jmxremote"

2.5可以看到我上传的文件.
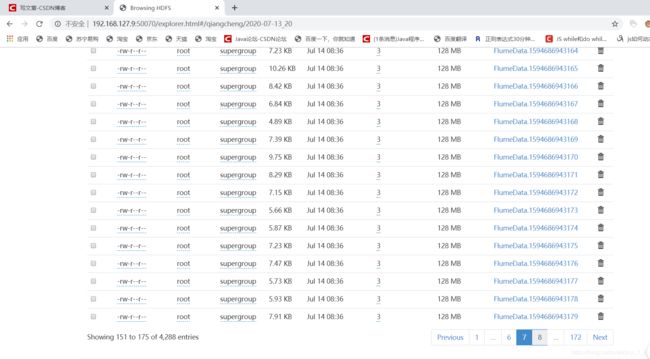
2.5.1 对上传的数据进行合并
hadoop fs -cat /qiangcheng/2020-07-13_21/* | hadoop fs -put - /qiangcheng/2020-07-13_21
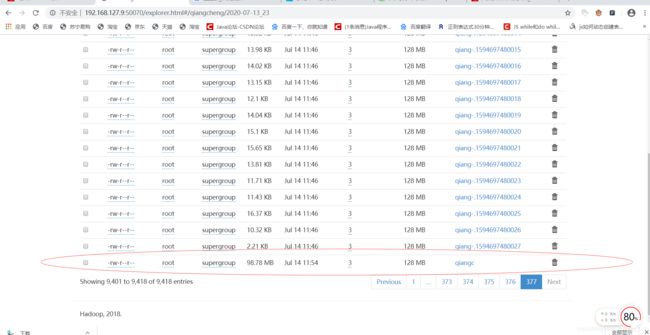
2.5.2对合并的文件修改文件名为qiangc.

2.5.3 下载hdfs上的文件我们可以看到数据以制表符为分隔,我改成了以" ` "这个符号分隔.
修改前:

修改后:

2.6 重新上传一遍以" ` "分隔符来对数据进行分隔. 在对hdfs文件进行改写.上传分隔好的数据.在传入flume中.
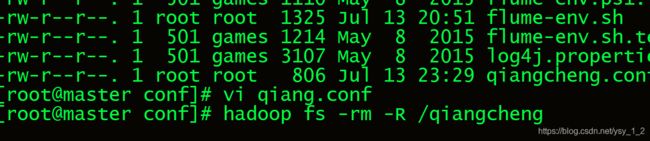
2.7对数据进行清洗后.在hive中创建数据表.

create table qiangcheng(
id varchar(30),
jobname varchar(30),
jobmoney int,
jobcompany varchar(30),
jobdate DATE,
jobplace varchar(30),
jobexperience varchar(30),
jobneirong varchar(2000))
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties('input.regex'='(.*)`(.*)`(.*)`(.*)`(.*)`(.*)`(.*)`(.*)',
'output.format.string'='%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s %10$s %11$s')
stored as textfile;
3.对hdfs中清洗的数据,创建表导入hdfs上的数据.
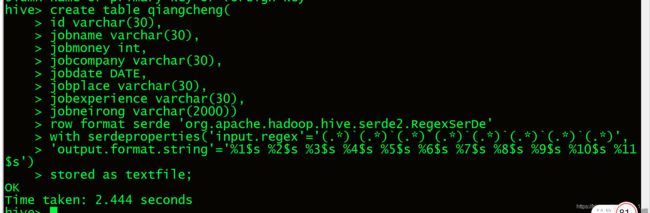
3.2从hdfs导入数据到hive,导入数据成功.

4.创建caiji表装自己想要的数据,来装取数据采集表
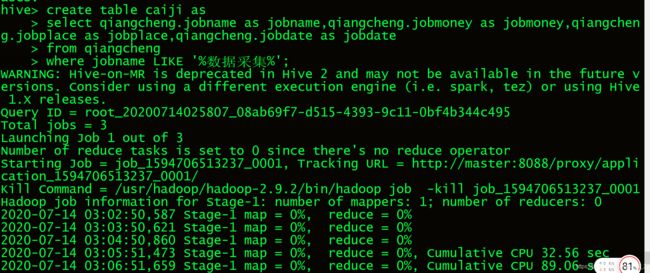
4.1 可以看到我们获得的数据.

5.把大数据工程师的数据插入到数据caiji当中.

5.1导入大数据工程师数据成功

5.1.2查看大数据工程师的数据.
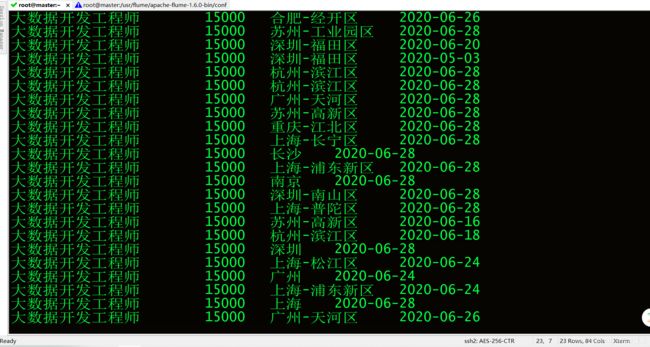
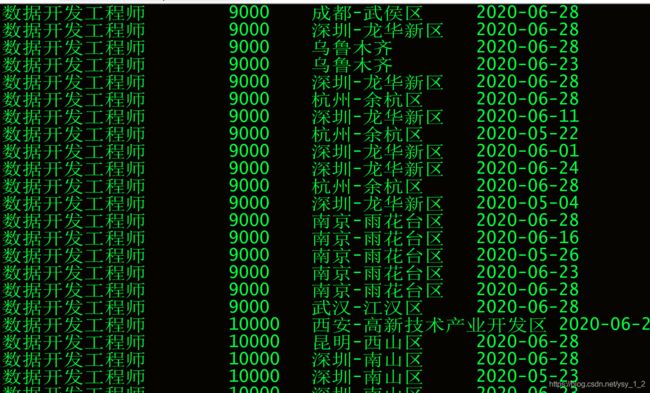
6.把数据分析的数据插入到数据表caiji当中.
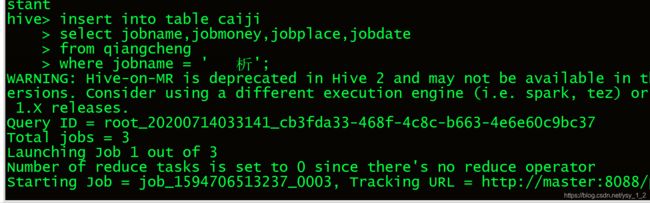
6.1插入数据分析成功

6.1.2查看我们的采集表(有数据、大数据工程师、数据分析).
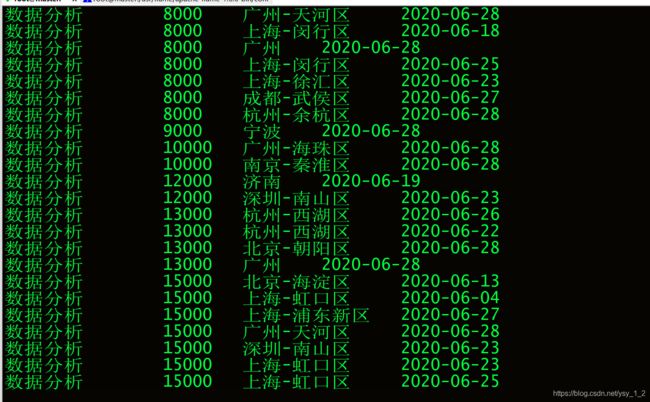
7.现在对caiji表进行分析.
7.1我们要对jobmoney的工资进行数据分析.
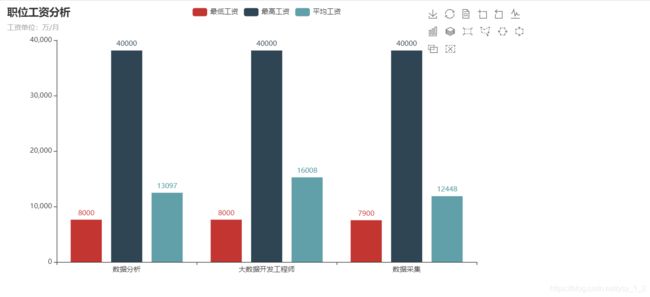
7.1.1分析"数据分析",“大数据开发工程师”,"数据采集"等岗位的平均工资、最高工资、最低工资,做条形图展示.
7.1.2创建一个表用来计算所有数据的最大值、最小值、平均值.

7.1.3通过查看所有数据,发现jobmoney数据有为null的数据,所以对jobmoney为null的数据不要.

7.1.4 修改jobmoney为null的数据成功.
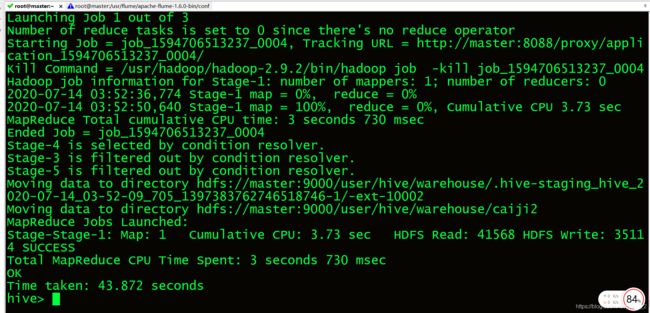
7.1.5计算数据分析的工资.
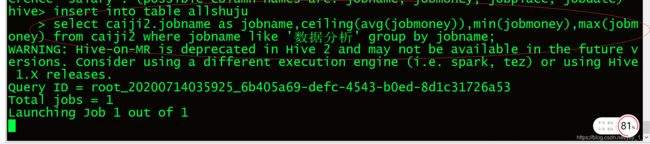
7.1.6由于数据少对数据进行模糊查询.
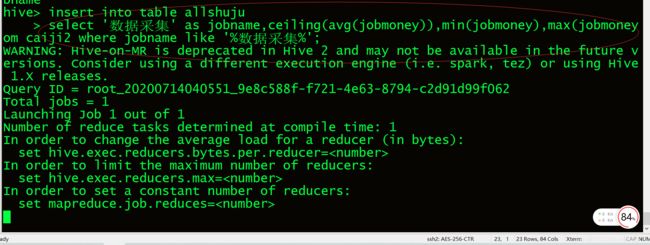
7.1.7可以的三个数据的最高工资、最低工资、和平均工资.

7.1.8我们创建三个表,来看个给地区的岗位数.
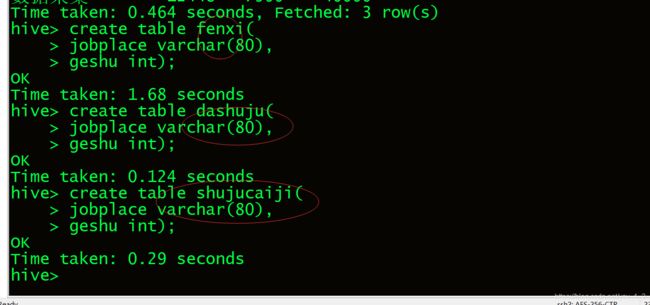
7.1.9我们来看各个地区的岗位数.

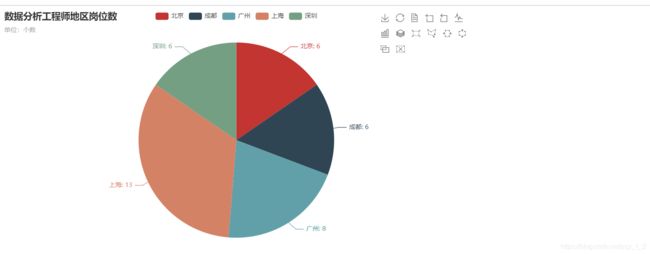
7.1.10 数据分析岗位数

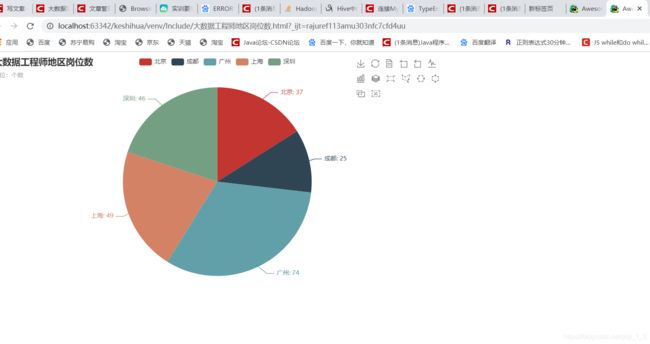
7.1.11 大数据分析师岗位数
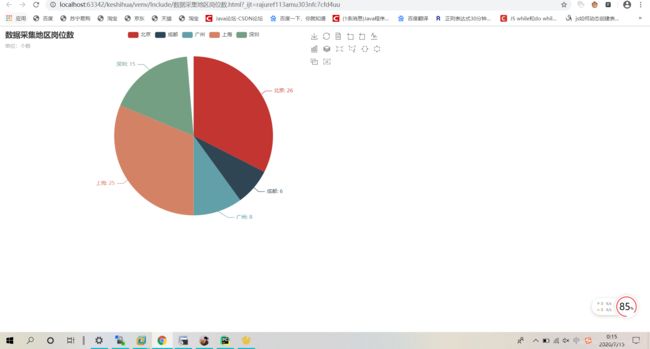
7.1.12 数据采集岗位数
8.我们来看工作个几年工作经验计算工资.
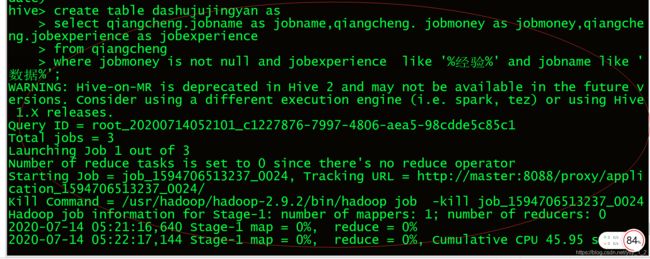
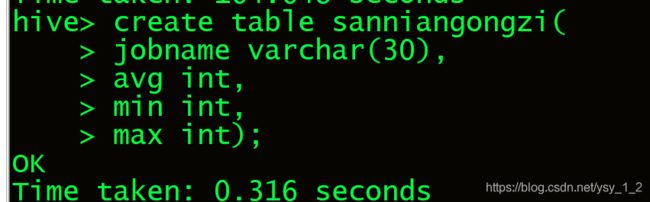
8.1 创建几年工资经验表(sannianggongzi).
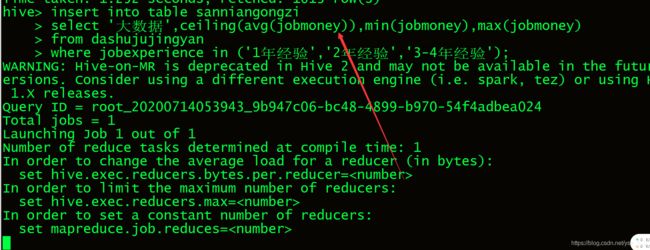
8.2 把数据重dashujujingyan插入到sannianggongzi表
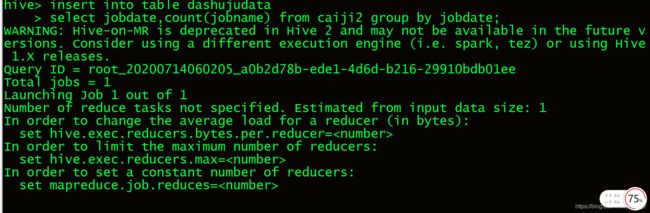
8.2.1 查看大数据岗位三年工资数据.

9.分析大数据岗位需求,查看大数据走向,做折线图展示.
9.1 创建数据表

把数据分割
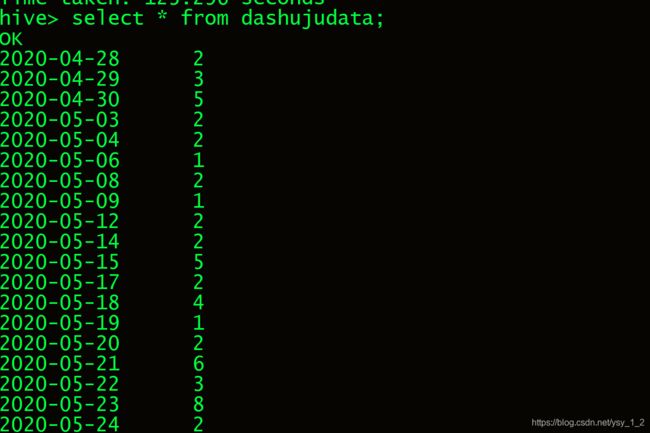
9.2 查看数据表的内容
10.hive导入数据到HDFS
以下是我的数据
caiji 是大数据工程和数据分析和数据采集
allshuju 是三个数据采集和数据开发的平均最低最高工资
dashuju 是大数据各地区岗位个数
fenxi 是数据分析各个岗位的个数
shujucaiji 是数据采集岗位个数
dashujujingyang 是大数据三年经验
dashujudata 日期是几年的折线图
sannianggongzi 是大数据三年的工资
select * from hive_db; --> 需要导出的内容
# 数据分析表饼图
insert overwrite directory '/qiangcheng/1'
row format delimited fields terminated by '\t'
select * from fenxi;
#大数据开发工程师饼图
insert overwrite directory '/qiangcheng/2'
row format delimited fields terminated by '\t'
select * from dashuju;
# 数据采集饼图
insert overwrite directory '/qiangcheng/3'
row format delimited fields terminated by '\t'
select * from shujucaiji ;
#1-3年
insert overwrite directory '/qiangcheng/4'
row format delimited fields terminated by '\t'
select * from sanniangongzi;
# 三个职业薪资水平
insert overwrite directory '/qiangcheng/5'
row format delimited fields terminated by '\t'
select * from allshuju
# 带日期的表
insert overwrite directory '/qiangcheng/6'
row format delimited fields terminated by '\t'
select * from dashujudata
10.1hive上传到hdfs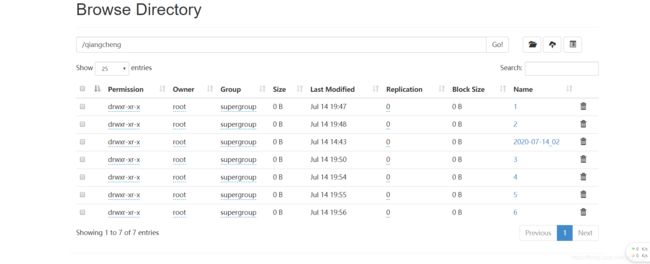
11.利用sqoop传入到mysql
11.1连接我的本地mysql
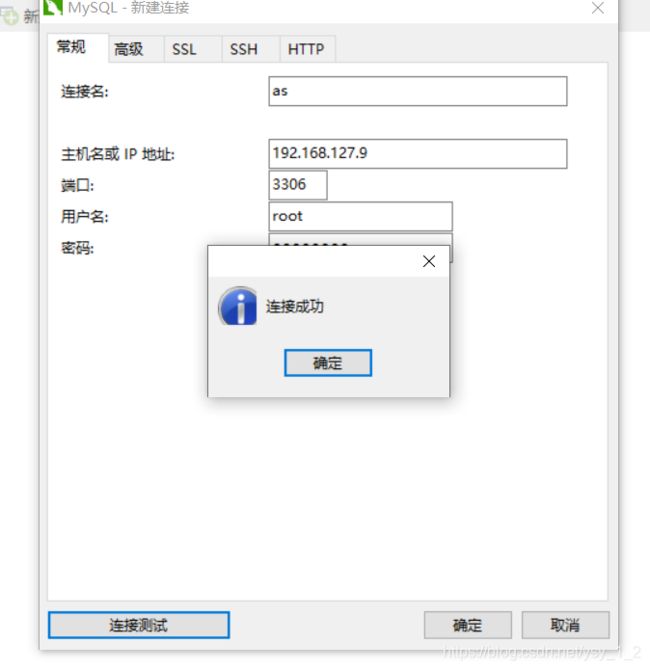
11.2创将数据表
11.3利用sqoop上传到mysql上.
命令
sqoop export --connect jdbc:mysql://127.0.0.1:3306/qianc --username root --password 12345678 --table dashujugongchengshi --export-dir '/qiangcheng/2' --fields-terminated-by '\t' -m 1

11.3.1 sqoop导入mysql数据表
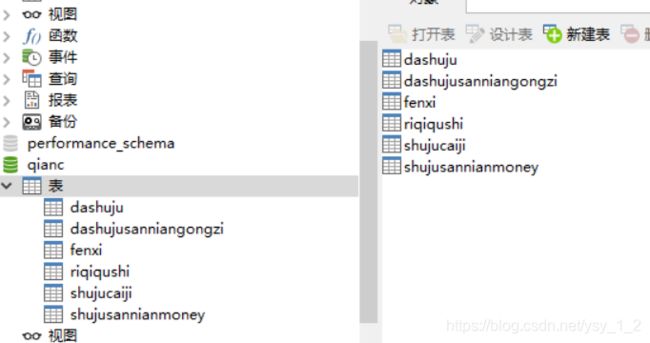
12.数据可视化
import pymysql
from pyecharts.charts import Bar
from pyecharts import options as opts
db = pymysql.connect(host="192.168.127.9",port=3306,database="qianc",user='root',password='12345678')
cursor = db.cursor()
sql = "select * from shujusannianmoney"
cursor.execute(sql)
data = cursor.fetchall()
print(data)
jobname = [data[0][0], data[1][0], data[2][0]]
print(jobname)
min_list = [data[0][2], data[1][2], data[2][2]]
max_list = [data[0][3], data[1][3], data[2][3]]
average_list = [data[0][1], data[1][1], data[2][1]]
bar = Bar()
bar.add_xaxis(xaxis_data=jobname)
# 第一个参数是图例名称,第二个参数是y轴数据
bar.add_yaxis(series_name="最低工资", y_axis=min_list)
bar.add_yaxis(series_name="最高工资", y_axis=max_list)
bar.add_yaxis(series_name="平均工资", y_axis=average_list)
# 设置表的名称
bar.set_global_opts(title_opts=opts.TitleOpts(title='职位工资分析', subtitle='工资单位:万/月'), toolbox_opts=opts.ToolboxOpts(),
)
bar.render("岗位薪资图.html")
12.1 三年工资薪资图
12.2 数据分析饼图岗位地区个数
代码
import pymysql
from pyecharts.charts import Pie
from pyecharts import options as opts
db = pymysql.connect(host="192.168.127.9",port=3306,database="qianc",user='root',password='12345678')
cursor = db.cursor()
sql = "select * from fenxi"
cursor.execute(sql)
data = cursor.fetchall()
print(data)
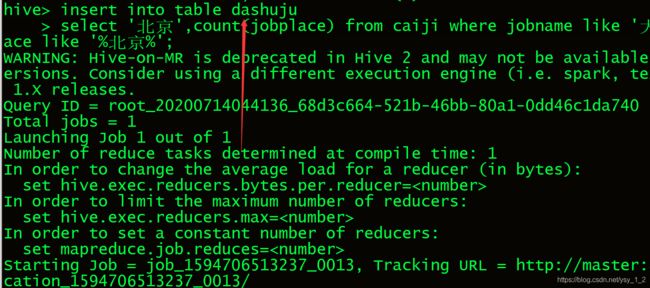
addr = ["北京","成都","广州","上海","深圳"]
geshu = [data[0][1],data[1][1],data[2][1],data[3][1],data[4][1]]
data_pair = [list(z) for z in zip(addr, geshu)]
data_pair.sort(key=lambda x: x[1])
# 画饼图
c = (
Pie()
.add("", [list(z) for z in zip(addr,geshu)])
.set_global_opts(title_opts=opts.TitleOpts(title="数据分析工程师地区岗位数",subtitle='单位:个数'),toolbox_opts=opts.ToolboxOpts())
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
).render("数据分析工程师地区岗位数.html")
12.3 大数据岗位分析图
12.4 数据采集
12.5 大数据1-3年经验工资

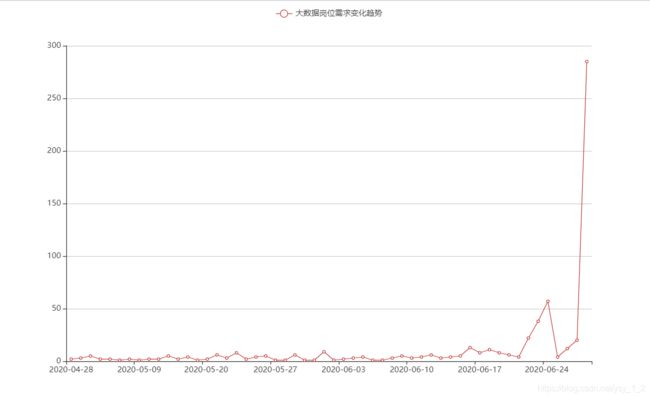
12.3 折线图
import pymysql
from pyecharts.charts import Line
from pyecharts import options as opts
db = pymysql.connect(host="192.168.127.9",port=3306,database="qianc",user='root',password='12345678')
cursor = db.cursor()
sql = "select * from dashujuriqi"
cursor.execute(sql)
data = cursor.fetchall()
riqi = []
geshu = []
for i in data:
riqi.append(str(i[0]))
geshu.append(str(i[1]))
print(geshu)
print(riqi)
data_pair = [list(z) for z in zip(riqi, geshu)]
data_pair.sort(key=lambda x: x[1])
(
Line(init_opts=opts.InitOpts(width="1000px", height="600px"))
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=False),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
.add_xaxis(xaxis_data=riqi)
.add_yaxis(
series_name="大数据岗位需求变化趋势",
y_axis=geshu,
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
)
.render("大数据岗位需求变化趋势.html")
)
13.总结
爬取招聘网站,使用hadoop、flume、mysql、hive、sqoop、python、scrapy、pyerchart、pymysql、运用这些知识,在做当中,我对hdfs和大数据flume传输更加熟悉,遇到很多问题,也能慢慢去解决这些问题.收获到了很多知识.对学习到的知识,能够运用.也明白自己很多不足,要继续努力去学习.