1. mongoDB介绍
官网:https://www.mongodb.com/
MongoDB是一个基于分布式文件存储 [1] 的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
mongdb是一个文档型的nosql数据库, 也是由key-value组成
2. mongodb的应用场景
适用场景
更高的写入负载
默认情况下, mongodb更侧重高数据写入性能, 而非事务安全, mongodb很适合业务系统中有大量"低价值"数据的场景, 但是应当避免在高事务安全性的系统中使用mongodb, 除非能从架构设计上保证事务的安全
高可用性
mongodb的(master-slave)配置非常简洁方便, 此外, mongodb可以快速响应的处理单节点故障, 自动, 安全的完成故障转移, 这些特性使得mongodb能在一个相对不稳定的环境中, 保持高可用性
数据量很大或者未来会变得很大
依赖数据库(MySQL)自身的特性,完成数据的扩展是较困难的事,在mysql中, 当一个单表达到5-10gb时会出现明显的性能降级 ,此时需要通过数据的水平和垂直拆分、库的拆分完成扩展,使用MySQL通常需要借助驱动层或代理层完成这类需求。而MongoDB内建了多种数据分片的特性,可以很好的适应大数据量的需求。
基于位置的数据查询
mongodb支持二维空间索引, 因此可以快速及精确的从指定位置获取数据
表结构不明确, 且数据在不断变大
在一些传统的rdbms中, 增阿一个字段会锁住整个数据库/表, 或者在执行一个重负载的请求时会铭心啊造成其他请求的性能降级,通常发生在数据库大于1G(当大于1TB时更甚)的时候, 因mongodb是文档型数据库, 为非结构化的文档增阿基也给新的字段是很快的操作, 并且不会影响到已有数据, 另外一个好处当业务数据变化时, 是将不需要dba修改表结构
没有dba
如果没有专职的DBA, 并且准备不使用标准的关系型思想(结构化, 连接等)来处理数据, 那么mongdoDB将会是你首选, mongdodb对于对象数据的存储非常方便, 类可以支持序列化成json存储到mongodb中, 但是需要先了解一些最佳实践, 避免当数据变大后, 由于文档设计问题而造成的性能缺陷
不适用场景
在某些场景下, mongodb作为一个非关系型数据库有其局限性, mongodb不支持事务操作, 所以需要用到事务的应用不用mongodb, 另外mongodb目前不支持join操作, 需要复杂查询的应用不建议使用mongodb
3. mongodb的安装
1. 下载安装
下载地址: https://www.mongodb.com/download-center/community
选择合适自己的版本进行下载
# 下载
curl -o https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel62-4.2.6.tgz
tar -xzvf mongodb-linux-x86_64-rhel62-4.2.6.tgz
mv mongodb-linux-x86_64-rhel62-4.2.6.tgz /usr/local/mongodbMongoDB 的可执行文件位于 bin 目录下,所以可以将其添加到 PATH 路径中:
export PATH=/bin:$PATH mkdir -p /data/db
mongod --config 配置文件路径
# 或者
mongod -f 配置文件路径-f是--config的缩写
配置文件,需要手动创建,参考以下配置即可。
创建mongodb.cfg配置文件
#数据库文件位置 dbpath=/data/servers/mongodb/data
#日志文件位置 logpath=/data/servers/mongodb/logs/mongodb.log # 以追加方式写入日志
logappend=true
# 是否以守护进程方式运行
fork=true
#绑定客户端访问的ip
bind_ip=192.168.10.135
# 默认27017
port=27017创建数据和日志目录:
mkdir -p /data/servers/mongodb/data
mkdir -p /data/servers/mongodb/logs通过配置文件方式启动:
mongod -f /data/servers/mongodb/mongodb.cfg2. MongoDb web用户界面
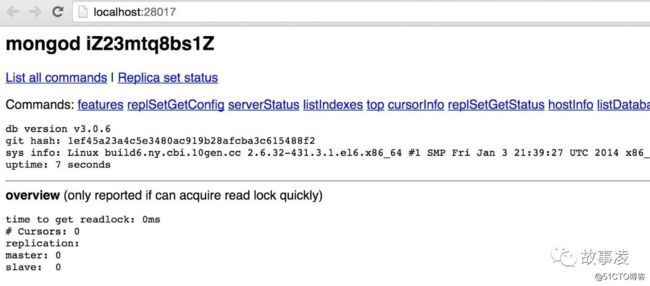
MongoDB 提供了简单的 HTTP 用户界面。如果你想启用该功能,需要在启动的时候指定参数 --rest 。
注意:该功能只适用于 MongoDB 3.2 及之前的早期版本。
./mongod --dbpath=/data/db --rest
3. mongodb主从搭建
mongodb的主从集群模式, 其实官方已经不推荐了, 但是要理解主从集群的一些特性, 默认从机是不可操作的, 只是作为数据备份, 如果需要从机对外提供读的操作, 需要单独发指令
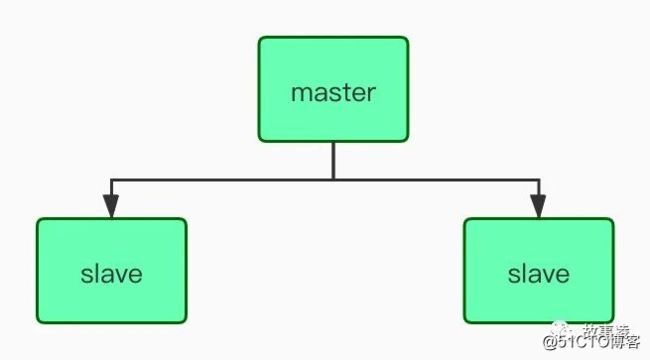
伪分布式搭建:在同一台机器,使用多个不同的端口,去启动多个实例。组成一个分布式系统。真正的分布式搭建:在不同机器,使用相同的端口,分别启动实例。如果是真正的分布式搭建,一定要保证网络畅通和防火墙问题。
主机配置
mongodb.cfg
#数据库文件位置
dbpath=/root/mongodb/ms/master/data
#日志文件位置
logpath=/root/mongodb/ms/master/logs/mongodb.log # 以追加方式写入日志
logappend=true
# 是否以守护进程方式运行
fork=true
#绑定客户端访问的ip
bind_ip=192.168.10.135
# 默认27017
port=27001
# 主从模式下,指定我自身的角色是主机
master=true
# 主从模式下,从机的地址信息
source=192.168.10.135:27002从机配置
# 数据库文件位置
dbpath=/root/mongodb/ms/slave/data
#日志文件位置
logpath=/root/mongodb/ms/slave/logs/mongodb.log # 以追加方式写入日志
logappend=true
# 是否以守护进程方式运行
fork = true
bind_ip=192.168.10.135
# 默认27017
port = 27002
slave = true
# 主从模式下,从机的地址信息
source=192.168.10.135:27001测试
启动服务
mongod -f /root/mongodb/ms/master/mongodb.cfg
mongod -f /root/mongodb/ms/slave/mongodb.cfg连接测试
mongo localhost:27001
mongo localhost:27002测试命令
db.isMaster()读写分离
MongoDB副本集对读写分离的支持是通过Read Preferences特性进行支持的,这个特性非常复杂和灵活。设置读写 分离需要先在从节点SECONDARY 设置
rs.slaveOk()4. mongodb副本集集群
副本集中有三种角色:主节点、从节点、仲裁节点仲裁节点不存储数据,主从节点都存储数据。
优点: 主如果宕机,仲裁节点会选举从作为新的主 如果副本集中没有仲裁节点,那么集群的主从切换依然可以进行。缺点: 如果副本集中拥有仲裁节点,那么一旦仲裁节点挂了,集群中就不能进行主从切换了。
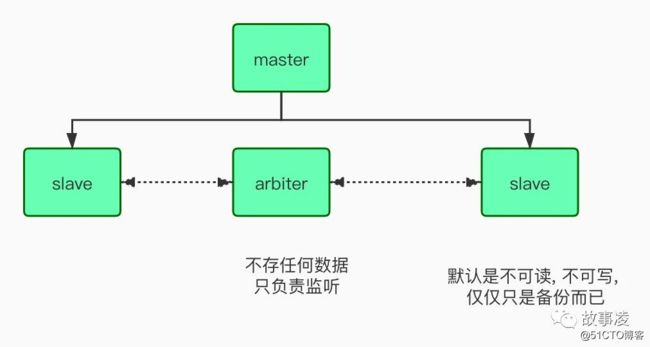
节点1配置
# 数据库文件位置
dbpath=/root/mongodb/rs/rs01/node01/data
#日志文件位置
logpath=/root/mongodb/rs/rs01/node01/logs/mongodb.log # 以追加方式写入日志
logappend=true
# 是否以守护进程方式运行
fork = true
bind_ip=192.168.10.135
# 默认27017
port = 27003
#注意:不需要显式的去指定主从,主从是动态选举的 #副本集集群,需要指定一个名称,在一个副本集下,名称是相同的
replSet=rs001节点2配置
数据库文件位置```
dbpath=/root/mongodb/rs/rs01/node02/data
日志文件位置
logpath=/root/mongodb/rs/rs01/node02/logs/mongodb.log # 以追加方式写入日志
logappend=true
是否以守护进程方式运行
fork = true
bind_ip=192.168.10.135
默认27017
port = 27004
注意:不需要显式的去指定主从,主从是动态选举的 #副本集集群,需要指定一个名称,在一个副本集下,名称是相同的 replSet=rs001
## 节点3配置
数据库文件位置
dbpath=/root/mongodb/rs/rs01/node03/data
#日志文件位置
logpath=/root/mongodb/rs/rs01/node03/logs/mongodb.log # 以追加方式写入日志
logappend=true
是否以守护进程方式运行
fork = true
bind_ip=192.168.10.135
默认27017
port = 27005
#注意:不需要显式的去指定主从,主从是动态选举的 #副本集集群,需要指定一个名称,在一个副本集下,名称是相同的 replSet=rs001
## 配置主备和仲裁
需要登录到mongodb的客户端进行配置主备和仲裁角色。
mongo 192.168.10.135:27003
use admin
cfg={_id:"rs001",members: [
{_id:0,host:"192.168.10.135:27003",priority:2},
{_id:1,host:"192.168.10.135:27004",priority:1},
{_id:2,host:"192.168.10.135:27005",arbiterOnly:true}
]}
rs.initiate(cfg);
说明: cfg中的_id的值是【副本集名称】
priority:数字越大,优先级越高。优先级最高的会被选举为主库
arbiterOnly:true,如果是仲裁节点,必须设置该参数
## 测试
rs.status

## 无仲裁副本集
和有仲裁的副本集基本上完全一样,只是在admin数据库下去执行配置的时候,不需要指定优先级和仲裁节点。这种 情况,如果节点挂掉,那么他们都会进行选举。
mongo 192.168.10.135:27006
use admin
cfg={_id:"rs002",members: [
{_id:0,host:"192.168.10.135:27006"},
{_id:1,host:"192.168.10.135:27007"},
{_id:2,host:"192.168.10.135:27008"}
]}
rs.initiate(cfg);
# 5. 副本集与分片混合部署
Mongodb的集群部署方案有三类角色: 实际数据存储节点, 配置文件存储节点和路由接入节点.
* 实际数据存储节点: 就是存储数据的
* 路由接入节点: 在分片的情况下起到负载均衡的作用
* 存储配置存储节点: 其实存储的是片键于chunk以及chunk与server的映射关系. 用上面的数据表示的配置节点存储的数据模型如下表:
map1
[0,10} chunk1
[10,20} chunk2
[20,30} chunk3
[30,40} chunk4
[40,50} chunk5
map2
chunk1 shard1
chunk2 shard2
chunk3 shard3
chunk4 shard4
chunk5 shard5

**副本集与分片混合部署方式如图:**

相同的副本集中的节点存储的数据是一样的,副本集中的节点是分为主节点、从节点、仲裁节点(非必须)三种角色。【这种设计方案的目的,主要是为了高性能、高可用、数据备份。】不同的副本集中的节点存储的数据是不一样,【这种设计方案,主要是为了解决高扩展问题,理论上是可以无限扩展的。】
每一个副本集可以看成一个shard(分片),多个副本集共同组成一个逻辑上的大数据节点。通过对shard上面进行逻 辑分块chunk(块),每个块都有自己存储的数据范围,所以说客户端请求存储数据的时候,会去读取config server中的映射信息,找到对应的chunk(块)存储数据。
混合部署下mongodb写数据流程图

混合部署方式下读mongodb的数据流程图

## 数据服务器配置
我们实验, 值部署副本集1
在副本集中每个数据节点的mongodb.cfg配置文件【追加】以下内容( ):
数据库文件位置
dbpath=/root/mongodb/datasvr/rs1/node01/data
#日志文件位置
logpath=/root/mongodb/datasvr/rs1/node01/logs/mongodb.log # 以追加方式写入日志
logappend=true
是否以守护进程方式运行
fork = true
bind_ip=192.168.10.136
默认27017
port = 27003
#注意:不需要显式的去指定主从,主从是动态选举的 #副本集集群,需要指定一个名称,在一个副本集下,名称是相同的 replSet=rs001
shardsvr=true
数据库文件位置
dbpath=/root/mongodb/datasvr/rs1/node02/data
#日志文件位置
logpath=/root/mongodb/datasvr/rs1/node02/logs/mongodb.log # 以追加方式写入日志
logappend=true
是否以守护进程方式运行
fork = true
bind_ip=192.168.10.136
默认27017
port = 27004
#注意:不需要显式的去指定主从,主从是动态选举的 #副本集集群,需要指定一个名称,在一个副本集下,名称是相同的 replSet=rs001
shardsvr=true
数据库文件位置
dbpath=/root/mongodb/datasvr/rs1/node03/data
#日志文件位置
logpath=/root/mongodb/datasvr/rs1/node03/logs/mongodb.log # 以追加方式写入日志
logappend=true
是否以守护进程方式运行
fork = true
bind_ip=192.168.10.136
默认27017
port = 27005
#注意:不需要显式的去指定主从,主从是动态选举的 #副本集集群,需要指定一个名称,在一个副本集下,名称是相同的 replSet=rs001
shardsvr=true
## 配置服务器配置
配置三个配置服务器,配置信息如下,端口和path单独指定:
数据库文件位置
dbpath=/root/mongodb/bin/cluster/configsvr/node01/data
#日志文件位置
logpath=/root/mongodb/bin/cluster/configsvr/node01/logs/mongodb.log # 以追加方式写入日志
logappend=true
是否以守护进程方式运行
fork = true
bind_ip=192.168.10.135
默认28001
port = 28001
表示是一个配置服务器
configsvr=true
#配置服务器副本集名称
replSet=configsvr
数据库文件位置
dbpath=/root/mongodb/bin/cluster/configsvr/node02/data
#日志文件位置
logpath=/root/mongodb/bin/cluster/configsvr/node02/logs/mongodb.log # 以追加方式写入日志
logappend=true
是否以守护进程方式运行
fork = true
bind_ip=192.168.10.135
默认28001
port = 28002
表示是一个配置服务器
configsvr=true
#配置服务器副本集名称
replSet=configsvr
dbpath=/root/mongodb/bin/cluster/configsvr/node03/data
#日志文件位置 logpath=/root/mongodb/bin/cluster/configsvr/node03/logs/mongodb.log # 以追加方式写入日志
logappend=true
是否以守护进程方式运行 fork = true bind_ip=192.168.10.135 # 默认28001
port = 28003
表示是一个配置服务器 configsvr=true #配置服务器副本集名称 replSet=configsvr
注意创建dbpath和logpath
mongod -f /root/mongodb/bin/cluster/configsvr/node01/mongodb.cfg
mongod -f /root/mongodb/bin/cluster/configsvr/node02/mongodb.cfg
mongod -f /root/mongodb/bin/cluster/configsvr/node03/mongodb.cfg
## 配置副本集
配置服务器是不存储服务器的, 需要在配置服务器上指定副本集
mongo 192.168.10.135:28001
use admin
cfg={_id:"configsvr",members: [
{_id:0,host:"192.168.10.136:28001"},
{_id:1,host:"192.168.10.136:28002"},
{_id:2,host:"192.168.10.136:28003"}
]}
rs.initiate(cfg);
## 路由服务器配置
### 1. 启动路由服务
configdb=configsvr/192.168.10.135:28001,192.168.10.135:28002,192.168.10.135:28003 #日志文件位置
logpath=/root/mongodb/bin/cluster/routersvr/node01/logs/mongodb.log
以追加方式写入日志
logappend=true
是否以守护进程方式运行 fork = true bind_ip=192.168.10.135 # 默认28001
port=30000
路由服务器启动(注意这里是mongos命令而不是mongod命令 )
mongos -f /root/mongodb/bin/cluster/routersvr/node01/mongodb.cfg
### 2. 关联切片和路由
登录到路由服务器中,执行关联切片和路由的相关操作。
#查看shard相关的命令
sh.help()
sh.addShard("切片名称/地址")
sh.addShard("rs001/192.168.10.135:27003");
sh.addShard("rs002/192.168.10.135:27006");
use abc
sh.enableSharding("abc");
sh.shardCollection("abc.mycollection",{name:"hashed"});
for(var i=1;i<=100;i++) db.mycollection.insert({name:"AABBCC"+i,age:i});
# 4. mongodb中的概念
mongdb是文档型数据库, 其中包括文档, 集合, 数据等, 我们先通过和常用的sql记性对比,来更好的帮助我们理解mongodb中的概念
SQL概念 Mongdb概念 解释说明
database database 库名
table collection 表/集合
row document 行/文档
column field 字段/域
index index 索引
table joins
表连接, Mongodb不支持
primary key primary key 主键, mongodb自动将_id字段设置为主键

# 1. 数据库
一个mongodb中可以建立多个数据库
mongodb的默认数据库为db, mongodb的单个实例可以容纳多个独立的数据库, 么一个都有自己的集合和权限, 不同的数据库放置不同的文件中。
## 1. show dbs 命令可以显示所有的数据库列表
mongo
MongoDB shell version v4.2.6
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("fb7781ef-41e6-4e76-a0bd-1ef98aedb802") }
MongoDB server version: 4.2.6
show dbsshow dbs
admin 0.000GB
config 0.000GB
local 0.000GB
2. db 命令可以显示当前数据库对象或者集合
> dbdb
test
> 3. use命令可以连接到一个指定的数据库
> dbdb
test
> use localuse local
switched to db local
> dbdb
local4. 基本的数据库讲解:
- admin: 从权限的角度来看, 这是“root”数据库, 要是将一个用户添加到这个数据库, 这个用户自动继承所有数据库的权限, 一些特定的服务器端命令也只能从这个数据库运行, 比如列出所有的数据库或者关闭服务器
- local:这个数据永远不会被复制, 可以用来存储限于本地单台服务器的任意集合
- config:当mongo用于分片设置时, config数据库在内部使用, 用于保存分片的相关信息
2. 文档
文档是一组键值对(及:key-value)。mongodb的文档不需要设置相同的字段, 并且相同的字段不需要相同的数据类型, 这与关系型数据库有很大的区别。也是mongodb非常突出的特点
注意:
- 文档的键值对是有序的
- 文档的值不仅可以是在双引号里面的额字符串, 还可以是其他几种数据类型, 甚至可以是文档
- mongodb区分类型和大小写。
- mongodb的文档不能有重复的键
- 文档的键一般是字符串。
3. 集合
集合就是mongodb文档, 类似于关系数据库系统中的表格
集合存在于数据库中, 集合没有固定的结构, 这意味着你咋对集合可以插入不同格式和类型的数据, 单通常情况下我们插入集合的数据都会有一定的关联性
比如: 我们可以把以下不同数据结构的文档插入到集合中:
{"site": "www.baidu.com"}
{"sit": "www.google.com", "name": "Google"}
一个collection中的所有域是collection中所有document中包含的field的并集
合法的集合名
-
集合名不能是空字符串""。
-
集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
-
集合名不能以"system."开头,这是为系统集合保留的前缀。
- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
如下实例:
db.col.findOne()capped collections
Capped collections 就是固定大小的collection。
它有很高的性能以及队列过期的特性(过期按照插入的顺序). 有点和 "RRD" 概念类似。
Capped collections 是高性能自动的维护对象的插入顺序。它非常适合类似记录日志的功能和标准的 collection 不同,你必须要显式的创建一个capped collection,指定一个 collection 的大小,单位是字节。collection 的数据存储空间值提前分配的。
Capped collections 可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放位置也是按照插入顺序来保存的,所以当我们更新Capped collections 中文档的时候,更新后的文档不可以超过之前文档的大小,这样话就可以确保所有文档在磁盘上的位置一直保持不变。
由于 Capped collection 是按照文档的插入顺序而不是使用索引确定插入位置,这样的话可以提高增添数据的效率。MongoDB 的操作日志文件 oplog.rs 就是利用 Capped Collection 来实现的。
要注意的是指定的存储大小包含了数据库的头信息。
db.createCollection("mycoll", {capped:true, size:100000})-
在 capped collection 中,你能添加新的对象。
-
能进行更新,然而,对象不会增加存储空间。如果增加,更新就会失败 。
-
使用 Capped Collection 不能删除一个文档,可以使用 drop() 方法删除 collection 所有的行。
-
删除之后,你必须显式的重新创建这个 collection。
- 在32bit机器中,capped collection 最大存储为 1e9( 1X109)个字节。
4. 元数据
数据库的信息是存储在集合中的, 他们使用了系统的命名空间:
dbname.system.*在mongodb数据库中名字空间 .system.*是多包含多种系统信心的特殊集合, 如下:
集合命名空间 描述
dbname.system.namespaces 列出所有名字空间
dbname.system.indexes 列出所有索引
dbname.system.profile 包含数据库概要信息
dbname.system.users 列出所有可访问数据库的用户
dbname.local.source 包含复制对端(slave)的服务器信息和状态对于修改系统集合中的对象有如下限制。
在{{system.indexes}}插入数据,可以创建索引。但除此之外该表信息是不可变的(特殊的drop index命令将自动更新相关信息)。
{{system.users}}是可修改的。{{system.profile}}是可删除的。
5. mongodb数据类型
下表为MongoDB中常用的几种数据类型。
数据类型 描述
String 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。
Integer 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。
Boolean 布尔值。用于存储布尔值(真/假)。
Double 双精度浮点值。用于存储浮点值。
Min/Max keys 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。
Array 用于将数组或列表或多个值存储为一个键。
Timestamp 时间戳。记录文档修改或添加的具体时间。
Object 用于内嵌文档。
Null 用于创建空值。
Symbol 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。
Date 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。
Object ID 对象 ID。用于创建文档的 ID。
Binary Data 二进制数据。用于存储二进制数据。
Code 代码类型。用于在文档中存储 JavaScript 代码。
Regular expression 正则表达式类型。用于存储正则表达式。下面说明下几种重要的数据类型。
ObjectId
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
- 前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数

MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象
由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过 getTimestamp 函数来获取文档的创建时间:
> var newObject = ObjectId()
> newObject.getTimestamp()
ISODate("2017-11-25T07:21:10Z")ObjectId 转为字符串
> newObject.str
5a1919e63df83ce79df8b38f字符串
BSON 字符串都是 UTF-8 编码。
时间戳
BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。时间戳值是一个 64 位的值。其中:
- 前32位是一个 time_t 值(与Unix新纪元相差的秒数)
- 后32位是在某秒中操作的一个递增的序数
在单个 mongod 实例中,时间戳值通常是唯一的。
在复制集中, oplog 有一个 ts 字段。这个字段中的值使用BSON时间戳表示了操作时间。
```> BSON 时间戳类型主要用于 MongoDB 内部使用。在大多数情况下的应用开发中,你可以使用 BSON 日期类型。
## 日期
表示当前距离 Unix新纪元(1970年1月1日)的毫秒数。日期类型是有符号的, 负数表示 1970 年之前的日期。
> var mydate1 = new Date() //格林尼治时间
> mydate1
ISODate("2018-03-04T14:58:51.233Z")
> typeof mydate1
object
> var mydate2 = ISODate() //格林尼治时间
> mydate2
ISODate("2018-03-04T15:00:45.479Z")
> typeof mydate2
object
这样创建的时间是日期类型,可以使用 JS 中的 Date 类型的方法。
返回一个时间类型的字符串:
var mydate1str = mydate1.toString()
mydate1str
Sun Mar 04 2018 14:58:51 GMT+0000 (UTC)
typeof mydate1str
string
或者
> Date()
Sun Mar 04 2018 15:02:59 GMT+0000 (UTC)