接上文的lvs你不知道的那些秘密: https://mp.weixin.qq.com/s/VZh0_BOrPhOnEAHRjen-bQ
5. keepalived
keepalive的学习参考网站:https://www.keepalived.org/
在学习keepalived之前, 我们来想一个问题, LVS只是负责负载均衡的转发, 那如果后台的Real Server的服务挂掉以后, LVS是否能主动把这个摘除掉吗? 问题是肯定不行的, 就是LVS不具备把后端挂掉的Real Server摘除掉, 那keepalived的应用而生.
keepalived起初就是为lvs设计的,专门用来监控集群系统中各个服务节点的状态,它根据tcp/ip参考模型的第三四和第五层交换机制检测每个服务节点的状态,每个服务节点异常或者工作障碍,keepalvied讲立刻检测到,并把障碍节点剔除,是毫秒级的,当后台节点恢复正常以后,keepalived有自动将服务节点重新添加在服务器集群中。
keepalvied后来又加了vrrp功能,vrrp(虚拟路由器冗余协议),出现的目的就是解决静态路由单点故障的问题,通过vrrp可以实现网络不间断稳定运行。
1. keepalived简介
什么是Keepalived?
Keepalived是用C语言编写的路由软件。该项目的主要目标是为Linux系统和基于Linux的基础结构提供负载均衡和高可用性的简单而强大的功能。负载平衡框架依赖于提供第4层负载平衡的著名且广泛使用的Linux虚拟服务器(IPVS)内核模块。Keepalived实现了一组VIP功能,以根据其运行状况动态,自适应地维护和管理负载平衡的服务器池。另一方面,VRRP实现了高可用性 协议。VRRP是路由器故障转移的基础。此外,Keepalived还实现了一组VRRP有限状态机的挂钩,从而提供了低级和高速协议交互。为了提供最快的网络故障检测,Keepalived实施BFD协议。VRRP状态转换可以考虑BFD提示来驱动快速状态转换。Keepalived框架可以独立使用,也可以一起使用以提供弹性基础架构。
keepalived支持多组VIP的操作, 就是一台服务器上可以部署多台VIP, 可以理解为每个VIP是一组操作
如何更加形象的理解keepalived的主从切换
那我不得不上一张图了, 当前我们提起来这张图, 就是特别明显的感觉和keepalived的主从切换特别形象, 没有之一

上图中, 两个桌子, 就是我们的两个服务器, 桌布就是我们的VIP, 如果心跳检查发现两个服务器之间有问题, 会主动切换到从服务器上, 时间也是毫秒级别的.
keepalive的使用场景
可以说keepalived本身就是给LVS量身定做的, LVS虽然是可以进行负载均衡的请求的转发, 如果后端服务器检查到服务器故障, LVS是可以主动切除的, 这个LVS本身具备的功能, 而且切除后端Real Server的时间都是在毫秒级别, 特别的快速, 毕竟LVS已经集成到linux系统内核了.那就有一个问题, 如果LVS服务器挂掉了呢?我们的服务是不是就不可用了呢? 那就来看看我们keepalived的使用场景了.
-
LVS和keepalived可以说是天然的集成, 我们在linux系统安装的时候, 可能都不需要什么特殊的LVS的配置, lvs+keepalived的集成, 只需要在keepalived的配置文件中增加配置就ok
-
keepalive提供了主从切换的功能, 主从之间有心跳检测, 如果发现主从挂掉, keepalived会自动进行主从的切换
- 单体架构中, 我们最常使用lvs+keepalived的功能'
2. keepalivd的工作原理
架构原理
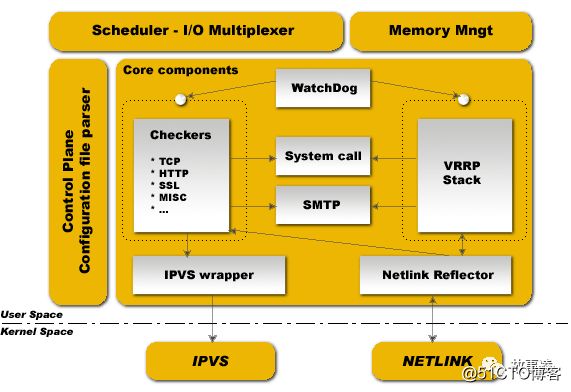
-
分为两大层:内核空间(Kernel Space)、用户空间(User Space)
-
IPVS(IP Virtual Server): 实现传输层负载平衡,也称为第4层交换;
- NETLINK: 用于在内核和用户空间进程之间传输信息;
Keepalived 分为3个守护进程:
-
父进程: 很简单,负责 fork 子进程,并监视子进程健康状态(图中 WatchDog 周期性发送检测包,需要的话重启子进程);
-
子进程A: 负责VRRP框架(图中 VRRP Stack)
- 子进程B: 负责健康检查(图中 Checkers)
运行原理
keepalived 通过选举(看服务器设置的权重)挑选出一台热备服务器做 MASTER 机器,MASTER 机器会被分配到一个指定的虚拟 ip,即VIP, 外部程序可通过该 VIP 访问这台服务器,如果这台服务器出现故障(断网,重启,或者本机器上的 keepalived crash 等),keepalived 会从其他的备份机器上重选(还是看服务器设置的权重)一台机器做 MASTER 并分配同样的虚拟 IP,充当前一台 MASTER 的角色。权重越高, 备用机器被拉起来的占比就越大, 一般的主备就可以满足我们的需求
选举策略
选举策略是根据 VRRP 协议,完全按照权重大小,权重最大的是 MASTER 机器,下面几种情况会触发选举
-
keepalived 启动的时候
-
master 服务器出现故障(断网,重启,或者本机器上的 keepalived crash 等,而本机器上其他应用程序 crash 不算)
- 有新的备份服务器加入且权重最大
3. keepalived的脑裂
什么是脑裂
在高可用系统中, 作为主备节点的两台服务器, 可能因为一些比如说网络断开, 两台机器的心跳检测会认为主挂了, 但是主其实是正常的,只是网络断开了, 心跳检测没法检查到主还活着, 由于主从之间失去了联系, 都以为是对方发生了故障, 所以两个节点都会主动的抢占资源, 争抢应用服务, 争抢VIP, 这样就发发生一些严重的后果, 或者资源被瓜分了, 或者是两边的节点都启动不起来了, 或者是都起来了, 但是同时读写共享存储, 导致数据损坏.
脑裂产生的原因
-
高可用服务器对之间心跳线链路发生故障,导致无法正常通信
-
因心跳线断开(包括网线断裂、水晶头松动等物理原因)
-
因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)
-
因心跳线间连接的设备故障(网卡及交换机)
- 因仲裁的机器出问题(采用仲裁的方案)
-
-
高可用服务器上开启了 iptables防火墙阻挡了心跳消息传输
-
高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败
- 其他服务配置不当等原因,如心跳方式不同,心跳广插冲突、软件Bug等
脑裂常见的解决方案
在实际生产环境中,我们可以从以下几个方面来防止裂脑问题的发生:
-
同时使用串行电缆和以太网电缆连接,同时用两条心跳线路,这样一条线路坏了,另一个还是好的,依然能传送心跳消息
-
当检测到裂脑时强行关闭一个心跳节点(这个功能需特殊设备支持,如Stonith、feyce)。相当于备节点接收不到心跳消患,通过单独的线路发送关机命令关闭主节点的电源
- 做好对裂脑的监控报警(如邮件及手机短信等或值班).在问题发生时人为第一时间介入仲裁,降低损失。例如,百度的监控报警短倍就有上行和下行的区别。报警消息发送到管理员手机上,管理员可以通过手机回复对应数字或简单的字符串操作返回给服务器.让服务器根据指令自动处理相应故障,这样解决故障的时间更短.
当然,在实施高可用方案时,要根据业务实际需求确定是否能容忍这样的损失。对于一般的网站常规业务.这个损失是可容忍的
4. lvs+keepalived
lvs和keepalived应该可以说是天然的集成, 在因为LVS已经集成到linux内核系统中, 我们只需要配置一下keepalived的配置文件就可以了, 那我们还是主要来研究一下keepalived的配置文件, 就可以轻松的使用了
keepalived的配置文件
#全局配置
global_defs {
notification_email { #设置报警邮件地址,每行一个,(如何要开启邮件报警,需要开启本机的sendmail服务)
[email protected]
}
notification_email_from [email protected] #设置邮件的发送地址
smtp_server smtp.qq.com #设置邮件的smtp server地址
smtp_connect_timeout 30 #设置连接smtp server的超时时间
router_id LVS_DEVEL #表示keepalived服务器的一个标识,是发邮件时显示在邮件主题中的信息
}
#keepalived的VRRPD配置,是所有keepalived配置的核心
#VRRP实例配置
vrrp_instance VIP_142 #是VRRP实例开始的标识,后跟VRRP实例名称
{
state MASTER #keepalived的角色,MASTER主,BACKUP备
interface eth0 #用于指定HA监测网络的接口
virtual_router_id 142 #虚拟路由标识,这个标识是一个数字,同一个VRRP实例使用唯一的一个标识,即在同一个vrrp_instance下,MASTER和BACKUP必须是一致的!
priority 100 #权重优先级
advert_int 2 #用于设定master和backup主机之间同步检查的时间间隔,单位是秒
garp_master_delay 10 #用于切换到master状态后延时进行Gratuitous arp请求的时间
smtp_alert #表示是否开启邮件通知(用全局区域的邮件设置来发通知)
authentication #主备之间进行通信的验证类型和密码:验证类型主要有PASS和AH两种,一个在vrrp_instance下,MASTER和backup必须使用相同的密码才可以通信
{
auth_type PASS
auth_pass 123456
}
#virtual_ipaddress用于设置虚拟ip地址,可以设置多个vip,每行一个,
virtual_ipaddress
{
10.95.0.200/24
}
track_interface #用于设置一些额外的网络监控接口,其中任何一个网络接口出现故障,keepalived都会进去fault状态!
{
eth0
}
nopreempt #设置不抢占功能,只能在backup上使用,知道机器有故障了才切换,
preemtp_delay 300 #用于设置抢占的延时时间,(例:开启启动没必要抢占)
}
#以下是lvs的主要主要配置信息,主要实现lvs的ip包转发功能!
virtual_server 10.95.0.200 80 #虚拟ip和端口
{
delay_loop 6 #设置健康检查的时间间隔
lb_algo wrr #设置负载调度算法
lb_kind DR #设置lvs的模式
persistence_timeout 60 #会话保持时间,单位秒
protocol TCP #ip包转发协议,有TCP和UDP两种
real_server 10.95.0.143 80 #real server 的ip
{
weight 3 #权重
TCP_CHECK #健康检查
{
connect_timeout 10 #表示无响应超时时间
nb_get_retry 3 #表示重连次数
delay_before_retry 3 #表示重试间隔
connect_port 80 #表示端口
}
}
real_server 10.95.0.144 80
{
weight 3
TCP_CHECK
{
connect_timeout 10
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
}keepalived的心跳检测
健康监测应许多种检查方式,常见的有,HTTP_GET,SSL_GET,TCP_CHECK,SMTP_CHECK,MISC_CHECK.
TCP_CHECK {
conetct_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
connect_port:健康检查的端口,如果不指定,默认是real_server指定的端口
connect_timeout:表示无响应超时时间,单位是秒,这里是3s
nb_get_retry:表示重试次数,这里是3ci
delay_before_retry:表示重试间隔,
HTTP_GET |SSL_GET
{
url{
path /index.html #指定url信息
digest e6owjfdsjfalsjdfsalkf30wfdsfjwqe
#ssl检查后的摘要信息,这些摘要信息可以通过genhash命令工具获取,
#例:genhash -s 192.168.12.80 -p 80 -u /index.html
status_code 200 }
connect_port 80
bindto 192.168.31.128 #表示通过此地址来对发送请求对服务器进行健康检查
nb_get_retry 3
delay_before_retry 2
}
5. lvs+keepalvied使用过程的一些坑
1. keepalived的启动
在配置keepalived.conf的配置文件时,一定要检查配置文件的正确性,因为keepalived在重启时,并不检查配置文件的正确性,即使没有配置文件,keepalived照样可以启动,所以一定要检查配置文件是否正确
2. keepalived服务器的局限性
下面LVS+DR+keepalived+nginx+tomcat的一个架构
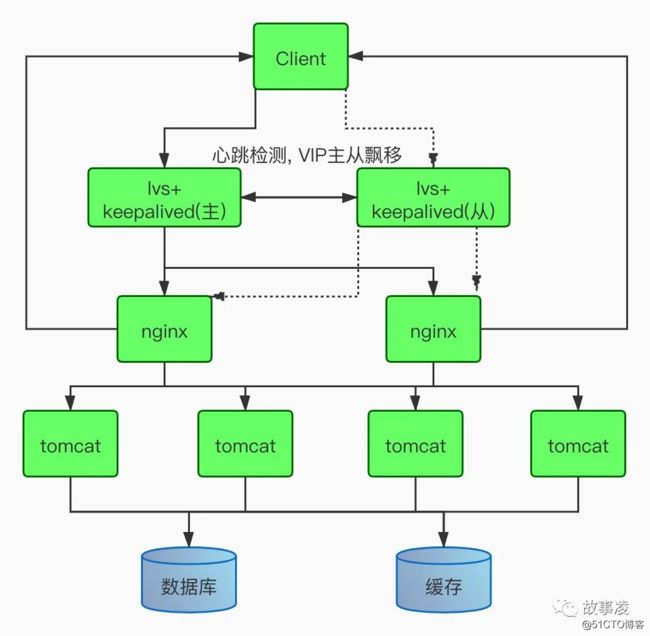
在我们的工作中, 如果要是实现上面的方案, 应用服务器的个数应该有8台服务器, 但是我们发现问题, 如果keepalvied的VIP在主上的时候, keepalived的从服务器上是没有任何请求的, 几乎没有什么压力, 只有发生VIP偏移, 从才会进行工作, 那为了提高服务器的使用率, keepalived的服务器是否可以作为tomcat服务器来使用呢? 如果用了, 那就掉坑里面了.下面我们来说说原因
上图中的keepalived服务器, nginx服务器, 都是有绑定VIP的, 如果不清楚LVS的DR模式, 可以上看我上一篇的LVS的那篇文章.
我们如果在nginx服务器上部署tomat应用, 好的, 就是把nginx也当成是tomcat服务器, 这个可以为我们节省一些资源, 但是如果你把tomcat部署在keepalived服务器上, 你真的就有坑了
如果在lvs+keepalvied(主)服务器上部署了tomcat应用, 不可避免的, 我们应用中有调用域名或者VIP的函数或者方法, 即服务之间的相互调用, 应用在发起请求的时候, 它的源ip地址就可以是VIP地址, 目标IP地址是VIP, 这个时候请求是可以正常转发, 处理的, 但是最后nginx处理完请求以后, nginx就懵逼了, 她没法把请求返回给lvs+keepalvied(主)服务器的请求,这时候的nginx太难了, nginx是Real Service, DR模式中, 他自己是有VIP的, 他自己是vip,让他返回给VIP, 你是nginx, 你也懵逼
总之一句话总结: lvs+keepalived服务器上不能部署发起请求的客户端应用, 否则接收不到消息
3. 主故障恢复, 避免自动切换
背景需求:在一个HA集群中,如果主节点死机了,备用节点会进行接管,主节点再次正常启动后一般会自动接管服务。对于实时性和稳定性要求不高的的业务系统来说,这种来回切换的操作是可以接受的。而对于稳定性和实时性要求很高的业务系统来说,不建议来回切换,毕竟服务的切换存在一定的风险和不稳定性。
方法一:
在这种情况下,就需要设置nopreempt这个选项,设置mopreempt可以实现主节点故障恢复后不再切换回主节点,让服务器一直在备节点下工作,知道备用节点出现故障才会进行切换,在使用不抢占功能时,只能在“state”状态为“BACKUP”的节点上设置,而且这个节点的优先级必须高于其他节点。
方法二:角色可以都设为BACKUP 权重一样 先启动一个节点 后面的故障切换谁抢到谁用
6. lvs的集群模式
我们用流量的并发来进行计算, 如果流量是10w以下的并发, 那我们可能使用nginx+keepalived的架构, 可能就直接可以满足需求, 那如果请求几十万的并发的, 那就推荐大家使用lvs+keepalived的架构, 这个lvs的并发, 一个配置不错的应用服务器, 应该可以扛个几十万的并发, 是没有问题, 那如果请求量还是很大的, lvs扛不住, 把我的机器打崩了呢, 那这个时候LVS集群模式就诞生了.其实就是一个思路, 请求大了机器来扛.
fullnat是淘宝开源的一种lvs转发模式,主要思想:引入local address(内网ip地址),cip-vip转换为lip->rip,而 lip和rip均为IDC内网ip,可以跨vlan通讯,这刚好符合我们的需求,因为我们的内网是划分了vlan的。
首先我们在了解这种方式之前, 我们来了解一下什么是OSPF?
什么是OSPF?
OSPF(Open Shortest Path First开放式最短路径优先)是一个内部网关协议(Interior Gateway Protocol,简称IGP),用于在单一自治系统(autonomous system,AS)内决策路由。是对链路状态路由协议的一种实现,隶属内部网关协议(IGP),故运作于自治系统内部。著名的迪克斯加算法被用来计算最短路径树。OSPF支持负载均衡和基于服务类型的选路,也支持多种路由形式,如特定主机路由和子网路由等。
我们通过OSPF在服务上安装, 实现路由到LVS服务器上的最短路径是一样的, 从而实现LVS平均接收请求, 可以接受更高的并发量.
这个时候可能需要网络的同事帮我们配置一下了, 在路由器上需要进行一些设置
架构图

针对集群操作篇, 我放在了下一篇的文章中, 是阿里的大佬写的, 大家在运维的时候, 可以参考.
作者:凌晶
简介:生活中的段子手,目前就职于一家地产公司做 DevOPS 相关工作, 曾在大型互联网公司做高级运维工程师,熟悉 Linux 运维,Python 运维开发,Java 开发,DevOPS 常用开发组件等,个人公众号:stormling,欢迎来撩我哦!

故事凌
明天能否加个鸡腿!
喜欢作者