ICDAR 2019比赛及数据集下载-任务-ICDAR2019对带有部分标签的大规模街景文本的强大阅读挑战
ICDAR 2019比赛及数据集下载
https://rrc.cvc.uab.es/?ch=16&com=tasks
任务-ICDAR2019对带有部分标签的大规模街景文本的强大阅读挑战
LSVT数据集将包含450、000张带有文本的图像,这些文本可在街道上自由捕获,例如,店面和地标。其中50,000个具有完整注释,分为i)30,000个训练集,ii)20,000个测试集。作为训练集的一部分,其余400,000张图像均进行了弱注释。
为了评估各个方面的文本阅读性能,我们在此大型街景数据集上引入了两个常见的任务,即文本检测和端到端文本识别。
- 文本检测,目的是将街景图像中的文本本地化为文本行级别,这与所有以前的RRC场景文本检测任务相似。
- 端到端文本点,目的是以端到端的方式定位和识别图像中的所有文本行。
注意
参赛者可以自由使用公开可用的数据集(例如ICDAR2015,RCTW-17,MSRA-TD500,COCO-Text和MLT)或合成图像作为本次比赛的额外训练数据,而不能公开访问的私有数据则不然。允许使用。
基本真理格式
对于数据集中所有带有完整注释的图像,我们按照命名约定创建一个JSON文件,以结构化格式存储地面真相:
gt_ [image_id],image_id是指数据集中图像的索引。
在JSON文件中,每个gt_ [image_id]都与一个列表相对应,其中列表中的每一行都与图像中的一个单词相对应,并以以下格式给出其边界框坐标,转录和模糊度标志:
{
“ gt_1”:[
{“点”:[[x1,y1],[x2,y2],…,[xn,yn]],“转录”:“ trans1”,“模糊性”:false},
{“点”:[[x1,y1],[x2,y2],…,[xn,yn]],“转录”:“ trans2”,“模糊性”:false}],
“ gt_2”:[
{“点”:[[x1,y1],[x2,y2],…,[xn,yn]],“ transcription”:“ trans3”,“难以辨认”:false}],
……
}
其中“点”中的x1,y1,x2,y2,…,xn,yn是多边形边界框的坐标,可以是4、8、12个多边形顶点。设置为“ true”时,“转录”表示每个文本行的文本,“难以辨认”表示“无关”文本区域,这不会影响结果。
与完全注释基础事实相似,对于数据集中具有弱注释的图像,我们将所有基础事实存储在单个JSON文件中。在JSON文件中,每个gt_ [image_id]都对应一个词,我们在图像中将其称为“感兴趣的文本”:
{
“ gt_0”:[{“ transcription”:“ trans1”}],
“ gt_1”:[{“ transcription”:“ trans2”}],
“ gt_2”:[{“ transcription”:“ trans3”}],
……
}
在此处下载地面实况示例:LSVT-gt-example
任务1:文本检测
此任务是评估文本检测性能,其中应试者的方法应将街景图像中的文本本地化为文本行。
输入:完整的街景图像
输出:所有文本实例的四边形或多边形中的文本行的位置。
结果格式
所有提交结果的命名应遵循以下格式:res_ [image_id]。例如,与输入图像“ gt_1.jpg”相对应的文本文件的名称应为“ res_1”。要求参与者在单个JSON文件中提交所有图像的检测结果。提交文件格式如下:
{
“ res_1”:[
{“点”:[[x1,y1],[x2,y2],…,[xn,yn]],“信心”:c},
{“点”:[[x1,y1],[x2,y2],…,[xn,yn]],“信心”:c}],
“ res_2”:[
{“点”:[[x1,y1],[x2,y2],…,[xn,yn]],“信心”:c}],
……
}
其中n是顶点的总数(可以是不固定的,在不同的预测文本实例之间有所不同)。c 是预测的置信度得分。
在此处下载提交示例:LSVT-detection-example
评估指标
遵循ICDAR 2015 [1]和ICDAR 2017-RCTW [2]数据集的评估协议,通过IoU(联合交叉)对LSVT(T1)的检测任务进行了精确度,召回率和F分数评估。阈值0.5和0.7,并且只有H均值低于0.5才会用作最终排名的主要指标。同时,在有多个匹配项的情况下,我们仅考虑具有最高IOU的检测区域,其余匹配项将被视为误报。精度,召回率和F分数的计算如下:

其中TP,FP,FN和F分别表示真阳性,假阳性,假阴性和H均值。
所有检测到的或遗漏的“无关”事实都不会对评估结果有所帮助。与COCO文本[3]和ICDAR2015 [1]相似,难以辨认的文本
实例和符号被标记为“无关”区域。
任务2:端到端文本发现
该任务的主要目的是以端到端的方式检测和识别所提供图像中的每个文本实例。
输入:完整的街景图像
输出:四边形或多边形中的文本行的位置以及图像中所有文本实例的相应识别结果。
结果格式
该学员须提交预测的检测和识别结果在一个JSON文件的所有图像:
{
“ res_1”:[
{“点”:[[x1,y1],[x2,y2],…,[xn,yn]],“信心”:c,“转录”:“ trans1”},
{“点”:[[x1,y1],[x2,y2],…,[xn,yn]],“信心”:c,“转录”:“ trans2”}],
“ res_2”:[
{“点”:[[x1,y1],[x2,y2],…,[xn,yn]],“信心”:c,“转录”:“ trans3”}],
……
}
其中n是顶点的总数(可以是不固定的,在不同的预测文本实例之间有所不同)。c是预测的置信度得分。“转录”表示每个文本行的文本。
预计所有比赛参与者都将提交他们的测试结果,测试结果将在最终提交截止日期前几周发布。
在此处下载提交示例: LSVT端到端示例
评估指标
为了更全面地比较端到端文本发现任务(T2)的结果,将在多个方面对提交的模型进行评估,它们是:i)根据规范化编辑距离(1-NED)的规范化指标[2] (特别是),以及ii)精度,召回率和F分数。尽管将发布两个指标的结果,但仅将1-NED视为正式排名指标。
在F分数中完全匹配的条件下,真实的正文本行表示预测结果与匹配的地面事实(IoU高于0.5)之间的Levenshtein距离等于0。
对于归一化度量,我们首先通过计算检测结果与相应的地面真相交(IoU)来评估检测结果。IoU值高于0.5的检测区域将与识别基础事实(即特定文本区域的成绩单基础事实)匹配。同时,在有多个匹配项的情况下,我们仅考虑IoU最高的检测区域,其余匹配项将被视为误报。然后,我们将使用归一化编辑距离(NED)评估预测的转录,公式为:
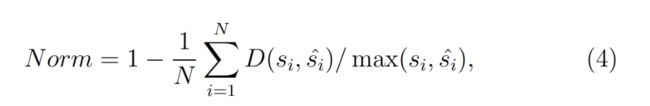
其中d(:)代表的Levenshtein距离,和 与
与 表示字符串的预测文本行,并在区域中的对应的基础事实。注意,在所有地面真实位置上都计算了相应的地面真实,以选择最大IoU中的 一个作为预测对。N是“配对” GT和检测到的区域的最大数量,其中包括单例:与任何检测都不匹配的GT区域(与NULL /空字符串配对)和与任何GT区域不匹配的检测(与NULL /空配对)空字符串)。
表示字符串的预测文本行,并在区域中的对应的基础事实。注意,在所有地面真实位置上都计算了相应的地面真实,以选择最大IoU中的 一个作为预测对。N是“配对” GT和检测到的区域的最大数量,其中包括单例:与任何检测都不匹配的GT区域(与NULL /空字符串配对)和与任何GT区域不匹配的检测(与NULL /空配对)空字符串)。
注意: 为避免注释含糊不清,我们在评估前进行预处理:1)英文字母不区分大小写;2)繁体字和简体字视为同一个标签;3)空格和符号将被删除;4)所有难以辨认的图像均不会影响评估结果。
参考文献
[1] Karatzas,Dimosthenis等。“ ICDAR 2015强劲阅读竞赛。” 文档分析与识别(ICDAR),2015年第13届国际会议。IEEE,2015年。
[2]史宝光等。“ ICDAR2017野外阅读中文比赛(RCTW-17)。”文件分析与识别(ICDAR),2017年第14届IAPR国际会议。卷 1. IEEE,2017年。
[3] Gomez,Raul等。“ ICDAR2017对COCO-Text的强大阅读挑战。” 2017年第14届IAPR国际文件分析与识别会议(ICDAR)。IEEE,2017年。
下载-ICDAR2019带有部分标签的大规模街景文字的强大阅读挑战
LSVT数据集将包含450,000张带有文本的图像,这些图像可在街道上自由捕获。其中有50,000个具有完整注释,分为三部分:
i)30,000张完全注释的图像用于训练集,ii)20,000张测试集合,iii)400,000张弱注释训练集。
LSVT数据集也可以从百度镜像中找到: LSVT-dataset
注意
参赛者可以自由使用公开可用的数据集(例如ICDAR2015,RCTW-17,MSRA-TD500,COCO-Text和MLT)或合成图像作为本次比赛的额外训练数据,而不能公开访问的私有数据则不然。允许使用。
注册确认
1)要确认在RRC大赛2019的ICDAR-2019 LSVT挑战赛中的注册,请发送电子邮件至[email protected] ,标题为“ 参加ICDAR-2019 LSVT挑战赛 ”
2)此过程不强制您参与或提交结果,这是一种兴趣表达。您可以参加挑战的一项或多项任务。没有必要参加所有任务。
训练集
带有弱注释的训练集包含400,000张图像(33 GB),并分为10个文件。
- train_weak_images_0.tar.gz(3.3G)-40,000张图像
- train_weak_images_1.tar.gz (3.3G) -40,000 张图像
- train_weak_images_2.tar.gz (3.3G) -40,000 张图像
- train_weak_images_3.tar.gz (3.3G) -40,000 张图像
- train_weak_images_4.tar.gz (3.3G) -40,000 张图像
- train_weak_images_5.tar.gz (3.3G) -40,000 张图像
- train_weak_images_6.tar.gz (3.3G) -40,000 张图像
- train_weak_images_7.tar.gz (3.3G) -40,000 张图像
- train_weak_images_8.tar.gz (3.3G) -40,000 张图像
- train_weak_images_9.tar.gz (3.3G) -40,000 张图像
- train_weak_labels.json- 包含40万张图片的真实文件
带有完全注释的训练集包含30,000张图像(8.2 GB),并分为2个文件。
- train_full_images_0.tar.gz (4.1G)
- train_full_images_1.tar.gz (4.1G)
- train_full_labels.json -30,000张图像的真实文件
测试集
- 测试集的第一部分: test_part1_images.tar.gz (2.7G) -10,000张图像
更新日志:我们对测试集的第一部分进行了一些数据清理,并于2019年4月20日对其进行了更新。
- 测试集的最后一部分: test_part2_images.tar.gz (2.7G) -10,000张图像
注:第一部分和测试集的第二部分的结果应一并报送,以及 评价结果将提供 4月30日之后。