SQL执行过程
前言
有人曾经说过:“普通程序员的技术尽头就是在研究数据库”。架构设计都围饶着数据库来设计。又有人统计过“对数据库的查询操作要远胜更新操作”。所以了解数据查询还是很有必要的。
Mysql查询过程
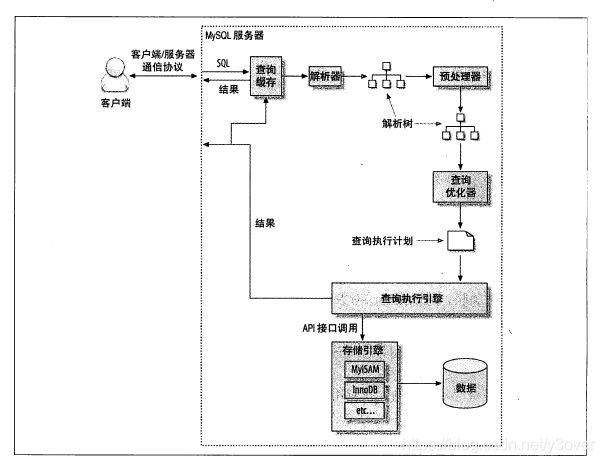
- 客户端发送一条查询给服务器。
- 服务器先检查缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一个阶段。
- 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
- MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询。
- 将结果返回给客户端。
MySQL 通信协议
MySQL 客户端和服务端的通信是半双工的,这意味着同一个时刻内,客户端和服务端只有一方在发送数据。一旦一方开始发送数据,另外一端必须接受完整个消息才能进行响应。
注:通信协议限制了数据交互,应该方要经常要搞个连接池
防止查询语句过长浪费资源用 max_allowed_packet 限制。
防止结果集过大需要添加 LIMIT 限制。
查询各有进程状态命令为SHOW FULL PROCESSLIST
查询缓存
如果查询缓存是打开的,那么MySQL会优先检查这个查询是否命中查询缓存中的数据。
- 如果当前的查询恰好命中了查询缓存,那么在返回查询结果之前MySQL会检查一次用户权限。如果权限没有问题,MySQL会跳过所有其他阶段,直接从缓存中拿到结果并返回给客户端。
- 如果查询和缓存中的查询即使只有一个字节不同(这个检查是通过一个对大小写敏感的哈希查找实现的),那也不会匹配缓存结果,这种情况查询会进入下一个阶段的处理。
查询缓存命令:show variables like ‘%query_cache%’;
语法解析器和预处理器
- MySQL通过关键字将SQL语句进行解析,并生成一棵对应的“解析树”。它将验证是否使用错误的关键字,或者使用关键字的顺序是否正确等,再或者它还会验证引号是否能前后正确的匹配。
- 预处理器则根据一些MySQL规则进一步检查解析树是否合法,例如,这里讲检查数据表和数据列是否存在,还会解析名字和别名,看看它们是否有歧义。下一步预处理器会验证权限,这通常很快,除非服务器上有非常多的权限设置
关于语法规则参考《编译原理》
查询优化器
现在语法树被认为合法的了,并且由优化器将其转化为执行计划。一条查询可以由很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
将语法树->执行计划的过程,可理解成《编译原理-语义分析》。mysql优化器在翻译过程中会结合相关表的实际情况进行基于成本估算。最终选择成本最小的一个。
查询执行引擎
在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎则根据这个执行计划来完成整个查询。相对于查询优化阶段,查询执行阶段不是那么复杂:MySQL只是简单的根据执行计划给出的指令逐步执行。在根据执行计划逐步执行的过程中,有大量的操作需要通过调用存储引擎实现的接口来完成,这些接口就是我们称为“handler API”的接口。实际上,MySQL在优化阶段就为每个表创建了一个handler实例,优化器根据这些实例的接口可以获取表的相关信息,包括表的所有列名、索引统计信息等。
返回结果给客户端
查询执行的最后一个阶段是将结果返回给客户端。
- 即使查询不需要返回结果给客户端,MySQL仍然会返回这个查询的一些信息,如查询影响到的行数。
- 如果查询可以被缓存,那么MySQL在这个阶段,会将结果存放到查询缓存中。
- MySQL将结果返回客户端是一个增量、逐步返回的过程。例如,在关联表操作时,一旦服务器处理完最后一个关联表,开始生成第一条结果时,MySQL就可以开始向客户端逐步返回结果集了。这样处理有两个好处:
- 服务器无需存储太多的结果,也就不会因为要返回太多的结果而消耗太多的内存。
- 这样的处理也让MySQL客户端第一时间获得返回的结果。
结果集中的每一行都会以一个满足MySQL客户端/服务器通信协议的封包发送,再通过TCP协议进行传输,在TCP传输过程中,可能对MySQL的封包进行缓存然后批量传输。
优化器详解
sql的执行顺序
想要了解优化器如何工解,基核心思想是先要读懂sql是如何执行的。
sql是按照固定的顺序解析的,主要的作用就是从上一个阶段的执行返回结果来提供给下一阶段使用,sql在执行的过程中会有不同的临时中间表,一般是按照如下顺序:
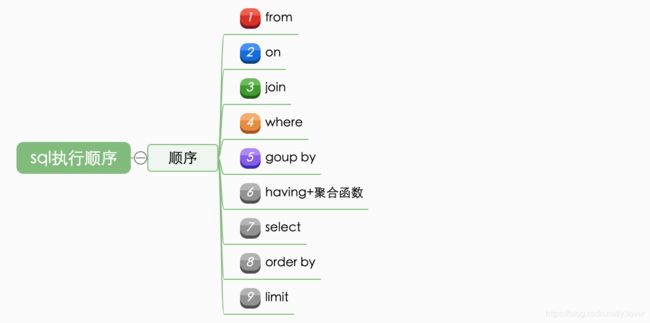
- 首先对from子句中的前两个表执行一个笛卡尔乘积,此时生成虚拟表 vt1
- 接下来便是应用on筛选器,on 中的逻辑表达式将应用到 vt1 中的各个行,筛选出满足on逻辑表达式的行,生成虚拟表 vt2
- 如果是outer join 那么这一步就将添加外部行,left outer jion就把左表在第二步中过滤的添加进来,如果是right outer join 那么就将右表在第二步中过滤掉的行添加进来,这样生成虚拟表 vt3
- 如果 from 子句中的表数目多余两个表,那么就将vt3和第三个表连接从而计算笛卡尔乘积,生成虚拟表,该过程就是一个重复1-3的步骤,最终得到一个新的虚拟表 vt4。
- 应用where筛选器,对上一步生产的虚拟表引用where筛选器,生成虚拟表vt5
- group by 子句将中的唯一的值和聚合函数(count、sum、avg等)组合成为一组,得到虚拟表vt6。
- 应用having筛选器,生成vt7。
- 处理select子句。将vt7中的在select中出现的列筛选出来。生成vt8.
- 应用distinct子句,vt8中移除相同的行,生成vt9。
- 应用order by子句。按照order_by_condition排序vt10.
- 应用limit 子句。筛选前n行结果返回给请求者即用户。
此只是逻辑过程,mysql会对其中的操作优化使其等价。
多表连接的三种方式
表连接的方式多种多样,主要有以下三种。
Hash join 算法
hash join 算法先选一个小表,放入内存的 hash table,然后扫描另一个表,与 hash table 匹配出结果数据。当表太大,无法一次放入内存时,就分而治之,写入块文件,再对每个块文件走一遍正常时的流程。
## 例:查询人和国家信息
select
given_name, country_name
from
persons a join countries b
on a.country_id = b.id
- join的2个表根据表的统计信息,选择占空间小的那个表,不是行数少的,这里假设选择了 countries 表。
- 对 countries 表中每行的 join 字段值进行 hash 计算:hash(countries.country_id),把所有行都存放到 hash table中。

- 对 persons 表中每行中的 join 字段的值进行 hash 计算:hash(persons.country_id)。拿着计算结果到内存 hash table 中进行查找匹配。匹配成功的发给client.
这样就完成了整个 join 操作,每个表只扫描一次就可以了,扫描匹配时间也是恒定的,非常高效.
有比较大的表,无法全部加载到内存中?
- 把表中剩余数据分成多个块文件写到磁盘上,并保证每个块文件的大小都是适合可用内存的。
- 通过hash(countries.country_id)定位到哪个块,则调取块到内存
Sort merge join 算法
排序合并连接则要求两个排序了的数据集。它的优点是,不需要每一次匹配都从头读到尾。但它有些特别的场景:
- 一些操作要求排序,优化器会认为使用排序合并连接的成本更低,如果有索引的话,那么第一个数据集就能够避免使用排序。但是,第二个数据集不论有没有索引,都会要求排序。
- 连接条件是不等式,比如:<,<=,>或者>=,相对应的,哈希连接要求是等式条件
## 例:查询人和国家信息
select
given_name, country_name
from
persons a join countries b
on a.country_id = b.id
- 将persons,countries 表全扫描后排序。
| 行号 | persons表(a) | countries表(b) |
|---|---|---|
| 1 | 10 | 10 |
| 2 | 20 | 10 |
| 3 | 20 | 20 |
| 4 | 40 | 20 |
| 5 | 50 | 30 |
-
对persons,countries表,进行merge操作
- 数据库先读persons数据集的第一行10,然后去countries的表读第一行10,匹配到了输出。直到countries的表读第三行20, 因为20比10大,而且数据是排序了的,证明countries后面的数据都比20大,所以已经没有必要再往下读数据了。
- 接下来,数据库开始读persons的下一行数据20,然后开始读countries的数据,从上一次最后一个匹配的那一行开始(第三行是20),匹配到了输出。继续读下一行,直到读到30这一行的时候,发现不匹配了,数据库就停下来了。
- 接着,数据库开始读persons的下一行数据20,与上一行数据相等。直接拿上次数据相同的结果集记录。
- 接着,读persons的下一行,40,读countries的最后匹配的那一行(第五行是30)停止。
合理使用索引对于排序合并连接算法,可减少排序的步骤。
Nested Loop Join 算法
NLJ是通过两层循环,用第一张表做Outter Loop,第二张表做Inner Loop,Outter Loop的每一条记录跟Inner Loop的记录作比较,符合条件的就输出。而NLJ又有3种细分的算法:
Simple Nested Loop Join(SNLJ)
SNLJ就是两层循环全量扫描连接的两张表,得到符合条件的两条记录则输出,这也就是让两张表做笛卡尔积,比较次数是R * S,是比较暴力的算法,会比较耗时。
// 伪代码
for (r in R) {//R为驱动表
for (s in S) {//直接扫表遍历
if (r satisfy condition s) {
output <r, s>;
}
}
}
Index Nested Loop Join(INLJ)
INLJ是在SNLJ的基础上做了优化,通过连接条件确定可用的索引,在Inner Loop中扫描索引而不去扫描数据本身,从而提高Inner Loop的效率。
而INLJ也有缺点,就是如果扫描的索引是非聚簇索引,并且需要访问非索引的数据,会产生一个回表读取数据的操作,这就多了一次随机的I/O操作。
// 伪代码
for (r in R) {//R为驱动表
for (si in SIndex) {//在索引中取数据
if (r satisfy condition si) {
output <r, s>;//满足条件回表查
}
}
}
在MySQL5.6中,对INLJ的回表操作进行了优化,增加了Batched Key Access Join(批量索引访问的表关联方式)和Multi Range Read(mrr,多范围读取)特性,在join操作中缓存所需要的数据的rowid,再批量去获取其数据,把I/O从多次零散的操作优化为更少次数批量的操作,提高效率。
Block Nested Loop Join(BNLJ)
一般情况下,MySQL优化器在索引可用的情况下,会优先选择使用INLJ算法,但是在无索引可用,或者判断full scan可能比使用索引更快的情况下,还是不会选择使用过于粗暴的SNLJ算法。
这里就出现了BNLJ算法了,BNLJ在SNLJ的基础上使用了join buffer,会提前读取Inner Loop所需要的记录到buffer中,以提高Inner Loop的效率。
// 伪代码
for (r in R) {//R为驱动表
for (sbu in SBuffer) {//在缓存中取数据
if (r satisfy condition sbu) {
output <r, s>;
}
}
}
Mysql数据和索引统计
通过多表关联算法得知2个重要的信息。如何选择驱动表,如何选择索引是查询优化的关键的。
何谓驱动表?
指多表关联查询时,第一个被处理的表,亦可称之为基表,然后再使用此表的记录去关联其他表。
驱动表的选择遵循一个原则:在对最终结果集没影响的前提下,优先选择结果集最少的那张表作为驱动表。何为索引
简单的说就是新华字典的检字表,,可根据它快速定义数据页,关于Mysql索引具体信息查看《InnoDB存储引擎索引概述》。
所以MySQL生成查询计划的时候,需要向存储引擎获取相应的统计信息。
- 每个表或者索引有多少页面
- 每个表的索引基数
- 每个表的数据行
- 每个表的索引长度
- 每个表的索引布布
Mysql如何执行关联查询
选择驱动表,MySQL主要采用Nested Loop Join算法进行表关联。
- 在使用索引关联的情况下,有Index Nested-Loop join和Batched Key Access join两种算法;
- 在未使用索引关联的情况下,有Simple Nested-Loop join或Block Nested-Loop join两种算法;
如何选择驱动表
- left join 一般选左表
- right join 一般选右表
- inner join 一般选结果集少的表
每行查询字节数 * 预估的行数 = 预估结果集
预估的行数可根据EXPLAIN查询
EXPLAIN 结果中,第一行出现的表就是驱动表
驱动表的作用
驱动表对于Nested Loop Join是外层表,并不关注连接条件on的变化
- 驱动表
相当于单表查询,只有where没有on - 被关联表
- 对于left join和right join,把条件放在on上,如果被关联表没有匹配上,那么外表还是能放入结果集的;如果将条件放在where上,因为where是对关联后的结果做过滤,此时之前匹配的记录也会被筛选掉。
- 对于inner join, on和where的效果是一样的
关联的过程
结合《MySQL Explain详解》分析以下案例
create table a(a1 int primary key, a2 int ,index(a2)); --双字段都有索引
create table c(c1 int primary key, c2 int ,index(c2), c3 int); --双字段都有索引
create table b(b1 int primary key, b2 int); --有主键索引
insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
insert into b values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
insert into c values(1,1,1),(2,4,4),(3,6,6),(4,5,5),(5,3,3),(6,3,3),(7,2,2),(8,8,8),(9,5,5),(10,3,3);
EXPLAIN EXTENDED
select a1,b2,c2,c3 from a
left join b on a.a1=b.b2
left join c on a.a1=c.c2 and c.c2 < 6
where a.a1 > 1
计划视图:

查询视图:
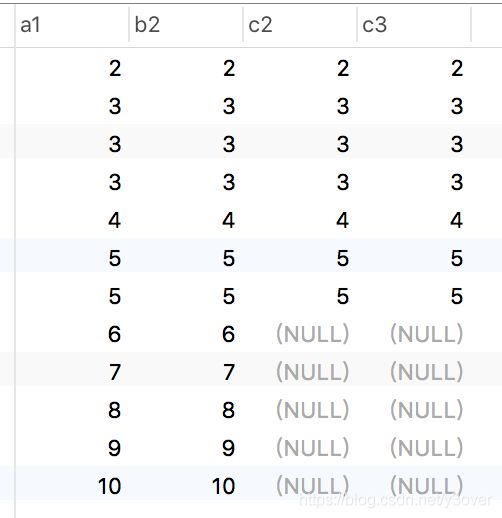
- 从计划视图得驱动表为a,
- 关注where中a1>1,通过PRIMARY索引过滤数据,根据Nested Loop Join 算法,取a>1的数据做为基表
- 查看计划视图第一张被关联表为b
- 关注on的条件,b2没有索引,采用Block Nested Loop Join关联两表,并把关联数据汇聚向基表中
- 查看计划视图第二张被关联表为c
- 关注on的条件,c2有索引,采用Index Nested Loop Join关联两表. c.c2 < 6的条件则把 c2>=6的全置为null,并将数据汇入基表
- 关联表的数据都是汇入到基表,因此后面 order by,group by 如果要用到索引,只可以用基表的索引
- on 后面语句发生在2表关联后执行,即使是和 a.a1 > 1 和基表相关的语句
- 在关系过程中一线表只能选择一个索引进行辅助
#给c表加个c2,c3的联合索引
EXPLAIN EXTENDED select c2,c3,count(1) from c
LEFT JOIN
(select a2 from a where a2 > 3) t
on c.c2 = t.a2
GROUP BY c2,c3
order by c2 asc
limit 3
计划视图为
![]()
完美的直接利用索引干完事情,没有回表的操作。如果GROUP BY ,
order by, on三者选择的索引不一致,就会出来回表查,文件排序的状
总结
- 了解了SQL的执行过程,表关联算法,及索引的作用。感觉写sql更真实
- 关于SQL优化,只能自己结合设计,表的数据量,产品的业务发展慢慢去分析了
- 如何优化分页《mysql LIMIT 子句用法及原理》
主要参考
《mysql 优化 explain 和show warnings 用法》
《MySQL8 的 Hash join 算法》
《SQL调优之六:排序合并连接(Sort Merge Joins)》
《Nested Loop Join》
《Mysql多表连接查询的执行细节一》
《Mysql多表连接查询的执行细节(二)》