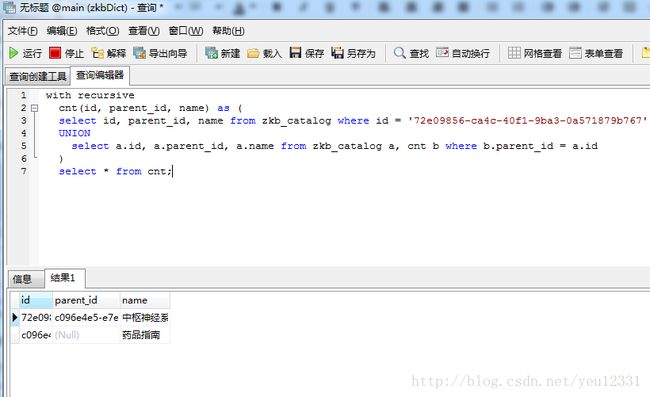
sqlite3-递归查询
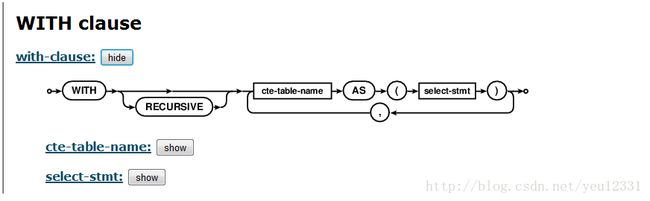
公共表表达式 或者叫CTES 就像是一张临时视图,仅仅在SQL语句执行期间存在。这里有两种公共表表达式,普通和递归。
普通公共表表达式通过拆分主SQL语句为一系列子句使得查询更容易理解。递归公共表表达式能够执行树或图的递归查询。
所有公用表表达式(普通和递归)是通过在一个SELECT,INSERT,DELETE或UPDATE语句前面的前面加上一个WITH子句创建的。
一个单一的WITH子句可以指定一个或多个公用表表达式,其中有些是普通的,哪些部分是递归的。
普通公用表表达式
一个普通的公用表表达式的工作原理就好像它一张在sql执行期间存在的临时视图。
普通公用表表达式利用分解出的子查询,使整个SQL语句更容易阅读和理解非常有用。
WITH子句可以包含普通的公用表表达式,即使它包含递归关键字。使用递归关键字并不强制公用表表达式是递归使用。
递归公用表表达式
递归公用表表达式可以用来编写遍历树或图形的查询。递归公用表表达式与普通的公用表表达式一样,具有相同的基本语法,但具有以下附加功能:
1.“选择-stmt的”必须是一个复合查询,其中最右边的复合操作符要么是UNION,或者是UNION ALL。
2.在AS关键字的左边,被命名的表必须且只能出现在复合查询语句中最右边查询语句的FROM子句中,不能在其他地方使用。
换另一种方式,一个递归公共表表达式必须如以下所示:
普通公共表表达式通过拆分主SQL语句为一系列子句使得查询更容易理解。递归公共表表达式能够执行树或图的递归查询。
所有公用表表达式(普通和递归)是通过在一个SELECT,INSERT,DELETE或UPDATE语句前面的前面加上一个WITH子句创建的。
一个单一的WITH子句可以指定一个或多个公用表表达式,其中有些是普通的,哪些部分是递归的。
普通公用表表达式
一个普通的公用表表达式的工作原理就好像它一张在sql执行期间存在的临时视图。
普通公用表表达式利用分解出的子查询,使整个SQL语句更容易阅读和理解非常有用。
WITH子句可以包含普通的公用表表达式,即使它包含递归关键字。使用递归关键字并不强制公用表表达式是递归使用。
递归公用表表达式
递归公用表表达式可以用来编写遍历树或图形的查询。递归公用表表达式与普通的公用表表达式一样,具有相同的基本语法,但具有以下附加功能:
1.“选择-stmt的”必须是一个复合查询,其中最右边的复合操作符要么是UNION,或者是UNION ALL。
2.在AS关键字的左边,被命名的表必须且只能出现在复合查询语句中最右边查询语句的FROM子句中,不能在其他地方使用。
换另一种方式,一个递归公共表表达式必须如以下所示:

在一个递归公共表表达式里,递归表用CTE表名命名。在上面的递归公共表表达式示意图中,递归表必须且只能出现在递归查询的FROM子句里,不能
出现在initial-select或者the recursive-select,包括subqueries的任何地方。
初始查询可以是一个联合查询,但是它不能包含ORDER BY, LIMIT, OFFSET.
递归查询必须是一个简单查询,而不能是一个联合查询语句。递归查询允许包含ORDER BY, LIMIT, OFFSET.
执行递归查询表内容的基本算法如下:
1.执行初始查询并将查询结果放入一个队列;
2.如果队列不为空
1.从队列中提取一条记录;
2.将这条记录插入递归表;
3.假设刚刚被提取的记录是递归表中唯一一条记录,然后,运行递归查询,把所有结果放入队列
以上,基本过程可能被以下附加规则修改:
如果,用一个UNION操作符把初始查询和递归查询衔接起来,那么,仅仅当这条记录不在队列时,才将这条记录添加到队列中。重复的记录被丢弃,在加入队列之前。
即使在递归查询时,重复的队列已经从队列中提取出来,如果,操作符是UNION ALL,那么在初始查询和递归查询阶段产生的记录总是被添加到队列当中,即使他们存在重复。
判断记录是否重复,NULL值与另一个NULL值比较是相等的,和其他值比较是不相等的。
LIMIT子句,如果出现,判断递归表中记录的个数,一旦达到指定记录个数,递归停止。一个以0作为限制数值意味阒没有记录被添加到递归表。
一个负值意味着添加到递归表的记录个数是没有限制的。
OFFSET子句,如果出现,有一个正值N, 会阻止前N条记录添加到递归表中。前N条记录仍然被递归查询处理。只是他们不添加到递归表中。当所有OFFSET记录被跳过,才开始记录
记录个数,直到达到限制数值。
如果有ORDER BY子句出现,它会在步骤2a中,决定队列中记录被提取的顺序,如果没有ORDER BY, 那么在被提取的记录顺序是未定义的。在当前实现中,如果省略ORDER BY子句,队列是一个先进先出队列。
但是应用程序不应该依赖这一个事实,因为它可能会改变。
递归查询示例:
以下查询返回1到1000000之间的所有整数。
with recursive
cnt(x) as (values(1) union all select x+1 from cnt where x < 1000000)
select * from cnt;
思考这个查询是如何工作的,
初始查询首先运行和返回一个单一字段的单一记录1,这条记录被添加到队列中。
在步骤2a中,这条记录从队列中移出并添加到递归表中,
接着,执行递归查询。
按照步骤2c,将产生的单一记录2添加到队列中。这里队列仍然还有一条记录,因此步骤2继续重复。
记录2按照步骤2a和2c被提取并添加到递归表中,接着记录2被使用,就好像它是递归表中的全部内容,递归查询继续。结果产生一条记录3,并被添加到队列
这样重复999999次,直到最后队列中包含的记录为1000000,这条记录被提取和添加到递归表,但是,这次,where子句会引起递归查询返回结果无记录,因此队列
剩下为空和递归结束。
优化注意事项:
在上面的讨论中,如“插入行插入递归表”报表应在概念上理解,不能从字面上。
这听起来好像是SQLite的积累含有一百万行一个巨大的表,然后回去和扫描该表由上到下产生的结果。
实际的情况是,查询优化器认为,在“CNT”递归表值只使用一次。
从而各行被添加到递归表,该行被立即返回作为主SELECT语句的结果,然后丢弃。
SQLite不累积一百万行的临时表。很少的内存是需要运行上面的例子。
但是,如果例如曾使用UNION代替UNION ALL,那么SQLite的将不得不保持所有以前生成的内容,以检查重复。
出于这个原因,程序员应该努力利用一切,而不是UNION UNION,可行的情况下。
在以上讨论中,像插入记录到递归表中的语句应该在概念上理解,不能从字面上,它听起来就像是sqlite正在积累一张含有一百万行的巨大的表,
然后回去和从上到下扫描该表并产生结果,实际的情况是,查询优化器认为,在"cnt"递归表中的值仅仅被使用一次,因此,当一条记录被添加到递归表时,
记录直接作为主查询语句的结果返回,然后丢弃。sqlite不会累积一张一百万行的临时表。运行以上示例,只需很少的内存空间。无论怎么样,如果示例
使用UNION代替UNION ALL,然后sqlite不得不保留所有先前产生的记录内容,以检查是否重复。
因为这个原因,在可行情况下,程序员应该努力使用UNION ALL代替UNION.
对上面的例子做一些改变,如下:
with recursive
cnt(x) as (select 1 union all select x+1 from cnt limit 1000000)
select * from cnt;
这里有两个地方不同,初始查询用"SELECT 1"代替"VALUES(1)".但是这些只不过是利用不同的语句做相同的事。另一个不同的地方是递归结束通过一个LIMIT而不是
一个WHERE子句,使用LIMIT意味着当一百万行记录添加到递归表时(主查询执行返回,由于查询优化器),接着递归直接结束而不管在队列中还有多少条记录。
在一个更复杂的查询中,它有时是很难的,要保证where子句最终引起队列为空和递归中止,但是,LIMIT子句总是能会停止递归。如果递归记录的上界大小是已知的,
为安全起见,总是包含一个LIMIT子句是一个好的方式。
分层查询示例:
创建一张表,描述一个组织的成员以及组织内部的关系链
CREATE TABLE org(
name TEXT PRIMARY KEY,
boss TEXT REFERENCES org,
height INT,
-- other content omitted
);
在组织里的每个成员都有一个名字,所有的成员只有一个老板,也就是整个组织的最顶端,这个表的所有记录关系形成一个棵树。
这里有一个查询,计算ALICE组织部门中每个人的平均体重,包括ALICE
WITH RECURSIVE
works_for_alice(n) AS (
VALUES('Alice')
UNION
SELECT name FROM org, works_for_alice
WHERE org.boss=works_for_alice.n
)
SELECT avg(height) FROM org
WHERE org.name IN works_for_alice;
下面一个例子在一个WITH子句中,使用两个公共表表达式,以下表表示一个家庭树
CREATE TABLE family(
name TEXT PRIMARY KEY,
mom TEXT REFERENCES family,
dad TEXT REFERENCES family,
born DATETIME,
died DATETIME, -- NULL if still alive
-- other content
);
这个家庭表跟之前的组织表是相似的,除了每个成员都有两个父结点。我们想要知道ALICE所有健在的祖辈,从老到小。一个普通的公共表表达式,"parent_of",首先被定义
这个普通公共表表达式是一个视图,被用来查找每个人的所有父辈。普通公共表表达式在递归公共表表达式ancestor_of_alice中使用.
接着,递归公共表表达式在后面查询被使用:
WITH RECURSIVE
parent_of(name, parent) AS
(SELECT name, mom FROM family UNION SELECT name, dad FROM family),
ancestor_of_alice(name) AS
(SELECT parent FROM parent_of WHERE name='Alice'
UNION ALL
SELECT parent FROM parent_of JOIN ancestor_of_alice USING(name))
SELECT family.name FROM ancestor_of_alice, family
WHERE ancestor_of_alice.name=family.name
AND died IS NULL
ORDER BY born;
查询图表:
版本控制系统通常存储每个工程的变化版本,作为一个有向无环图,调用项目的每个版本签入,一次签入可能是0或者有很多的父节点。
大部分签入,除了第一次,有一个父节点,但是,在合并情况下时,一个签入可能有两,三个或者更多的父节点。跟踪签入的和它们发生的顺序的模式,
就像如下所示:
CREATE TABLE checkin(
id INTEGER PRIMARY KEY,
mtime INTEGER -- timestamp when this checkin occurred
);
CREATE TABLE derivedfrom(
xfrom INTEGER NOT NULL REFERENCES checkin, -- parent checkin
xto INTEGER NOT NULL REFERENCES checkin, -- derived checkin
PRIMARY KEY(xfrom,xto)
);
CREATE INDEX derivedfrom_back ON derivedfrom(xto,xfrom);
此图是无环图,我们假定每个孩子签入不超过其所有父节点的修改时间,但是,与前面的例子不同的是,这个图在任何两次签入之间的可能有多条不同长度的路径。
我们想要知道在时间线上最近的20次签入,对于签入"@BASELINE,(在整个DAG有成千上万个祖先)这个查询类似于使用Fossil版本控制系统,显示最近的N个签入。
示例: http://www.sqlite.org/src/timeline?p=trunk&n=30
WITH RECURSIVE
ancestor(id,mtime) AS (
SELECT id, mtime FROM checkin WHERE id=@BASELINE
UNION
SELECT derivedfrom.xfrom, checkin.mtime
FROM ancestor, derivedfrom, checkin
WHERE ancestor.id=derivedfrom.xto
AND checkin.id=derivedfrom.xfrom
ORDER BY checkin.mtime DESC
LIMIT 20
)
SELECT * FROM checkin JOIN ancestor USING(id);
在递归查询里按时间降序会使得查询执行得更快,通过防止它从很早之前合并签入的分支遍历。order by 使得递归查询把重点放在最近签入的记录上,刚好也是我们想要得到的。
如果在递归查询中没有使用order by, 一个可能是遍历所有成千上万的提交记录,按时间线重对它们进行排序。接着,返回前20条记录。在order by基础上建立一个优先级队列
使得递归查询首先查找最近的提交记录。允许使用LIMIT子句,使得查询范围限制在感兴趣的签入记录上。
通过使用ORDER BY,深度优先对比广度优先搜索遍历树,
ORDER BY子句的递归查询可以用来控制搜索树是否是深度优先或广度优先。为了说明这一点,我们将对上面示例中的ORG表进行一处修改,没有了Height列,
并且插入以下这些数据。
CREATE TABLE org(
name TEXT PRIMARY KEY,
boss TEXT REFERENCES org
) WITHOUT ROWID;
INSERT INTO org VALUES('Alice',NULL);
INSERT INTO org VALUES('Bob','Alice');
INSERT INTO org VALUES('Cindy','Alice');
INSERT INTO org VALUES('Dave','Bob');
INSERT INTO org VALUES('Emma','Bob');
INSERT INTO org VALUES('Fred','Cindy');
INSERT INTO org VALUES('Gail','Cindy');
这里有一个查询对树结构,采用深度优先策略
WITH RECURSIVE
under_alice(name,level) AS (
VALUES('Alice',0)
UNION ALL
SELECT org.name, under_alice.level+1
FROM org JOIN under_alice ON org.boss=under_alice.name
ORDER BY 2
)
SELECT substr('..........',1,level*3) || name FROM under_alice;
在“ORDER BY2”(即等同于“ORDER BY under_alice.level+1”)会导致组织结构图中更高层次的成员(用较小的“级别”的值)能够得到优先处理,造成了广度优先搜索。
输出结果为:
Alice
...Bob
...Cindy
......Dave
......Emma
......Fred
......Gail
但是,如果我们改变了ORDER BY子句添加“DESC”修饰符,这将导致在组织中较低层次(与较大的“级别”的值)优先处理,造成了深度优先搜索:
WITH RECURSIVE
under_alice(name,level) AS (
VALUES('Alice',0)
UNION ALL
SELECT org.name, under_alice.level+1
FROM org JOIN under_alice ON org.boss=under_alice.name
ORDER BY 2 DESC
)
SELECT substr('..........',1,level*3) || name FROM under_alice;
修改后的查询结果为:
Alice
...Bob
......Dave
......Emma
...Cindy
......Fred
......Gail
当在递归查询中省略OREDER BY时,队列就像是一个FIFO, 这造成了广度优先搜索
特殊的递归查询示例:
出现在initial-select或者the recursive-select,包括subqueries的任何地方。
初始查询可以是一个联合查询,但是它不能包含ORDER BY, LIMIT, OFFSET.
递归查询必须是一个简单查询,而不能是一个联合查询语句。递归查询允许包含ORDER BY, LIMIT, OFFSET.
执行递归查询表内容的基本算法如下:
1.执行初始查询并将查询结果放入一个队列;
2.如果队列不为空
1.从队列中提取一条记录;
2.将这条记录插入递归表;
3.假设刚刚被提取的记录是递归表中唯一一条记录,然后,运行递归查询,把所有结果放入队列
以上,基本过程可能被以下附加规则修改:
如果,用一个UNION操作符把初始查询和递归查询衔接起来,那么,仅仅当这条记录不在队列时,才将这条记录添加到队列中。重复的记录被丢弃,在加入队列之前。
即使在递归查询时,重复的队列已经从队列中提取出来,如果,操作符是UNION ALL,那么在初始查询和递归查询阶段产生的记录总是被添加到队列当中,即使他们存在重复。
判断记录是否重复,NULL值与另一个NULL值比较是相等的,和其他值比较是不相等的。
LIMIT子句,如果出现,判断递归表中记录的个数,一旦达到指定记录个数,递归停止。一个以0作为限制数值意味阒没有记录被添加到递归表。
一个负值意味着添加到递归表的记录个数是没有限制的。
OFFSET子句,如果出现,有一个正值N, 会阻止前N条记录添加到递归表中。前N条记录仍然被递归查询处理。只是他们不添加到递归表中。当所有OFFSET记录被跳过,才开始记录
记录个数,直到达到限制数值。
如果有ORDER BY子句出现,它会在步骤2a中,决定队列中记录被提取的顺序,如果没有ORDER BY, 那么在被提取的记录顺序是未定义的。在当前实现中,如果省略ORDER BY子句,队列是一个先进先出队列。
但是应用程序不应该依赖这一个事实,因为它可能会改变。
递归查询示例:
以下查询返回1到1000000之间的所有整数。
with recursive
cnt(x) as (values(1) union all select x+1 from cnt where x < 1000000)
select * from cnt;
思考这个查询是如何工作的,
初始查询首先运行和返回一个单一字段的单一记录1,这条记录被添加到队列中。
在步骤2a中,这条记录从队列中移出并添加到递归表中,
接着,执行递归查询。
按照步骤2c,将产生的单一记录2添加到队列中。这里队列仍然还有一条记录,因此步骤2继续重复。
记录2按照步骤2a和2c被提取并添加到递归表中,接着记录2被使用,就好像它是递归表中的全部内容,递归查询继续。结果产生一条记录3,并被添加到队列
这样重复999999次,直到最后队列中包含的记录为1000000,这条记录被提取和添加到递归表,但是,这次,where子句会引起递归查询返回结果无记录,因此队列
剩下为空和递归结束。
优化注意事项:
在上面的讨论中,如“插入行插入递归表”报表应在概念上理解,不能从字面上。
这听起来好像是SQLite的积累含有一百万行一个巨大的表,然后回去和扫描该表由上到下产生的结果。
实际的情况是,查询优化器认为,在“CNT”递归表值只使用一次。
从而各行被添加到递归表,该行被立即返回作为主SELECT语句的结果,然后丢弃。
SQLite不累积一百万行的临时表。很少的内存是需要运行上面的例子。
但是,如果例如曾使用UNION代替UNION ALL,那么SQLite的将不得不保持所有以前生成的内容,以检查重复。
出于这个原因,程序员应该努力利用一切,而不是UNION UNION,可行的情况下。
在以上讨论中,像插入记录到递归表中的语句应该在概念上理解,不能从字面上,它听起来就像是sqlite正在积累一张含有一百万行的巨大的表,
然后回去和从上到下扫描该表并产生结果,实际的情况是,查询优化器认为,在"cnt"递归表中的值仅仅被使用一次,因此,当一条记录被添加到递归表时,
记录直接作为主查询语句的结果返回,然后丢弃。sqlite不会累积一张一百万行的临时表。运行以上示例,只需很少的内存空间。无论怎么样,如果示例
使用UNION代替UNION ALL,然后sqlite不得不保留所有先前产生的记录内容,以检查是否重复。
因为这个原因,在可行情况下,程序员应该努力使用UNION ALL代替UNION.
对上面的例子做一些改变,如下:
with recursive
cnt(x) as (select 1 union all select x+1 from cnt limit 1000000)
select * from cnt;
这里有两个地方不同,初始查询用"SELECT 1"代替"VALUES(1)".但是这些只不过是利用不同的语句做相同的事。另一个不同的地方是递归结束通过一个LIMIT而不是
一个WHERE子句,使用LIMIT意味着当一百万行记录添加到递归表时(主查询执行返回,由于查询优化器),接着递归直接结束而不管在队列中还有多少条记录。
在一个更复杂的查询中,它有时是很难的,要保证where子句最终引起队列为空和递归中止,但是,LIMIT子句总是能会停止递归。如果递归记录的上界大小是已知的,
为安全起见,总是包含一个LIMIT子句是一个好的方式。
分层查询示例:
创建一张表,描述一个组织的成员以及组织内部的关系链
CREATE TABLE org(
name TEXT PRIMARY KEY,
boss TEXT REFERENCES org,
height INT,
-- other content omitted
);
在组织里的每个成员都有一个名字,所有的成员只有一个老板,也就是整个组织的最顶端,这个表的所有记录关系形成一个棵树。
这里有一个查询,计算ALICE组织部门中每个人的平均体重,包括ALICE
WITH RECURSIVE
works_for_alice(n) AS (
VALUES('Alice')
UNION
SELECT name FROM org, works_for_alice
WHERE org.boss=works_for_alice.n
)
SELECT avg(height) FROM org
WHERE org.name IN works_for_alice;
下面一个例子在一个WITH子句中,使用两个公共表表达式,以下表表示一个家庭树
CREATE TABLE family(
name TEXT PRIMARY KEY,
mom TEXT REFERENCES family,
dad TEXT REFERENCES family,
born DATETIME,
died DATETIME, -- NULL if still alive
-- other content
);
这个家庭表跟之前的组织表是相似的,除了每个成员都有两个父结点。我们想要知道ALICE所有健在的祖辈,从老到小。一个普通的公共表表达式,"parent_of",首先被定义
这个普通公共表表达式是一个视图,被用来查找每个人的所有父辈。普通公共表表达式在递归公共表表达式ancestor_of_alice中使用.
接着,递归公共表表达式在后面查询被使用:
WITH RECURSIVE
parent_of(name, parent) AS
(SELECT name, mom FROM family UNION SELECT name, dad FROM family),
ancestor_of_alice(name) AS
(SELECT parent FROM parent_of WHERE name='Alice'
UNION ALL
SELECT parent FROM parent_of JOIN ancestor_of_alice USING(name))
SELECT family.name FROM ancestor_of_alice, family
WHERE ancestor_of_alice.name=family.name
AND died IS NULL
ORDER BY born;
查询图表:
版本控制系统通常存储每个工程的变化版本,作为一个有向无环图,调用项目的每个版本签入,一次签入可能是0或者有很多的父节点。
大部分签入,除了第一次,有一个父节点,但是,在合并情况下时,一个签入可能有两,三个或者更多的父节点。跟踪签入的和它们发生的顺序的模式,
就像如下所示:
CREATE TABLE checkin(
id INTEGER PRIMARY KEY,
mtime INTEGER -- timestamp when this checkin occurred
);
CREATE TABLE derivedfrom(
xfrom INTEGER NOT NULL REFERENCES checkin, -- parent checkin
xto INTEGER NOT NULL REFERENCES checkin, -- derived checkin
PRIMARY KEY(xfrom,xto)
);
CREATE INDEX derivedfrom_back ON derivedfrom(xto,xfrom);
此图是无环图,我们假定每个孩子签入不超过其所有父节点的修改时间,但是,与前面的例子不同的是,这个图在任何两次签入之间的可能有多条不同长度的路径。
我们想要知道在时间线上最近的20次签入,对于签入"@BASELINE,(在整个DAG有成千上万个祖先)这个查询类似于使用Fossil版本控制系统,显示最近的N个签入。
示例: http://www.sqlite.org/src/timeline?p=trunk&n=30
WITH RECURSIVE
ancestor(id,mtime) AS (
SELECT id, mtime FROM checkin WHERE id=@BASELINE
UNION
SELECT derivedfrom.xfrom, checkin.mtime
FROM ancestor, derivedfrom, checkin
WHERE ancestor.id=derivedfrom.xto
AND checkin.id=derivedfrom.xfrom
ORDER BY checkin.mtime DESC
LIMIT 20
)
SELECT * FROM checkin JOIN ancestor USING(id);
在递归查询里按时间降序会使得查询执行得更快,通过防止它从很早之前合并签入的分支遍历。order by 使得递归查询把重点放在最近签入的记录上,刚好也是我们想要得到的。
如果在递归查询中没有使用order by, 一个可能是遍历所有成千上万的提交记录,按时间线重对它们进行排序。接着,返回前20条记录。在order by基础上建立一个优先级队列
使得递归查询首先查找最近的提交记录。允许使用LIMIT子句,使得查询范围限制在感兴趣的签入记录上。
通过使用ORDER BY,深度优先对比广度优先搜索遍历树,
ORDER BY子句的递归查询可以用来控制搜索树是否是深度优先或广度优先。为了说明这一点,我们将对上面示例中的ORG表进行一处修改,没有了Height列,
并且插入以下这些数据。
CREATE TABLE org(
name TEXT PRIMARY KEY,
boss TEXT REFERENCES org
) WITHOUT ROWID;
INSERT INTO org VALUES('Alice',NULL);
INSERT INTO org VALUES('Bob','Alice');
INSERT INTO org VALUES('Cindy','Alice');
INSERT INTO org VALUES('Dave','Bob');
INSERT INTO org VALUES('Emma','Bob');
INSERT INTO org VALUES('Fred','Cindy');
INSERT INTO org VALUES('Gail','Cindy');
这里有一个查询对树结构,采用深度优先策略
WITH RECURSIVE
under_alice(name,level) AS (
VALUES('Alice',0)
UNION ALL
SELECT org.name, under_alice.level+1
FROM org JOIN under_alice ON org.boss=under_alice.name
ORDER BY 2
)
SELECT substr('..........',1,level*3) || name FROM under_alice;
在“ORDER BY2”(即等同于“ORDER BY under_alice.level+1”)会导致组织结构图中更高层次的成员(用较小的“级别”的值)能够得到优先处理,造成了广度优先搜索。
输出结果为:
Alice
...Bob
...Cindy
......Dave
......Emma
......Fred
......Gail
但是,如果我们改变了ORDER BY子句添加“DESC”修饰符,这将导致在组织中较低层次(与较大的“级别”的值)优先处理,造成了深度优先搜索:
WITH RECURSIVE
under_alice(name,level) AS (
VALUES('Alice',0)
UNION ALL
SELECT org.name, under_alice.level+1
FROM org JOIN under_alice ON org.boss=under_alice.name
ORDER BY 2 DESC
)
SELECT substr('..........',1,level*3) || name FROM under_alice;
修改后的查询结果为:
Alice
...Bob
......Dave
......Emma
...Cindy
......Fred
......Gail
当在递归查询中省略OREDER BY时,队列就像是一个FIFO, 这造成了广度优先搜索
特殊的递归查询示例:
向下递归查询示例:
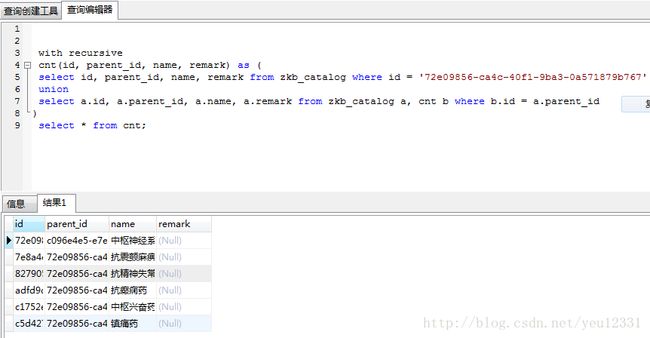
向上递归查询示例: