1. Tez简介
Tez是基于Hadoop Yarn之上的DAG(有向无环图,Directed Acyclic Graph)计算框架。它把Map/Reduce过程拆分成若干个子过程,同时可以把多个Map/Reduce任务组合成一个较大的DAG任务,减少了Map/Reduce之间的文件存储。同时合理组合其子过程,也可以减少任务的运行时间。
2. DAG计算模型
Map/Reduce不能解决所有问题,它适合在分布式环境中处理那些海量数据批处理计算程序,其计算模型主要分为两阶段:第一阶段为Map阶段,输出的是<Key, Value>Pair对;再进行数据的Shuffle和Sort;然进入第二阶段Reduce阶段,在这一阶段就是对对的计算逻辑处理。但是它无法更好地完成要求更高的计算任务,例如图计算中需要BSP迭代计算框架,要把上一个Map/Reduce任务的输出用于下一个Map/Reduce任务的输入;类似Hive和Pig的交互式有向图计算。DAG计算模型是针对Map/Reduce所遇问题而提出来的一种计算模型。下图是Map/Reduce模型与DAG模型的差别。
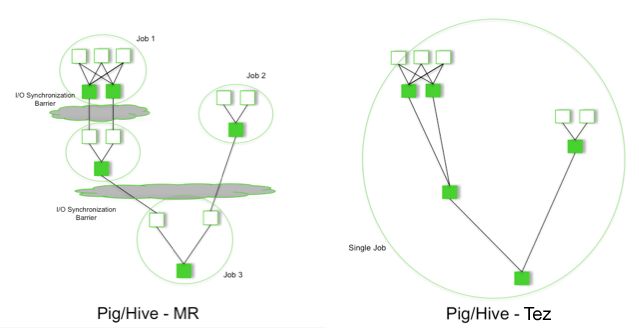
从图中可以看出:当采用Map/Reduce模型,我们处理一个大任务时需要四个Map/Reduce,那么就需要四个小Job来组合成一个大Job,这样会多几次的输入输出消耗。而采用Tez,它们形成一个大任务,这些子任务组合成一张DAG图,在数据的处理中间过程中,就没有往hdfs里面写数据,而是直接向它的后继节点输出数据。
3. Tez框架实现
在其中一篇技术博客Hadoop Yarn解决多类应用兼容方法讲到在Yarn上如何兼容各类应用的思路。在Hadoop Yarn上实现Hama BSP计算应用博文中讲解了如何在Yarn上开发出一个自己的应用。在这里,我将着重讲解在Tez应用的代码结构上,它是如何实现一个DAG计算模型。
从前面的博文中提到,对每个应用都需要去实现一个YARNRunner类去提交c对应的Job。在Tez里面,有一个这样的类org.apache.tez.mapreduce.YARNRunner。我们将以这个类为入口,讲解Tez的实现过程。
如下是Tez YARNRunner提交任务的实现代码。
@Override
public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts)
throws IOException, InterruptedException {
//与MR应用一样,先向RM获得一个applicationID。
ApplicationId appId = resMgrDelegate.getApplicationId();
FileSystem fs = FileSystem.get(conf);
// Loads the job.xml written by the user.
JobConf jobConf = new JobConf(new TezConfiguration(conf));
// Extract individual raw MR configs.
//为每个stage创建它自己的conf文件
Configuration[] stageConfs = MultiStageMRConfToTezTranslator
.getStageConfs(jobConf);
// Transform all confs to use Tez keys
MultiStageMRConfToTezTranslator.translateVertexConfToTez(stageConfs[0],
null);
for (int i = 1; i < stageConfs.length; i++) {
MultiStageMRConfToTezTranslator.translateVertexConfToTez(stageConfs[i],
stageConfs[i - 1]);
}
// create inputs to tezClient.submit()
// FIXME set up job resources
Map jobLocalResources =
createJobLocalResources(stageConfs[0], jobSubmitDir);
// FIXME createDAG should take the tezConf as a parameter, instead of using
// MR keys.
//创建它的一个DAG图
DAG dag = createDAG(fs, jobId, stageConfs, jobSubmitDir, ts,
jobLocalResources);
//略去...,创建一堆与Appmaster相关的conf配置,用于启动Tez的appmaster所用
// Submit to ResourceManager
try {
Path appStagingDir = fs.resolvePath(new Path(jobSubmitDir));
//向集群提交DAG任务
dagClient = tezClient.submitDAGApplication(
appId,
dag,
appStagingDir,
ts,
jobConf.get(JobContext.QUEUE_NAME,
YarnConfiguration.DEFAULT_QUEUE_NAME),
vargs,
environment,
jobLocalResources, dagAMConf);
} catch (TezException e) {
throw new IOException(e);
}
return getJobStatus(jobId);
}
上面的代码之中可以看出,它需要为该任务构造一个DAG图。下面是org.apache.tez.mapreduce.YARNRunner.createDAG(FileSystem, JobID, Configuration[], String, Credentials, Map)的源码实现。
private DAG createDAG(FileSystem fs, JobID jobId, Configuration[] stageConfs,
String jobSubmitDir, Credentials ts,
Map jobLocalResources) throws IOException {
//为DAG任务命名
String jobName = stageConfs[0].get(MRJobConfig.JOB_NAME,
YarnConfiguration.DEFAULT_APPLICATION_NAME);
DAG dag = new DAG(jobName);
LOG.info("Number of stages: " + stageConfs.length);
TaskLocationHint[] mapInputLocations = getMapLocationHintsFromInputSplits(
jobId, fs, stageConfs[0], jobSubmitDir);
TaskLocationHint[] reduceInputLocations = null;
// 各个子任务subtask的初始化
Vertex[] vertices = new Vertex[stageConfs.length]; //构造task节点
for (int i = 0; i < stageConfs.length; i++) {
vertices[i] = createVertexForStage(stageConfs[i], jobLocalResources,
i == 0 ? mapInputLocations : reduceInputLocations, i,
stageConfs.length);
}
for (int i = 0; i < vertices.length; i++) {
dag.addVertex(vertices[i]); //向dag中添加任务节点
if (i > 0) {
EdgeProperty edgeProperty = new EdgeProperty(
ConnectionPattern.BIPARTITE, SourceType.STABLE,
new OutputDescriptor(OnFileSortedOutput.class.getName(), null),
new InputDescriptor(ShuffledMergedInput.class.getName(), null));
Edge edge = null;
edge = new Edge(vertices[i - 1], vertices[i], edgeProperty);
dag.addEdge(edge); //向DAG图中添加边的属性
}
}
return dag;
}
大任务的DAG计算信息都存储在Vertex和Edge里面。我们将在这里详细分析Vertex和Edge的关系。
下面是向RM提交的任务信息,用于启动tez appmaster。appmaster的启动类为org.apache.tez.dag.app.DAGAppMaster。
private ApplicationSubmissionContext createApplicationSubmissionContext(
ApplicationId appId, DAG dag, Path appStagingDir, Credentials ts,
String amQueueName, String amName, List amArgs,
Map amEnv, Map amLocalResources,
TezConfiguration amConf) throws IOException, YarnException {
// 省略一些配置参数及方法(conf配置,环境变量classpath参数和appmaster Java命令)...
// emit protobuf DAG file style
Path binaryPath = new Path(appStagingDir,
TezConfiguration.TEZ_AM_PLAN_PB_BINARY + "." + appId.toString());
amConf.set(TezConfiguration.TEZ_AM_PLAN_REMOTE_PATH, binaryPath.toUri()
.toString());
Configuration finalAMConf = createFinalAMConf(amConf);
DAGPlan dagPB = dag.createDag(finalAMConf); //用dag构建一个DAGPlan作业计划
FSDataOutputStream dagPBOutBinaryStream = null;
try {
//binary output
dagPBOutBinaryStream = FileSystem.create(fs, binaryPath,
new FsPermission(TEZ_AM_FILE_PERMISSION));
dagPB.writeTo(dagPBOutBinaryStream); //并且写到硬盘上
} finally {
if(dagPBOutBinaryStream != null){
dagPBOutBinaryStream.close();
}
}
// 省略localResources的配置信息...
// Setup ContainerLaunchContext for AM container
ContainerLaunchContext amContainer =
ContainerLaunchContext.newInstance(localResources, environment,
vargsFinal, null, securityTokens, acls);
// Set up the ApplicationSubmissionContext
ApplicationSubmissionContext appContext = Records
.newRecord(ApplicationSubmissionContext.class);
appContext.setApplicationType(TezConfiguration.TEZ_APPLICATION_TYPE);
appContext.setApplicationId(appId);
appContext.setResource(capability);
appContext.setQueue(amQueueName);
appContext.setApplicationName(amName);
appContext.setCancelTokensWhenComplete(conf.getBoolean(
TezConfiguration.TEZ_AM_CANCEL_DELEGATION_TOKEN,
TezConfiguration.DEFAULT_TEZ_AM_CANCEL_DELEGATION_TOKEN));
appContext.setAMContainerSpec(amContainer);
return appContext;
}
4. Vertex & Edge
<续>
5. MapReduce
<续>